 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Speech Naturalness Predictor
Mar 02, 2026Evaluation of conversational naturalness is essential for developing human-like speech agents. However, existing speech naturalness predictors are often designed to assess utterances from a single speaker, failing to capture conversation-level naturalness qualities. In this paper, we present a framework for an automatic naturalness predictor for two-speaker, multi-turn conversations. We first show that existing naturalness estimators have low, or sometimes even negative, correlations with conversational naturalness, based on conversational recordings annotated with human ratings. We then propose a dual-channel naturalness estimator, in which we investigate multiple pre-trained encoders with data augmentation. Our proposed model achieves substantially higher correlation with human judgments compared to existing naturalness predictors for both in-domain and out-of-domain conditions.
GSRM: Generative Speech Reward Model for Speech RLHF
Feb 14, 2026Recent advances in speech language models, such as GPT-4o Voice Mode and Gemini Live, have demonstrated promising speech generation capabilities. Nevertheless, the aesthetic naturalness of the synthesized audio still lags behind that of human speech. Enhancing generation quality requires a reliable evaluator of speech naturalness. However, existing naturalness evaluators typically regress raw audio to scalar scores, offering limited interpretability of the evaluation and moreover fail to generalize to speech across different taxonomies. Inspired by recent advances in generative reward modeling, we propose the Generative Speech Reward Model (GSRM), a reasoning-centric reward model tailored for speech. The GSRM is trained to decompose speech naturalness evaluation into an interpretable acoustic feature extraction stage followed by feature-grounded chain-of-thought reasoning, enabling explainable judgments. To achieve this, we curated a large-scale human feedback dataset comprising 31k expert ratings and an out-of-domain benchmark of real-world user-assistant speech interactions. Experiments show that GSRM substantially outperforms existing speech naturalness predictors, achieving model-human correlation of naturalness score prediction that approaches human inter-rater consistency. We further show how GSRM can improve the naturalness of speech LLM generations by serving as an effective verifier for online RLHF.
End-to-End Joint ASR and Speaker Role Diarization with Child-Adult Interactions
Jan 25, 2026Accurate transcription and speaker diarization of child-adult spoken interactions are crucial for developmental and clinical research. However, manual annotation is time-consuming and challenging to scale. Existing automated systems typically rely on cascaded speaker diarization and speech recognition pipelines, which can lead to error propagation. This paper presents a unified end-to-end framework that extends the Whisper encoder-decoder architecture to jointly model ASR and child-adult speaker role diarization. The proposed approach integrates: (i) a serialized output training scheme that emits speaker tags and start/end timestamps, (ii) a lightweight frame-level diarization head that enhances speaker-discriminative encoder representations, (iii) diarization-guided silence suppression for improved temporal precision, and (iv) a state-machine-based forced decoding procedure that guarantees structurally valid outputs. Comprehensive evaluations on two datasets demonstrate consistent and substantial improvements over two cascaded baselines, achieving lower multi-talker word error rates and demonstrating competitive diarization accuracy across both Whisper-small and Whisper-large models. These findings highlight the effectiveness and practical utility of the proposed joint modeling framework for generating reliable, speaker-attributed transcripts of child-adult interactions at scale. The code and model weights are publicly available
VoxCog: Towards End-to-End Multilingual Cognitive Impairment Classification through Dialectal Knowledge
Jan 12, 2026In this work, we present a novel perspective on cognitive impairment classification from speech by integrating speech foundation models that explicitly recognize speech dialects. Our motivation is based on the observation that individuals with Alzheimer's Disease (AD) or mild cognitive impairment (MCI) often produce measurable speech characteristics, such as slower articulation rate and lengthened sounds, in a manner similar to dialectal phonetic variations seen in speech. Building on this idea, we introduce VoxCog, an end-to-end framework that uses pre-trained dialect models to detect AD or MCI without relying on additional modalities such as text or images. Through experiments on multiple multilingual datasets for AD and MCI detection, we demonstrate that model initialization with a dialect classifier on top of speech foundation models consistently improves the predictive performance of AD or MCI. Our trained models yield similar or often better performance compared to previous approaches that ensembled several computational methods using different signal modalities. Particularly, our end-to-end speech-based model achieves 87.5% and 85.9% accuracy on the ADReSS 2020 challenge and ADReSSo 2021 challenge test sets, outperforming existing solutions that use multimodal ensemble-based computation or LLMs.
Joint ASR and Speaker Role Tagging with Serialized Output Training
Jun 12, 2025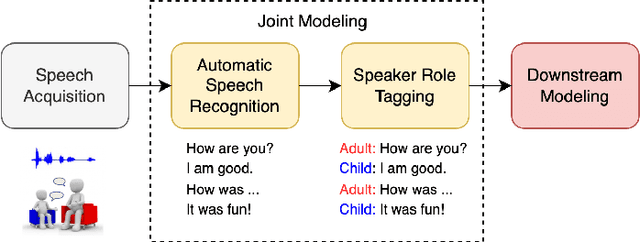
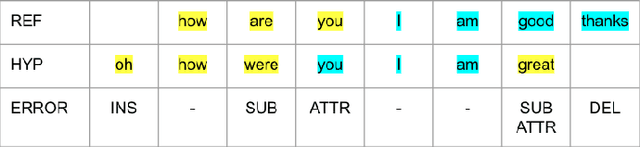

Automatic Speech Recognition systems have made significant progress with large-scale pre-trained models. However, most current systems focus solely on transcribing the speech without identifying speaker roles, a function that is critical for conversational AI. In this work, we investigate the use of serialized output training (SOT) for joint ASR and speaker role tagging. By augmenting Whisper with role-specific tokens and fine-tuning it with SOT, we enable the model to generate role-aware transcriptions in a single decoding pass. We compare the SOT approach against a self-supervised previous baseline method on two real-world conversational datasets. Our findings show that this approach achieves more than 10% reduction in multi-talker WER, demonstrating its feasibility as a unified model for speaker-role aware speech transcription.
Large Language Models based ASR Error Correction for Child Conversations
May 22, 2025
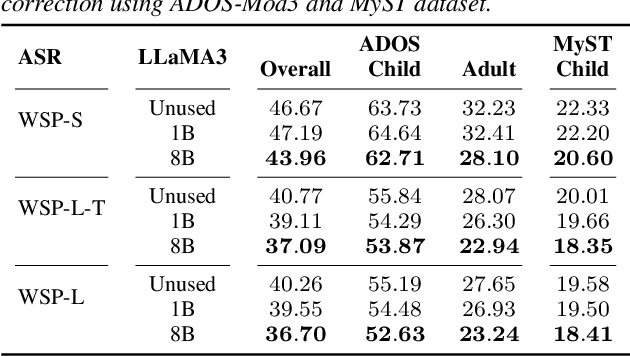


Automatic Speech Recognition (ASR) has recently shown remarkable progress, but accurately transcribing children's speech remains a significant challenge. Recent developments in Large Language Models (LLMs) have shown promise in improving ASR transcriptions. However, their applications in child speech including conversational scenarios are underexplored. In this study, we explore the use of LLMs in correcting ASR errors for conversational child speech. We demonstrate the promises and challenges of LLMs through experiments on two children's conversational speech datasets with both zero-shot and fine-tuned ASR outputs. We find that while LLMs are helpful in correcting zero-shot ASR outputs and fine-tuned CTC-based ASR outputs, it remains challenging for LLMs to improve ASR performance when incorporating contextual information or when using fine-tuned autoregressive ASR (e.g., Whisper) outputs.
Vox-Profile: A Speech Foundation Model Benchmark for Characterizing Diverse Speaker and Speech Traits
May 20, 2025We introduce Vox-Profile, a comprehensive benchmark to characterize rich speaker and speech traits using speech foundation models. Unlike existing works that focus on a single dimension of speaker traits, Vox-Profile provides holistic and multi-dimensional profiles that reflect both static speaker traits (e.g., age, sex, accent) and dynamic speech properties (e.g., emotion, speech flow). This benchmark is grounded in speech science and linguistics, developed with domain experts to accurately index speaker and speech characteristics. We report benchmark experiments using over 15 publicly available speech datasets and several widely used speech foundation models that target various static and dynamic speaker and speech properties. In addition to benchmark experiments, we showcase several downstream applications supported by Vox-Profile. First, we show that Vox-Profile can augment existing speech recognition datasets to analyze ASR performance variability. Vox-Profile is also used as a tool to evaluate the performance of speech generation systems. Finally, we assess the quality of our automated profiles through comparison with human evaluation and show convergent validity. Vox-Profile is publicly available at: https://github.com/tiantiaf0627/vox-profile-release.
Who Said What WSW 2.0? Enhanced Automated Analysis of Preschool Classroom Speech
May 15, 2025



This paper introduces an automated framework WSW2.0 for analyzing vocal interactions in preschool classrooms, enhancing both accuracy and scalability through the integration of wav2vec2-based speaker classification and Whisper (large-v2 and large-v3) speech transcription. A total of 235 minutes of audio recordings (160 minutes from 12 children and 75 minutes from 5 teachers), were used to compare system outputs to expert human annotations. WSW2.0 achieves a weighted F1 score of .845, accuracy of .846, and an error-corrected kappa of .672 for speaker classification (child vs. teacher). Transcription quality is moderate to high with word error rates of .119 for teachers and .238 for children. WSW2.0 exhibits relatively high absolute agreement intraclass correlations (ICC) with expert transcriptions for a range of classroom language features. These include teacher and child mean utterance length, lexical diversity, question asking, and responses to questions and other utterances, which show absolute agreement intraclass correlations between .64 and .98. To establish scalability, we apply the framework to an extensive dataset spanning two years and over 1,592 hours of classroom audio recordings, demonstrating the framework's robustness for broad real-world applications. These findings highlight the potential of deep learning and natural language processing techniques to revolutionize educational research by providing accurate measures of key features of preschool classroom speech, ultimately guiding more effective intervention strategies and supporting early childhood language development.
Can Generic LLMs Help Analyze Child-adult Interactions Involving Children with Autism in Clinical Observation?
Nov 16, 2024



Large Language Models (LLMs) have shown significant potential in understanding human communication and interaction. However, their performance in the domain of child-inclusive interactions, including in clinical settings, remains less explored. In this work, we evaluate generic LLMs' ability to analyze child-adult dyadic interactions in a clinically relevant context involving children with ASD. Specifically, we explore LLMs in performing four tasks: classifying child-adult utterances, predicting engaged activities, recognizing language skills and understanding traits that are clinically relevant. Our evaluation shows that generic LLMs are highly capable of analyzing long and complex conversations in clinical observation sessions, often surpassing the performance of non-expert human evaluators. The results show their potential to segment interactions of interest, assist in language skills evaluation, identify engaged activities, and offer clinical-relevant context for assessments.
Egocentric Speaker Classification in Child-Adult Dyadic Interactions: From Sensing to Computational Modeling
Sep 14, 2024
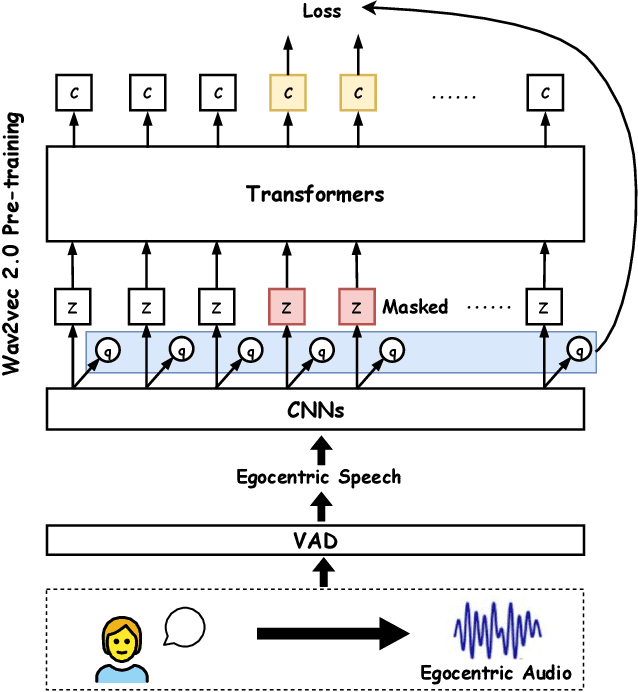
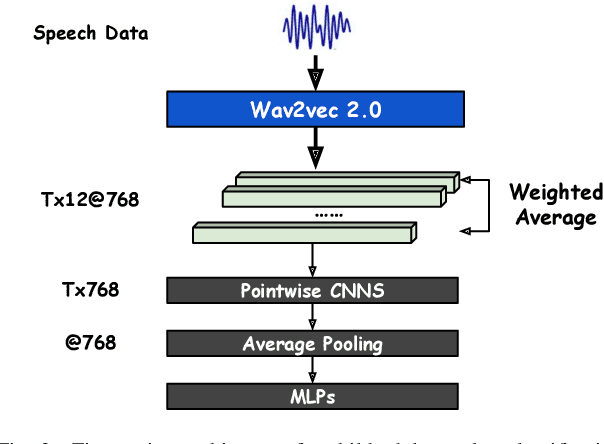
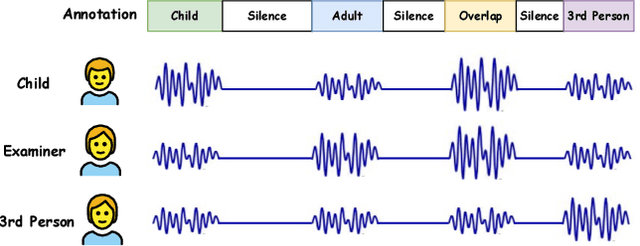
Autism spectrum disorder (ASD) is a neurodevelopmental condition characterized by challenges in social communication, repetitive behavior, and sensory processing. One important research area in ASD is evaluating children's behavioral changes over time during treatment. The standard protocol with this objective is BOSCC, which involves dyadic interactions between a child and clinicians performing a pre-defined set of activities. A fundamental aspect of understanding children's behavior in these interactions is automatic speech understanding, particularly identifying who speaks and when. Conventional approaches in this area heavily rely on speech samples recorded from a spectator perspective, and there is limited research on egocentric speech modeling. In this study, we design an experiment to perform speech sampling in BOSCC interviews from an egocentric perspective using wearable sensors and explore pre-training Ego4D speech samples to enhance child-adult speaker classification in dyadic interactions. Our findings highlight the potential of egocentric speech collection and pre-training to improve speaker classification accuracy.