 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixal3D: Pixel-Aligned 3D Generation from Images
May 11, 2026Recent advances in 3D generative models have rapidly improved image-to-3D synthesis quality, enabling higher-resolution geometry and more realistic appearance. Yet fidelity, which measures pixel-level faithfulness of the generated 3D asset to the input image, still remains a central bottleneck. We argue this stems from an implicit 2D-3D correspondence issue: most 3D-native generators synthesize shape in canonical space and inject image cues via attention, leaving pixel-to-3D associations ambiguous. To tackle this issue, we draw inspiration from 3D reconstruction and propose Pixal3D, a pixel-aligned 3D generation paradigm for high-fidelity 3D asset creation from images. Instead of generating in a canonical pose, Pixal3D directly generates 3D in a pixel-aligned way, consistent with the input view. To enable this, we introduce a pixel back-projection conditioning scheme that explicitly lifts multi-scale image features into a 3D feature volume, establishing direct pixel-to-3D correspondence without ambiguity. We show that Pixal3D is not only scalable and capable of producing high-quality 3D assets, but also substantially improves fidelity, approaching the fidelity level of reconstruction. Furthermore, Pixal3D naturally extends to multi-view generation by aggregating back-projected feature volumes across views. Finally, we show pixel-aligned generation benefits scene synthesis, and present a modular pipeline that produces high-fidelity, object-separated 3D scenes from images. Pixal3D for the first time demonstrates 3D-native pixel-aligned generation at scale, and provides a new inspiring way towards high-fidelity 3D generation of object or scene from single or multi-view images. Project page: https://ldyang694.github.io/projects/pixal3d/
1%>100%: High-Efficiency Visual Adapter with Complex Linear Projection Optimization
Feb 11, 2026Deploying vision foundation models typically relies on efficient adaptation strategies, whereas conventional full fine-tuning suffers from prohibitive costs and low efficiency. While delta-tuning has proven effective in boosting the performance and efficiency of LLMs during adaptation, its advantages cannot be directly transferred to the fine-tuning pipeline of vision foundation models. To push the boundaries of adaptation efficiency for vision tasks, we propose an adapter with Complex Linear Projection Optimization (CoLin). For architecture, we design a novel low-rank complex adapter that introduces only about 1% parameters to the backbone. For efficiency, we theoretically prove that low-rank composite matrices suffer from severe convergence issues during training, and address this challenge with a tailored loss. Extensive experiments on object detection, segmentation, image classification, and rotated object detection (remote sensing scenario) demonstrate that CoLin outperforms both full fine-tuning and classical delta-tuning approaches with merely 1% parameters for the first time, providing a novel and efficient solution for deployment of vision foundation models. We release the code on https://github.com/DongshuoYin/CoLin.
Improving Variable-Length Generation in Diffusion Language Models via Length Regularization
Feb 07, 2026Diffusion Large Language Models (DLLMs) are inherently ill-suited for variable-length generation, as their inference is defined on a fixed-length canvas and implicitly assumes a known target length. When the length is unknown, as in realistic completion and infilling, naively comparing confidence across mask lengths becomes systematically biased, leading to under-generation or redundant continuations. In this paper, we show that this failure arises from an intrinsic lengthinduced bias in generation confidence estimates, leaving existing DLLMs without a robust way to determine generation length and making variablelength inference unreliable. To address this issue, we propose LR-DLLM, a length-regularized inference framework for DLLMs that treats generation length as an explicit variable and achieves reliable length determination at inference time. It decouples semantic compatibility from lengthinduced uncertainty through an explicit length regularization that corrects biased confidence estimates. Based on this, LR-DLLM enables dynamic expansion or contraction of the generation span without modifying the underlying DLLM or its training procedure. Experiments show that LRDLLM achieves 51.3% Pass@1 on HumanEvalInfilling under fully unknown lengths (+13.4% vs. DreamOn) and 51.5% average Pass@1 on four-language McEval (+14.3% vs. DreamOn).
Skin Tokens: A Learned Compact Representation for Unified Autoregressive Rigging
Feb 04, 2026The rapid proliferation of generative 3D models has created a critical bottleneck in animation pipelines: rigging. Existing automated methods are fundamentally limited by their approach to skinning, treating it as an ill-posed, high-dimensional regression task that is inefficient to optimize and is typically decoupled from skeleton generation. We posit this is a representation problem and introduce SkinTokens: a learned, compact, and discrete representation for skinning weights. By leveraging an FSQ-CVAE to capture the intrinsic sparsity of skinning, we reframe the task from continuous regression to a more tractable token sequence prediction problem. This representation enables TokenRig, a unified autoregressive framework that models the entire rig as a single sequence of skeletal parameters and SkinTokens, learning the complicated dependencies between skeletons and skin deformations. The unified model is then amenable to a reinforcement learning stage, where tailored geometric and semantic rewards improve generalization to complex, out-of-distribution assets. Quantitatively, the SkinTokens representation leads to a 98%-133% percents improvement in skinning accuracy over state-of-the-art methods, while the full TokenRig framework, refined with RL, enhances bone prediction by 17%-22%. Our work presents a unified, generative approach to rigging that yields higher fidelity and robustness, offering a scalable solution to a long-standing challenge in 3D content creation.
Beyond Inpainting: Unleash 3D Understanding for Precise Camera-Controlled Video Generation
Jan 15, 2026Camera control has been extensively studied in conditioned video generation; however, performing precisely altering the camera trajectories while faithfully preserving the video content remains a challenging task. The mainstream approach to achieving precise camera control is warping a 3D representation according to the target trajectory. However, such methods fail to fully leverage the 3D priors of video diffusion models (VDMs) and often fall into the Inpainting Trap, resulting in subject inconsistency and degraded generation quality. To address this problem, we propose DepthDirector, a video re-rendering framework with precise camera controllability. By leveraging the depth video from explicit 3D representation as camera-control guidance, our method can faithfully reproduce the dynamic scene of an input video under novel camera trajectories. Specifically, we design a View-Content Dual-Stream Condition mechanism that injects both the source video and the warped depth sequence rendered under the target viewpoint into the pretrained video generation model. This geometric guidance signal enables VDMs to comprehend camera movements and leverage their 3D understanding capabilities, thereby facilitating precise camera control and consistent content generation. Next, we introduce a lightweight LoRA-based video diffusion adapter to train our framework, fully preserving the knowledge priors of VDMs. Additionally, we construct a large-scale multi-camera synchronized dataset named MultiCam-WarpData using Unreal Engine 5, containing 8K videos across 1K dynamic scenes. Extensive experiments show that DepthDirector outperforms existing methods in both camera controllability and visual quality. Our code and dataset will be publicly available.
DEER: Draft with Diffusion, Verify with Autoregressive Models
Dec 17, 2025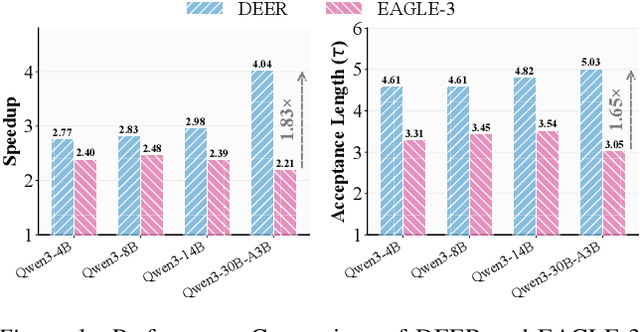
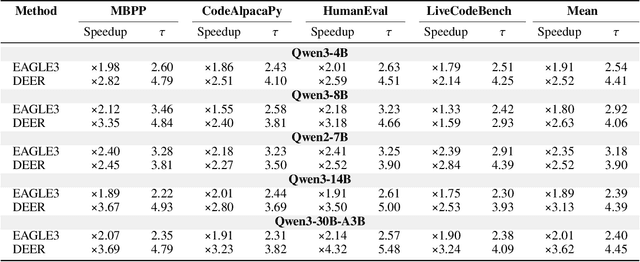
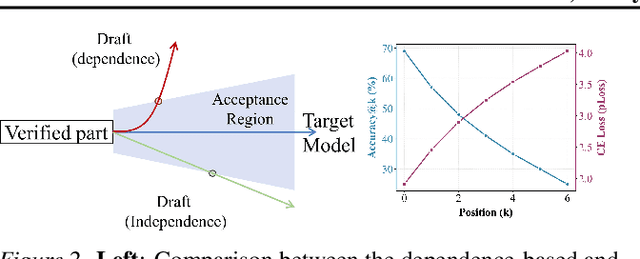
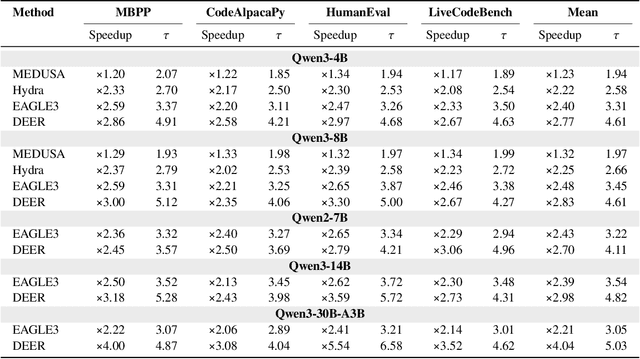
Efficiency, as a critical practical challenge for LLM-driven agentic and reasoning systems, is increasingly constrained by the inherent latency of autoregressive (AR) decoding. Speculative decoding mitigates this cost through a draft-verify scheme, yet existing approaches rely on AR draft models (a.k.a., drafters), which introduce two fundamental issues: (1) step-wise uncertainty accumulation leads to a progressive collapse of trust between the target model and the drafter, and (2) inherently sequential decoding of AR drafters. Together, these factors cause limited speedups. In this paper, we show that a diffusion large language model (dLLM) drafters can naturally overcome these issues through its fundamentally different probabilistic modeling and efficient parallel decoding strategy. Building on this insight, we introduce DEER, an efficient speculative decoding framework that drafts with diffusion and verifies with AR models. To enable high-quality drafting, DEER employs a two-stage training pipeline to align the dLLM-based drafters with the target AR model, and further adopts single-step decoding to generate long draft segments. Experiments show DEER reaches draft acceptance lengths of up to 32 tokens, far surpassing the 10 tokens achieved by EAGLE-3. Moreover, on HumanEval with Qwen3-30B-A3B, DEER attains a 5.54x speedup, while EAGLE-3 achieves only 2.41x. Code, model, demo, etc, will be available at https://czc726.github.io/DEER/
NeuralSSD: A Neural Solver for Signed Distance Surface Reconstruction
Nov 18, 2025We proposed a generalized method, NeuralSSD, for reconstructing a 3D implicit surface from the widely-available point cloud data. NeuralSSD is a solver-based on the neural Galerkin method, aimed at reconstructing higher-quality and accurate surfaces from input point clouds. Implicit method is preferred due to its ability to accurately represent shapes and its robustness in handling topological changes. However, existing parameterizations of implicit fields lack explicit mechanisms to ensure a tight fit between the surface and input data. To address this, we propose a novel energy equation that balances the reliability of point cloud information. Additionally, we introduce a new convolutional network that learns three-dimensional information to achieve superior optimization results. This approach ensures that the reconstructed surface closely adheres to the raw input points and infers valuable inductive biases from point clouds, resulting in a highly accurate and stable surface reconstruction. NeuralSSD is evaluated on a variety of challenging datasets, including the ShapeNet and Matterport datasets, and achieves state-of-the-art results in terms of both surface reconstruction accuracy and generalizability.
GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025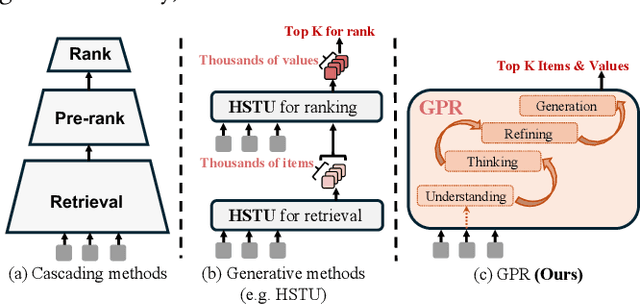
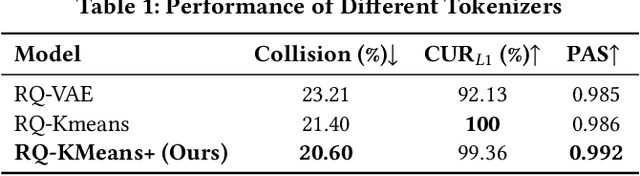
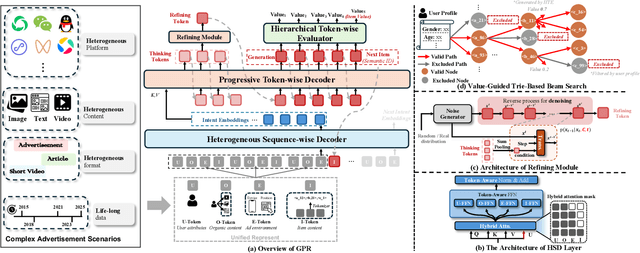
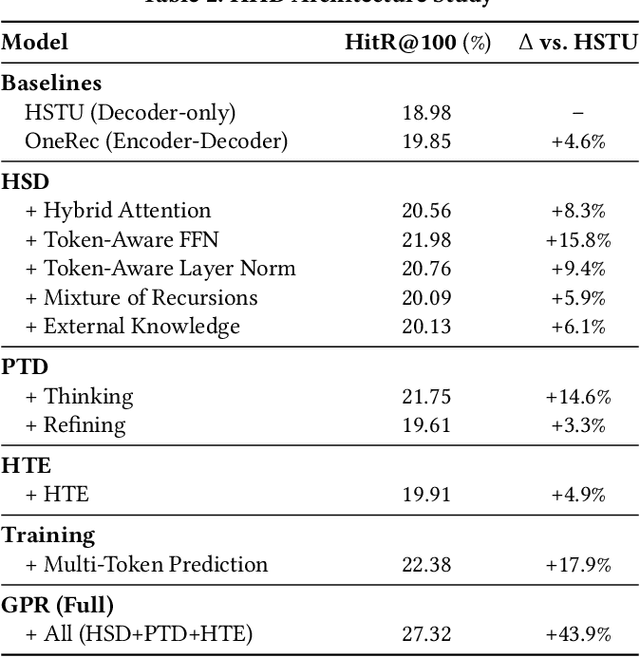
As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
Recovering Complete Actions for Cross-dataset Skeleton Action Recognition
Oct 31, 2024



Despite huge progress in skeleton-based action recognition, its generalizability to different domains remains a challenging issue. In this paper, to solve the skeleton action generalization problem, we present a recover-and-resample augmentation framework based on a novel complete action prior. We observe that human daily actions are confronted with temporal mismatch across different datasets, as they are usually partial observations of their complete action sequences. By recovering complete actions and resampling from these full sequences, we can generate strong augmentations for unseen domains. At the same time, we discover the nature of general action completeness within large datasets, indicated by the per-frame diversity over time. This allows us to exploit two assets of transferable knowledge that can be shared across action samples and be helpful for action completion: boundary poses for determining the action start, and linear temporal transforms for capturing global action patterns. Therefore, we formulate the recovering stage as a two-step stochastic action completion with boundary pose-conditioned extrapolation followed by smooth linear transforms. Both the boundary poses and linear transforms can be efficiently learned from the whole dataset via clustering. We validate our approach on a cross-dataset setting with three skeleton action datasets, outperforming other domain generalization approaches by a considerable margin.
CharacterGen: Efficient 3D Character Generation from Single Images with Multi-View Pose Canonicalization
Feb 28, 2024

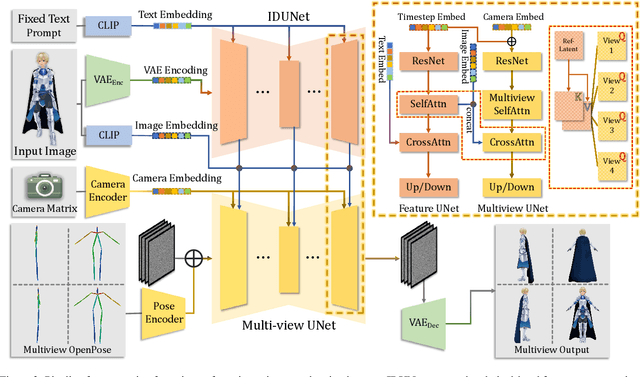

In the field of digital content creation, generating high-quality 3D characters from single images is challenging, especially given the complexities of various body poses and the issues of self-occlusion and pose ambiguity. In this paper, we present CharacterGen, a framework developed to efficiently generate 3D characters. CharacterGen introduces a streamlined generation pipeline along with an image-conditioned multi-view diffusion model. This model effectively calibrates input poses to a canonical form while retaining key attributes of the input image, thereby addressing the challenges posed by diverse poses. A transformer-based, generalizable sparse-view reconstruction model is the other core component of our approach, facilitating the creation of detailed 3D models from multi-view images. We also adopt a texture-back-projection strategy to produce high-quality texture maps. Additionally, we have curated a dataset of anime characters, rendered in multiple poses and views, to train and evaluate our model. Our approach has been thoroughly evaluated through quantitative and qualitative experiments, showing its proficiency in generating 3D characters with high-quality shapes and textures, ready for downstream applications such as rigging and animation.