 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Compact Attention For Few-shot Video-to-video Translation
Nov 30, 2020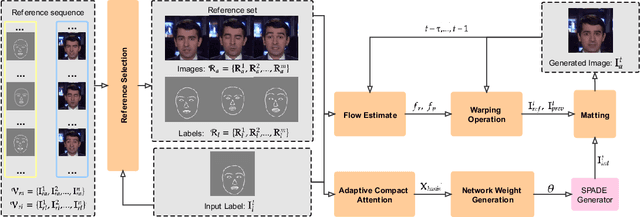
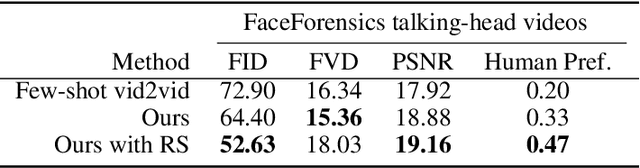
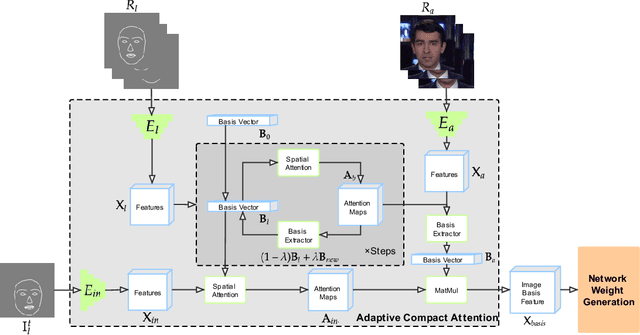

This paper proposes an adaptive compact attention model for few-shot video-to-video translation. Existing works in this domain only use features from pixel-wise attention without considering the correlations among multiple reference images, which leads to heavy computation but limited performance. Therefore, we introduce a novel adaptive compact attention mechanism to efficiently extract contextual features jointly from multiple reference images, of which encoded view-dependent and motion-dependent information can significantly benefit the synthesis of realistic videos. Our core idea is to extract compact basis sets from all the reference images as higher-level representations. To further improve the reliability, in the inference phase, we also propose a novel method based on the Delaunay Triangulation algorithm to automatically select the resourceful references according to the input label. We extensively evaluate our method on a large-scale talking-head video dataset and a human dancing dataset; the experimental results show the superior performance of our method for producing photorealistic and temporally consistent videos, and considerable improvements over the state-of-the-art method.
CPOT: Channel Pruning via Optimal Transport
May 21, 2020

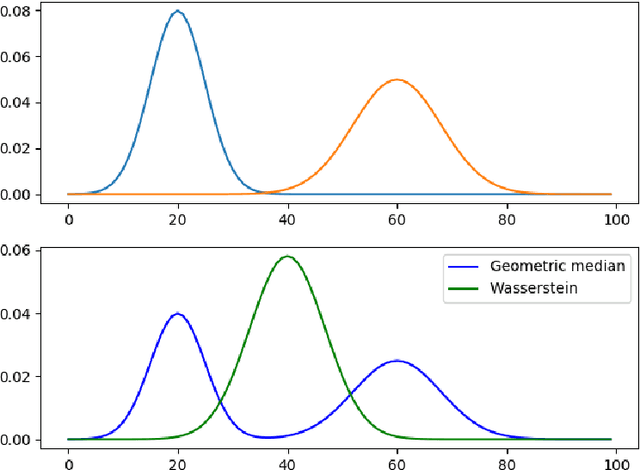
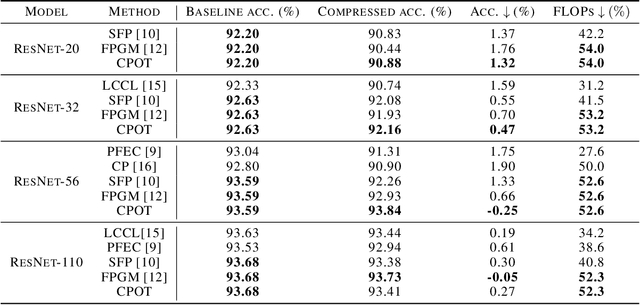
Recent advances in deep neural networks (DNNs) lead to tremendously growing network parameters, making the deployments of DNNs on platforms with limited resources extremely difficult. Therefore, various pruning methods have been developed to compress the deep network architectures and accelerate the inference process. Most of the existing channel pruning methods discard the less important filters according to well-designed filter ranking criteria. However, due to the limited interpretability of deep learning models, designing an appropriate ranking criterion to distinguish redundant filters is difficult. To address such a challenging issue, we propose a new technique of Channel Pruning via Optimal Transport, dubbed CPOT. Specifically, we locate the Wasserstein barycenter for channels of each layer in the deep models, which is the mean of a set of probability distributions under the optimal transport metric. Then, we prune the redundant information located by Wasserstein barycenters. At last, we empirically demonstrate that, for classification tasks, CPOT outperforms the state-of-the-art methods on pruning ResNet-20, ResNet-32, ResNet-56, and ResNet-110. Furthermore, we show that the proposed CPOT technique is good at compressing the StarGAN models by pruning in the more difficult case of image-to-image translation tasks.
Multi-Frame Content Integration with a Spatio-Temporal Attention Mechanism for Person Video Motion Transfer
Aug 12, 2019
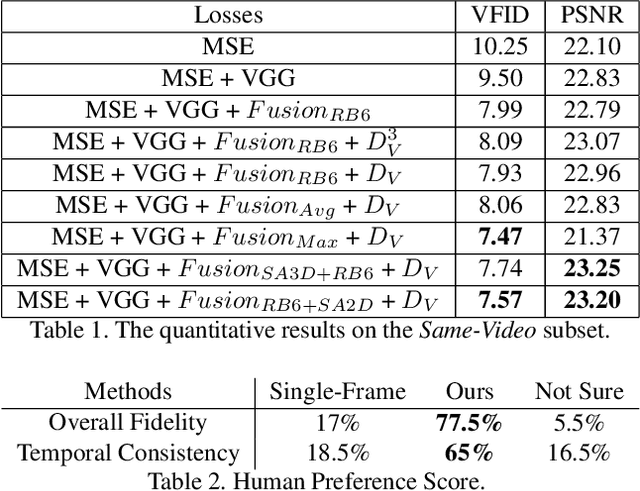
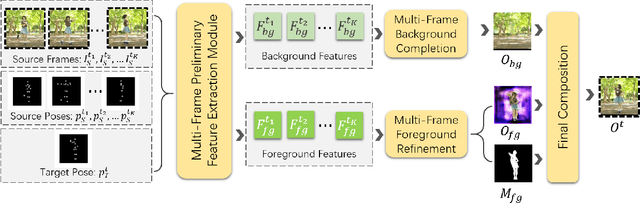
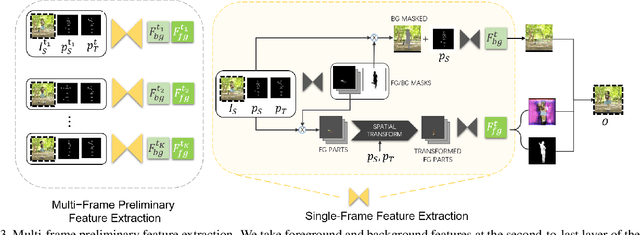
Existing person video generation methods either lack the flexibility in controlling both the appearance and motion, or fail to preserve detailed appearance and temporal consistency. In this paper, we tackle the problem of motion transfer for generating person videos, which provides controls on both the appearance and the motion. Specifically, we transfer the motion of one person in a target video to another person in a source video, while preserving the appearance of the source person. Besides only relying on one source frame as the existing state-of-the-art methods, our proposed method integrates information from multiple source frames based on a spatio-temporal attention mechanism to preserve rich appearance details. In addition to a spatial discriminator employed for encouraging the frame-level fidelity, a multi-range temporal discriminator is adopted to enforce the generated video to resemble temporal dynamics of a real video in various time ranges. A challenging real-world dataset, which contains about 500 dancing video clips with complex and unpredictable motions, is collected for the training and testing. Extensive experiments show that the proposed method can produce more photo-realistic and temporally consistent person videos than previous methods. As our method decomposes the syntheses of the foreground and background into two branches, a flexible background substitution application can also be achieved.
FaceShapeGene: A Disentangled Shape Representation for Flexible Face Image Editing
May 06, 2019

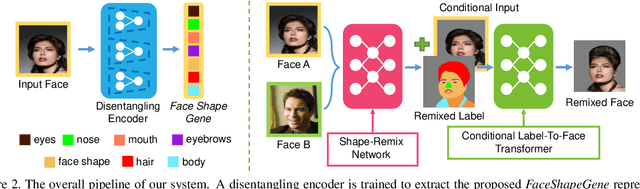

Existing methods for face image manipulation generally focus on editing the expression, changing some predefined attributes, or applying different filters. However, users lack the flexibility of controlling the shapes of different semantic facial parts in the generated face. In this paper, we propose an approach to compute a disentangled shape representation for a face image, namely the FaceShapeGene. The proposed FaceShapeGene encodes the shape information of each semantic facial part separately into a 1D latent vector. On the basis of the FaceShapeGene, a novel part-wise face image editing system is developed, which contains a shape-remix network and a conditional label-to-face transformer. The shape-remix network can freely recombine the part-wise latent vectors from different individuals, producing a remixed face shape in the form of a label map, which contains the facial characteristics of multiple subjects. The conditional label-to-face transformer, which is trained in an unsupervised cyclic manner, performs part-wise face editing while preserving the original identity of the subject. Experimental results on several tasks demonstrate that the proposed FaceShapeGene representation correctly disentangles the shape features of different semantic parts. %In addition, we test our system on several novel part-wise face editing tasks. Comparisons to existing methods demonstrate the superiority of the proposed method on accomplishing novel face editing tasks.