 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Frame Content Integration with a Spatio-Temporal Attention Mechanism for Person Video Motion Transfer
Aug 12, 2019
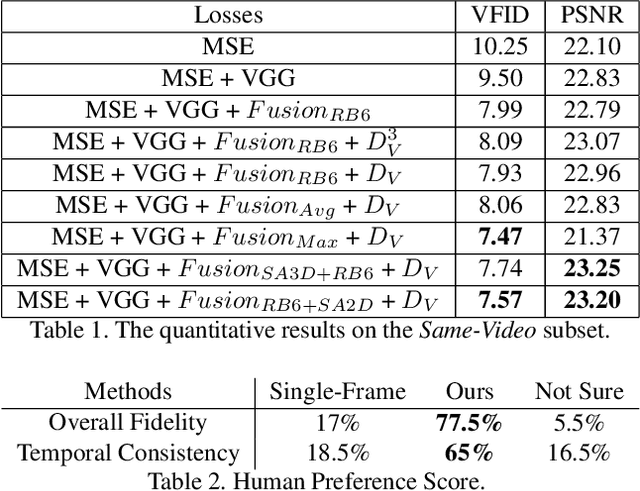
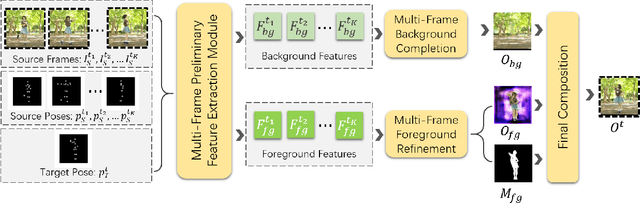
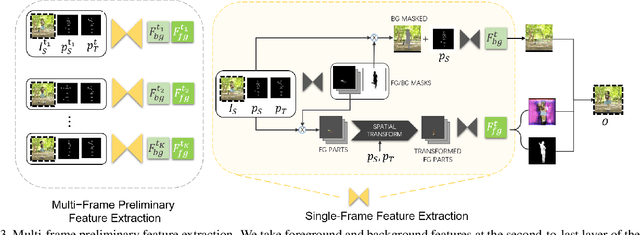
Existing person video generation methods either lack the flexibility in controlling both the appearance and motion, or fail to preserve detailed appearance and temporal consistency. In this paper, we tackle the problem of motion transfer for generating person videos, which provides controls on both the appearance and the motion. Specifically, we transfer the motion of one person in a target video to another person in a source video, while preserving the appearance of the source person. Besides only relying on one source frame as the existing state-of-the-art methods, our proposed method integrates information from multiple source frames based on a spatio-temporal attention mechanism to preserve rich appearance details. In addition to a spatial discriminator employed for encouraging the frame-level fidelity, a multi-range temporal discriminator is adopted to enforce the generated video to resemble temporal dynamics of a real video in various time ranges. A challenging real-world dataset, which contains about 500 dancing video clips with complex and unpredictable motions, is collected for the training and testing. Extensive experiments show that the proposed method can produce more photo-realistic and temporally consistent person videos than previous methods. As our method decomposes the syntheses of the foreground and background into two branches, a flexible background substitution application can also be achieved.