 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Channel Differential ASR for Robust Wearer Speech Recognition on Smart Glasses
Sep 17, 2025With the growing adoption of wearable devices such as smart glasses for AI assistants, wearer speech recognition (WSR) is becoming increasingly critical to next-generation human-computer interfaces. However, in real environments, interference from side-talk speech remains a significant challenge to WSR and may cause accumulated errors for downstream tasks such as natural language processing. In this work, we introduce a novel multi-channel differential automatic speech recognition (ASR) method for robust WSR on smart glasses. The proposed system takes differential inputs from different frontends that complement each other to improve the robustness of WSR, including a beamformer, microphone selection, and a lightweight side-talk detection model. Evaluations on both simulated and real datasets demonstrate that the proposed system outperforms the traditional approach, achieving up to an 18.0% relative reduction in word error rate.
Thinking in Directivity: Speech Large Language Model for Multi-Talker Directional Speech Recognition
Jun 17, 2025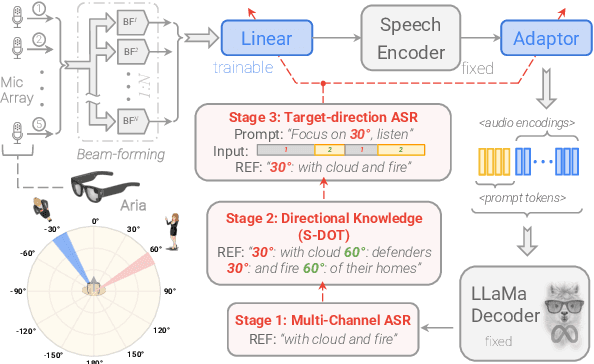
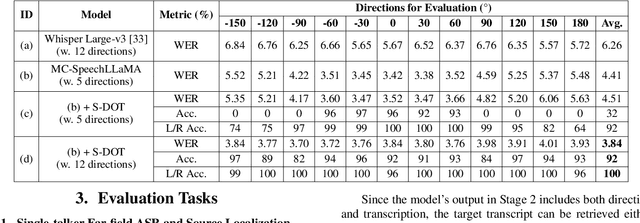
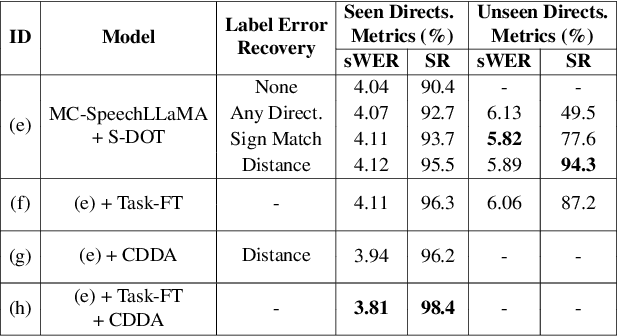
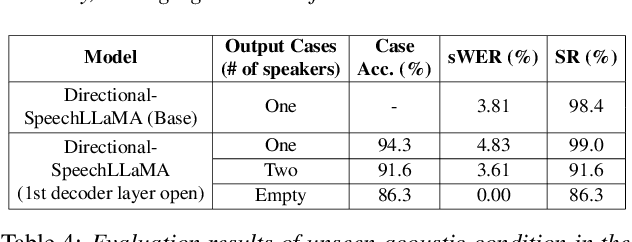
Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech recognition capabilities. However, the ability of Speech LLMs to comprehend and process multi-channel audio with spatial cues remains a relatively uninvestigated area of research. In this work, we present directional-SpeechLlama, a novel approach that leverages the microphone array of smart glasses to achieve directional speech recognition, source localization, and bystander cross-talk suppression. To enhance the model's ability to understand directivity, we propose two key techniques: serialized directional output training (S-DOT) and contrastive direction data augmentation (CDDA). Experimental results show that our proposed directional-SpeechLlama effectively captures the relationship between textual cues and spatial audio, yielding strong performance in both speech recognition and source localization tasks.
Effective Integration of KAN for Keyword Spotting
Sep 13, 2024Keyword spotting (KWS) is an important speech processing component for smart devices with voice assistance capability. In this paper, we investigate if Kolmogorov-Arnold Networks (KAN) can be used to enhance the performance of KWS. We explore various approaches to integrate KAN for a model architecture based on 1D Convolutional Neural Networks (CNN). We find that KAN is effective at modeling high-level features in lower-dimensional spaces, resulting in improved KWS performance when integrated appropriately. The findings shed light on understanding KAN for speech processing tasks and on other modalities for future researchers.
Query-by-Example Keyword Spotting Using Spectral-Temporal Graph Attentive Pooling and Multi-Task Learning
Aug 27, 2024



Existing keyword spotting (KWS) systems primarily rely on predefined keyword phrases. However, the ability to recognize customized keywords is crucial for tailoring interactions with intelligent devices. In this paper, we present a novel Query-by-Example (QbyE) KWS system that employs spectral-temporal graph attentive pooling and multi-task learning. This framework aims to effectively learn speaker-invariant and linguistic-informative embeddings for QbyE KWS tasks. Within this framework, we investigate three distinct network architectures for encoder modeling: LiCoNet, Conformer and ECAPA_TDNN. The experimental results on a substantial internal dataset of $629$ speakers have demonstrated the effectiveness of the proposed QbyE framework in maximizing the potential of simpler models such as LiCoNet. Particularly, LiCoNet, which is 13x more efficient, achieves comparable performance to the computationally intensive Conformer model (1.98% vs. 1.63\% FRR at 0.3 FAs/Hr).
Disentangled Training with Adversarial Examples For Robust Small-footprint Keyword Spotting
Aug 23, 2024



A keyword spotting (KWS) engine that is continuously running on device is exposed to various speech signals that are usually unseen before. It is a challenging problem to build a small-footprint and high-performing KWS model with robustness under different acoustic environments. In this paper, we explore how to effectively apply adversarial examples to improve KWS robustness. We propose datasource-aware disentangled learning with adversarial examples to reduce the mismatch between the original and adversarial data as well as the mismatch across original training datasources. The KWS model architecture is based on depth-wise separable convolution and a simple attention module. Experimental results demonstrate that the proposed learning strategy improves false reject rate by $40.31%$ at $1%$ false accept rate on the internal dataset, compared to the strongest baseline without using adversarial examples. Our best-performing system achieves $98.06%$ accuracy on the Google Speech Commands V1 dataset.
Handling the Alignment for Wake Word Detection: A Comparison Between Alignment-Based, Alignment-Free and Hybrid Approaches
Feb 17, 2023
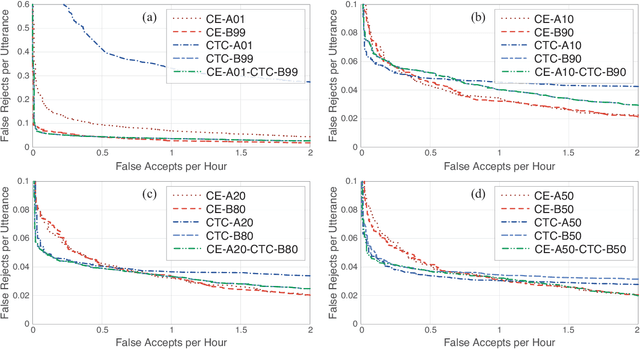
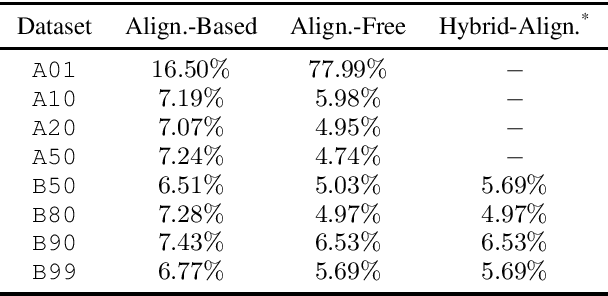

Wake word detection exists in most intelligent homes and portable devices. It offers these devices the ability to "wake up" when summoned at a low cost of power and computing. This paper focuses on understanding alignment's role in developing a wake-word system that answers a generic phrase. We discuss three approaches. The first is alignment-based, where the model is trained with frame-wise cross-entropy. The second is alignment-free, where the model is trained with CTC. The third, proposed by us, is a hybrid solution in which the model is trained with a small set of aligned data and then tuned with a sizeable unaligned dataset. We compare the three approaches and evaluate the impact of the different aligned-to-unaligned ratios for hybrid training. Our results show that the alignment-free system performs better alignment-based for the target operating point, and with a small fraction of the data (20%), we can train a model that complies with our initial constraints.
LiCo-Net: Linearized Convolution Network for Hardware-efficient Keyword Spotting
Nov 09, 2022



This paper proposes a hardware-efficient architecture, Linearized Convolution Network (LiCo-Net) for keyword spotting. It is optimized specifically for low-power processor units like microcontrollers. ML operators exhibit heterogeneous efficiency profiles on power-efficient hardware. Given the exact theoretical computation cost, int8 operators are more computation-effective than float operators, and linear layers are often more efficient than other layers. The proposed LiCo-Net is a dual-phase system that uses the efficient int8 linear operators at the inference phase and applies streaming convolutions at the training phase to maintain a high model capacity. The experimental results show that LiCo-Net outperforms single-value decomposition filter (SVDF) on hardware efficiency with on-par detection performance. Compared to SVDF, LiCo-Net reduces cycles by 40% on HiFi4 DSP.
AIPNet: Generative Adversarial Pre-training of Accent-invariant Networks for End-to-end Speech Recognition
Nov 27, 2019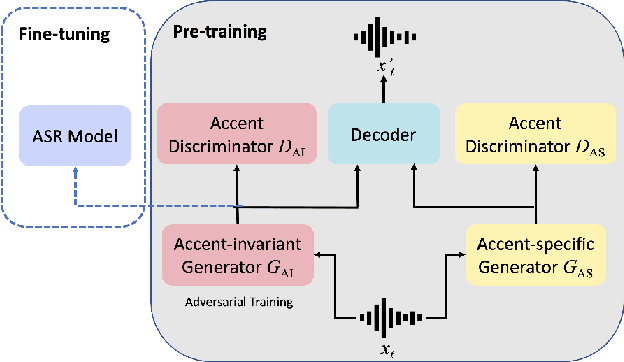
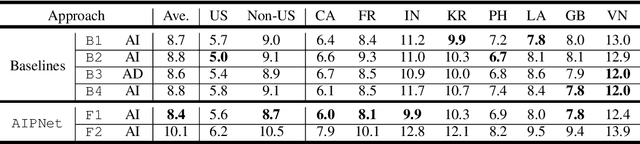
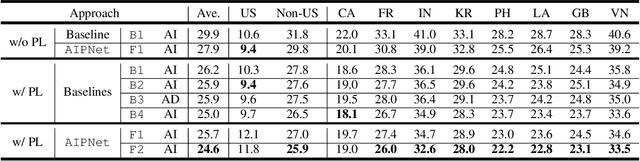
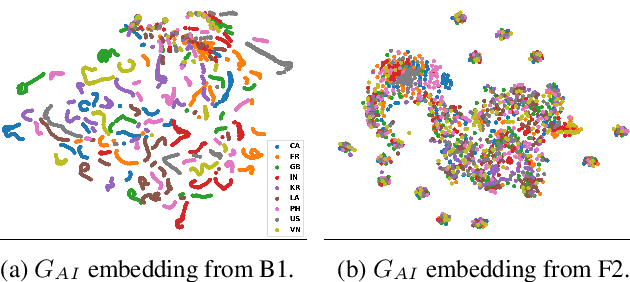
As one of the major sources in speech variability, accents have posed a grand challenge to the robustness of speech recognition systems. In this paper, our goal is to build a unified end-to-end speech recognition system that generalizes well across accents. For this purpose, we propose a novel pre-training framework AIPNet based on generative adversarial nets (GAN) for accent-invariant representation learning: Accent Invariant Pre-training Networks. We pre-train AIPNet to disentangle accent-invariant and accent-specific characteristics from acoustic features through adversarial training on accented data for which transcriptions are not necessarily available. We further fine-tune AIPNet by connecting the accent-invariant module with an attention-based encoder-decoder model for multi-accent speech recognition. In the experiments, our approach is compared against four baselines including both accent-dependent and accent-independent models. Experimental results on 9 English accents show that the proposed approach outperforms all the baselines by 2.3 \sim 4.5% relative reduction on average WER when transcriptions are available in all accents and by 1.6 \sim 6.1% relative reduction when transcriptions are only available in US accent.