 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Compact Attention For Few-shot Video-to-video Translation
Nov 30, 2020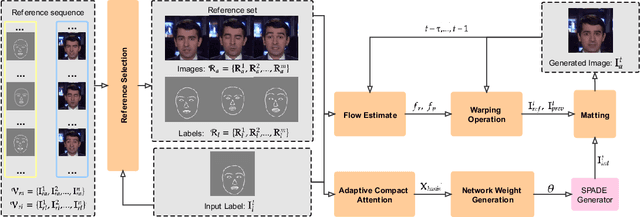
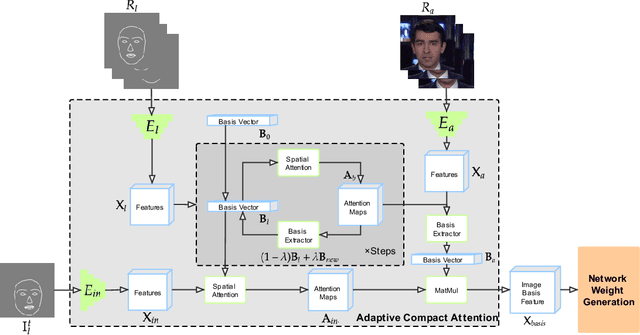

This paper proposes an adaptive compact attention model for few-shot video-to-video translation. Existing works in this domain only use features from pixel-wise attention without considering the correlations among multiple reference images, which leads to heavy computation but limited performance. Therefore, we introduce a novel adaptive compact attention mechanism to efficiently extract contextual features jointly from multiple reference images, of which encoded view-dependent and motion-dependent information can significantly benefit the synthesis of realistic videos. Our core idea is to extract compact basis sets from all the reference images as higher-level representations. To further improve the reliability, in the inference phase, we also propose a novel method based on the Delaunay Triangulation algorithm to automatically select the resourceful references according to the input label. We extensively evaluate our method on a large-scale talking-head video dataset and a human dancing dataset; the experimental results show the superior performance of our method for producing photorealistic and temporally consistent videos, and considerable improvements over the state-of-the-art method.
RepGN:Object Detection with Relational Proposal Graph Network
Apr 18, 2019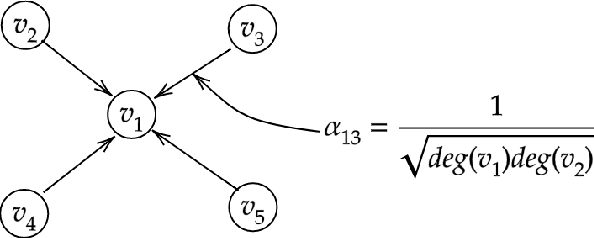
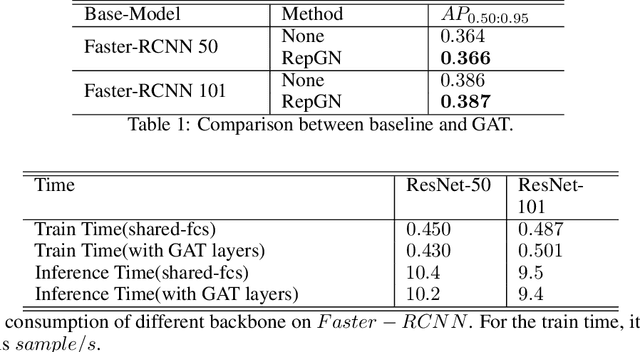
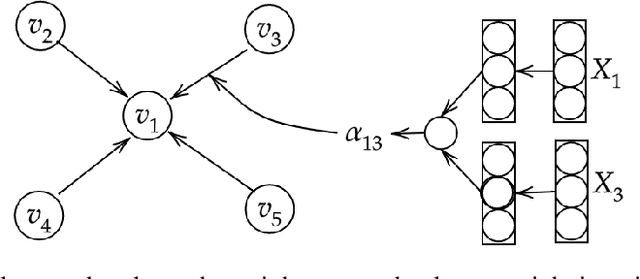
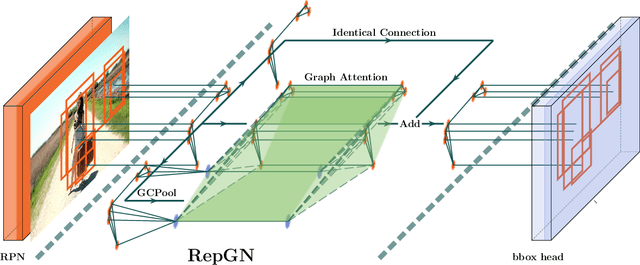
Region based object detectors achieve the state-of-the-art performance, but few consider to model the relation of proposals. In this paper, we explore the idea of modeling the relationships among the proposals for object detection from the graph learning perspective. Specifically, we present relational proposal graph network (RepGN) which is defined on object proposals and the semantic and spatial relation modeled as the edge. By integrating our RepGN module into object detectors, the relation and context constraints will be introduced to the feature extraction of regions and bounding boxes regression and classification. Besides, we propose a novel graph-cut based pooling layer for hierarchical coarsening of the graph, which empowers the RepGN module to exploit the inter-regional correlation and scene description in a hierarchical manner. We perform extensive experiments on COCO object detection dataset and show promising results.