 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Codec Probing from Semantic and Phonetic Perspectives
Mar 11, 2026Speech tokenizers are essential for connecting speech to large language models (LLMs) in multimodal systems. These tokenizers are expected to preserve both semantic and acoustic information for downstream understanding and generation. However, emerging evidence suggests that what is termed "semantic" in speech representations does not align with text-derived semantics: a mismatch that can degrade multimodal LLM performance. In this paper, we systematically analyze the information encoded by several widely used speech tokenizers, disentangling their semantic and phonetic content through word-level probing tasks, layerwise representation analysis, and cross-modal alignment metrics such as CKA. Our results show that current tokenizers primarily capture phonetic rather than lexical-semantic structure, and we derive practical implications for the design of next-generation speech tokenization methods.
An Approach to Simultaneous Acquisition of Real-Time MRI Video, EEG, and Surface EMG for Articulatory, Brain, and Muscle Activity During Speech Production
Mar 05, 2026Speech production is a complex process spanning neural planning, motor control, muscle activation, and articulatory kinematics. While the acoustic speech signal is the most accessible product of the speech production act, it does not directly reveal its causal neurophysiological substrates. We present the first simultaneous acquisition of real-time (dynamic) MRI, EEG, and surface EMG, capturing several key aspects of the speech production chain: brain signals, muscle activations, and articulatory movements. This multimodal acquisition paradigm presents substantial technical challenges, including MRI-induced electromagnetic interference and myogenic artifacts. To mitigate these, we introduce an artifact suppression pipeline tailored to this tri-modal setting. Once fully developed, this framework is poised to offer an unprecedented window into speech neuroscience and insights leading to brain-computer interface advances.
Vox-Profile: A Speech Foundation Model Benchmark for Characterizing Diverse Speaker and Speech Traits
May 20, 2025We introduce Vox-Profile, a comprehensive benchmark to characterize rich speaker and speech traits using speech foundation models. Unlike existing works that focus on a single dimension of speaker traits, Vox-Profile provides holistic and multi-dimensional profiles that reflect both static speaker traits (e.g., age, sex, accent) and dynamic speech properties (e.g., emotion, speech flow). This benchmark is grounded in speech science and linguistics, developed with domain experts to accurately index speaker and speech characteristics. We report benchmark experiments using over 15 publicly available speech datasets and several widely used speech foundation models that target various static and dynamic speaker and speech properties. In addition to benchmark experiments, we showcase several downstream applications supported by Vox-Profile. First, we show that Vox-Profile can augment existing speech recognition datasets to analyze ASR performance variability. Vox-Profile is also used as a tool to evaluate the performance of speech generation systems. Finally, we assess the quality of our automated profiles through comparison with human evaluation and show convergent validity. Vox-Profile is publicly available at: https://github.com/tiantiaf0627/vox-profile-release.
Egocentric Speaker Classification in Child-Adult Dyadic Interactions: From Sensing to Computational Modeling
Sep 14, 2024
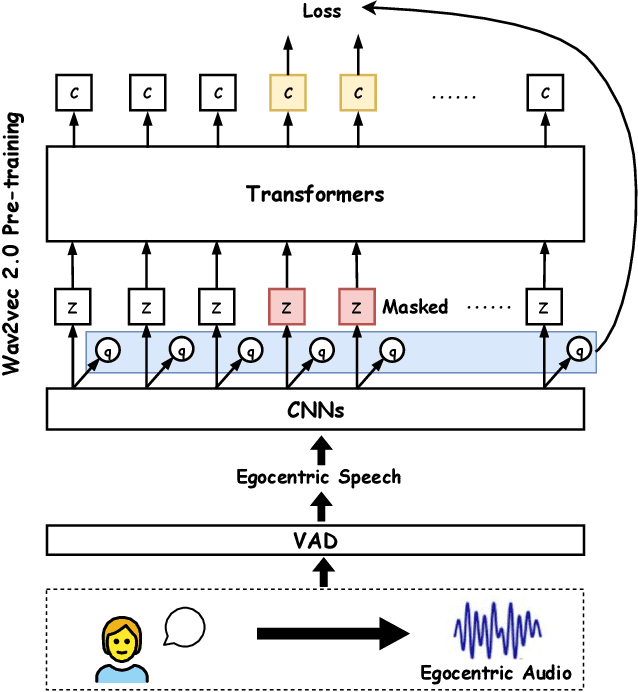
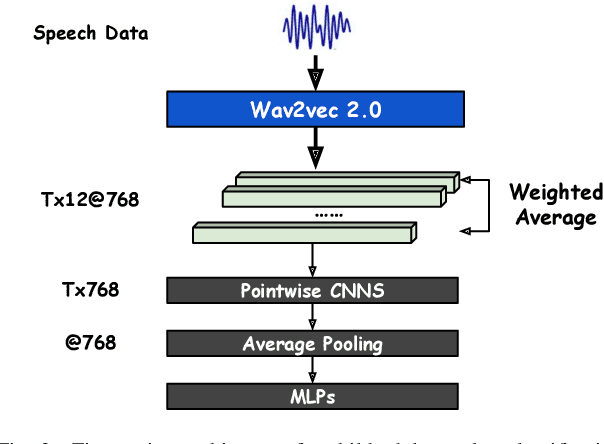
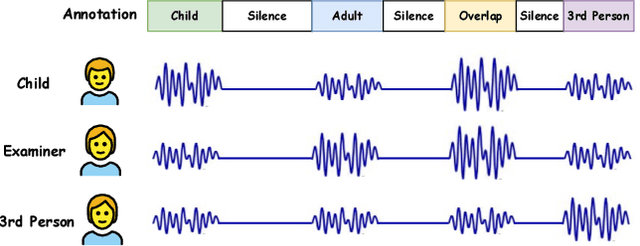
Autism spectrum disorder (ASD) is a neurodevelopmental condition characterized by challenges in social communication, repetitive behavior, and sensory processing. One important research area in ASD is evaluating children's behavioral changes over time during treatment. The standard protocol with this objective is BOSCC, which involves dyadic interactions between a child and clinicians performing a pre-defined set of activities. A fundamental aspect of understanding children's behavior in these interactions is automatic speech understanding, particularly identifying who speaks and when. Conventional approaches in this area heavily rely on speech samples recorded from a spectator perspective, and there is limited research on egocentric speech modeling. In this study, we design an experiment to perform speech sampling in BOSCC interviews from an egocentric perspective using wearable sensors and explore pre-training Ego4D speech samples to enhance child-adult speaker classification in dyadic interactions. Our findings highlight the potential of egocentric speech collection and pre-training to improve speaker classification accuracy.
Toward Fully-End-to-End Listened Speech Decoding from EEG Signals
Jun 12, 2024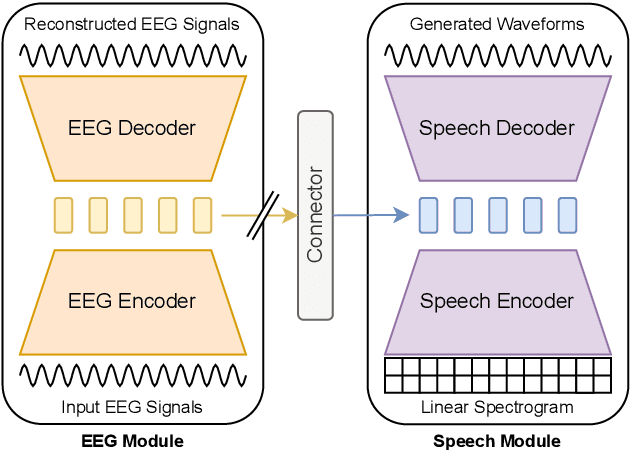



Speech decoding from EEG signals is a challenging task, where brain activity is modeled to estimate salient characteristics of acoustic stimuli. We propose FESDE, a novel framework for Fully-End-to-end Speech Decoding from EEG signals. Our approach aims to directly reconstruct listened speech waveforms given EEG signals, where no intermediate acoustic feature processing step is required. The proposed method consists of an EEG module and a speech module along with a connector. The EEG module learns to better represent EEG signals, while the speech module generates speech waveforms from model representations. The connector learns to bridge the distributions of the latent spaces of EEG and speech. The proposed framework is both simple and efficient, by allowing single-step inference, and outperforms prior works on objective metrics. A fine-grained phoneme analysis is conducted to unveil model characteristics of speech decoding. The source code is available here: github.com/lee-jhwn/fesde.
TI-ASU: Toward Robust Automatic Speech Understanding through Text-to-speech Imputation Against Missing Speech Modality
Apr 27, 2024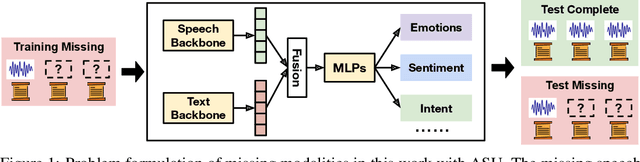

Automatic Speech Understanding (ASU) aims at human-like speech interpretation, providing nuanced intent, emotion, sentiment, and content understanding from speech and language (text) content conveyed in speech. Typically, training a robust ASU model relies heavily on acquiring large-scale, high-quality speech and associated transcriptions. However, it is often challenging to collect or use speech data for training ASU due to concerns such as privacy. To approach this setting of enabling ASU when speech (audio) modality is missing, we propose TI-ASU, using a pre-trained text-to-speech model to impute the missing speech. We report extensive experiments evaluating TI-ASU on various missing scales, both multi- and single-modality settings, and the use of LLMs. Our findings show that TI-ASU yields substantial benefits to improve ASU in scenarios where even up to 95% of training speech is missing. Moreover, we show that TI-ASU is adaptive to dropout training, improving model robustness in addressing missing speech during inference.
Unlocking Foundation Models for Privacy-Enhancing Speech Understanding: An Early Study on Low Resource Speech Training Leveraging Label-guided Synthetic Speech Content
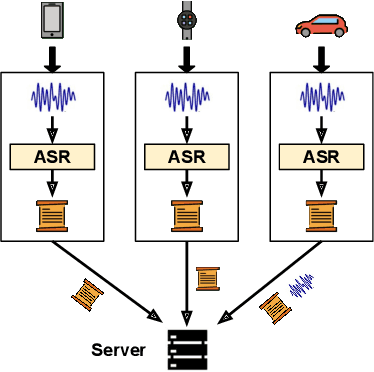
Jun 13, 2023Automatic Speech Understanding (ASU) leverages the power of deep learning models for accurate interpretation of human speech, leading to a wide range of speech applications that enrich the human experience. However, training a robust ASU model requires the curation of a large number of speech samples, creating risks for privacy breaches. In this work, we investigate using foundation models to assist privacy-enhancing speech computing. Unlike conventional works focusing primarily on data perturbation or distributed algorithms, our work studies the possibilities of using pre-trained generative models to synthesize speech content as training data with just label guidance. We show that zero-shot learning with training label-guided synthetic speech content remains a challenging task. On the other hand, our results demonstrate that the model trained with synthetic speech samples provides an effective initialization point for low-resource ASU training. This result reveals the potential to enhance privacy by reducing user data collection but using label-guided synthetic speech content.
A Review of Speech-centric Trustworthy Machine Learning: Privacy, Safety, and Fairness
Dec 18, 2022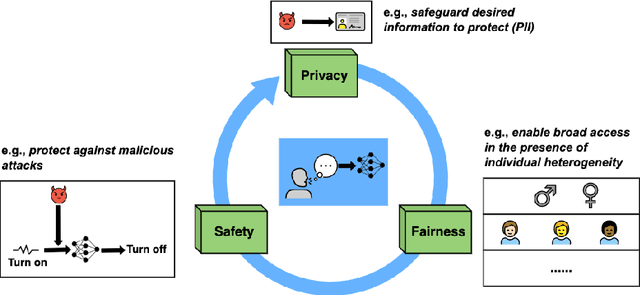
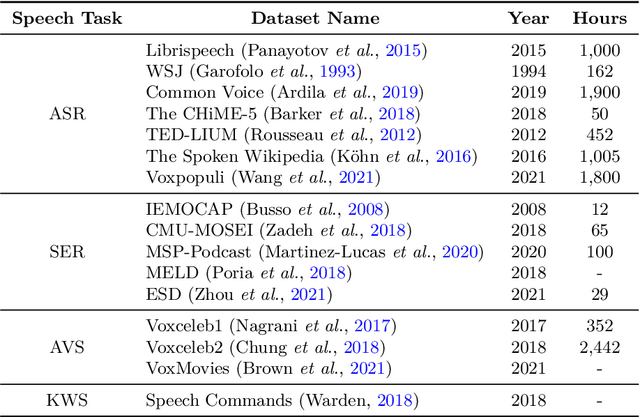
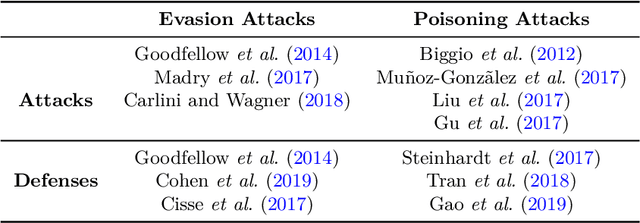
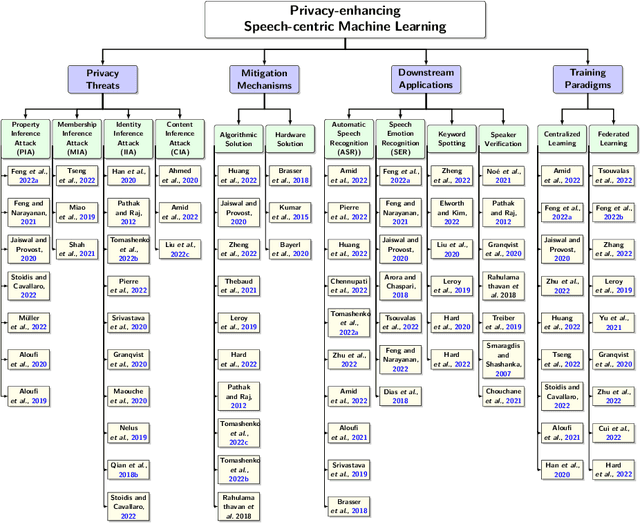
Speech-centric machine learning systems have revolutionized many leading domains ranging from transportation and healthcare to education and defense, profoundly changing how people live, work, and interact with each other. However, recent studies have demonstrated that many speech-centric ML systems may need to be considered more trustworthy for broader deployment. Specifically, concerns over privacy breaches, discriminating performance, and vulnerability to adversarial attacks have all been discovered in ML research fields. In order to address the above challenges and risks, a significant number of efforts have been made to ensure these ML systems are trustworthy, especially private, safe, and fair. In this paper, we conduct the first comprehensive survey on speech-centric trustworthy ML topics related to privacy, safety, and fairness. In addition to serving as a summary report for the research community, we point out several promising future research directions to inspire the researchers who wish to explore further in this area.
Can Knowledge of End-to-End Text-to-Speech Models Improve Neural MIDI-to-Audio Synthesis Systems?
Nov 25, 2022
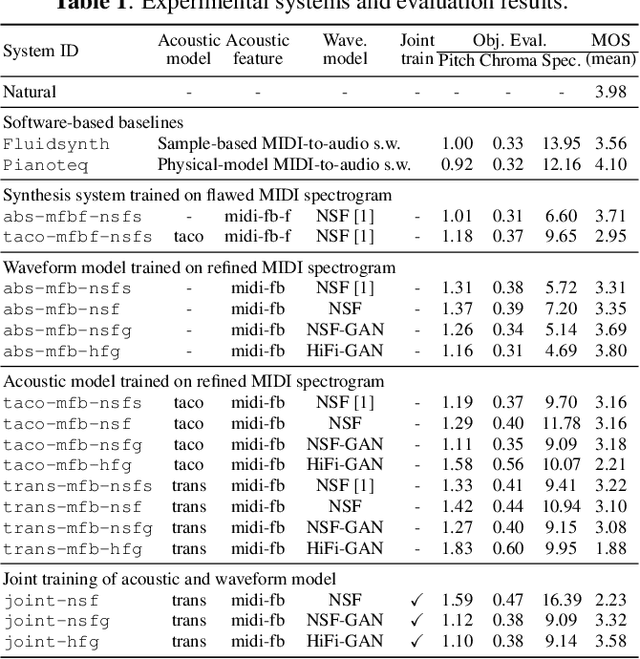
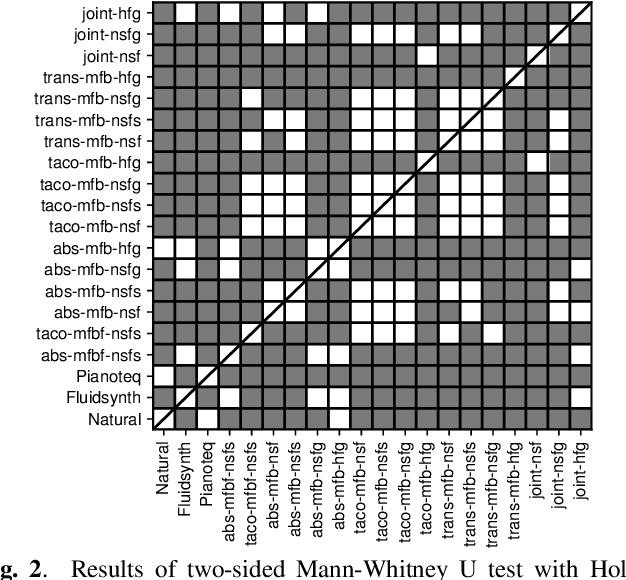

With the similarity between music and speech synthesis from symbolic input and the rapid development of text-to-speech (TTS) techniques, it is worthwhile to explore ways to improve the MIDI-to-audio performance by borrowing from TTS techniques. In this study, we analyze the shortcomings of a TTS-based MIDI-to-audio system and improve it in terms of feature computation, model selection, and training strategy, aiming to synthesize highly natural-sounding audio. Moreover, we conducted an extensive model evaluation through listening tests, pitch measurement, and spectrogram analysis. This work demonstrates not only synthesis of highly natural music but offers a thorough analytical approach and useful outcomes for the community. Our code and pre-trained models are open sourced at https://github.com/nii-yamagishilab/midi-to-audio.
Use of speaker recognition approaches for learning timbre representations of musical instrument sounds from raw waveforms
Jul 24, 2021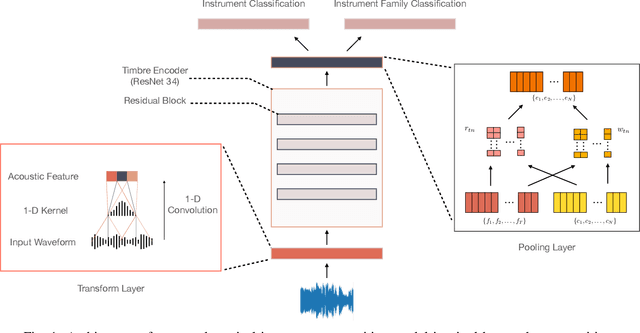
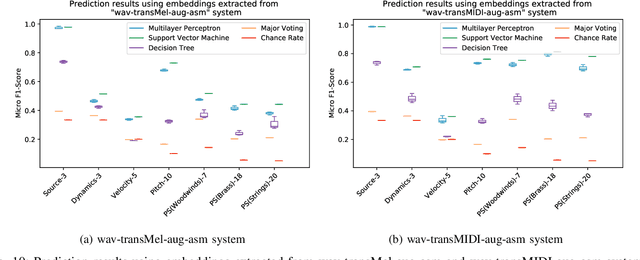
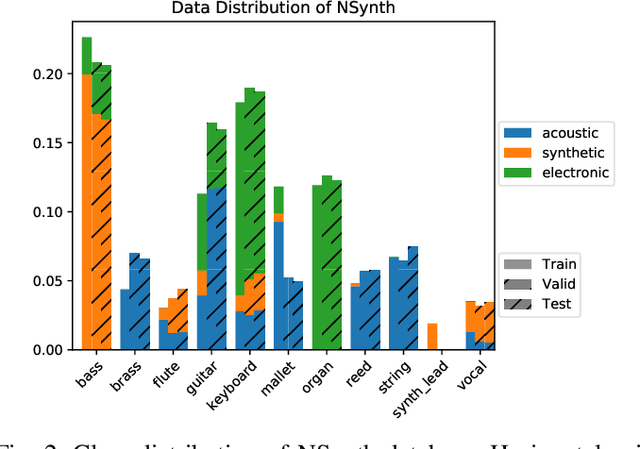
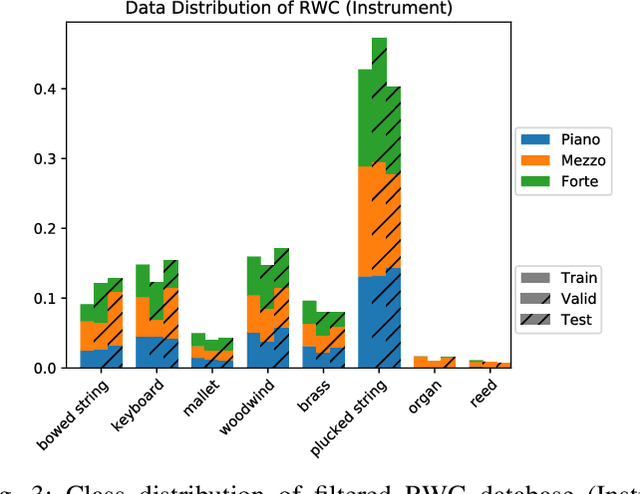
Timbre representations of musical instruments, essential for diverse applications such as musical audio synthesis and separation, might be learned as bottleneck features from an instrumental recognition model. Given the similarities between speaker recognition and musical instrument recognition, in this paper, we investigate how to adapt successful speaker recognition algorithms to musical instrument recognition to learn meaningful instrumental timbre representations. To address the mismatch between musical audio and models devised for speech, we introduce a group of trainable filters to generate proper acoustic features from input raw waveforms, making it easier for a model to be optimized in an input-agnostic and end-to-end manner. Through experiments on both the NSynth and RWC databases in both musical instrument closed-set identification and open-set verification scenarios, the modified speaker recognition model was capable of generating discriminative embeddings for instrument and instrument-family identities. We further conducted extensive experiments to characterize the encoded information in learned timbre embeddings.