 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving Deeper into Data Scaling in Masked Image Modeling
May 24, 2023



Understanding whether self-supervised learning methods can scale with unlimited data is crucial for training large-scale models. In this work, we conduct an empirical study on the scaling capability of masked image modeling (MIM) methods (e.g., MAE) for visual recognition. Unlike most previous works that depend on the widely-used ImageNet dataset, which is manually curated and object-centric, we take a step further and propose to investigate this problem in a more practical setting. Specifically, we utilize the web-collected Coyo-700M dataset. We randomly sample varying numbers of training images from the Coyo dataset and construct a series of sub-datasets, containing 0.5M, 1M, 5M, 10M, and 100M images, for pre-training. Our goal is to investigate how the performance changes on downstream tasks when scaling with different sizes of data and models. The study reveals that: 1) MIM can be viewed as an effective method to improve the model capacity when the scale of the training data is relatively small; 2) Strong reconstruction targets can endow the models with increased capacities on downstream tasks; 3) MIM pre-training is data-agnostic under most scenarios, which means that the strategy of sampling pre-training data is non-critical. We hope these observations could provide valuable insights for future research on MIM.
CMAE-V: Contrastive Masked Autoencoders for Video Action Recognition
Jan 15, 2023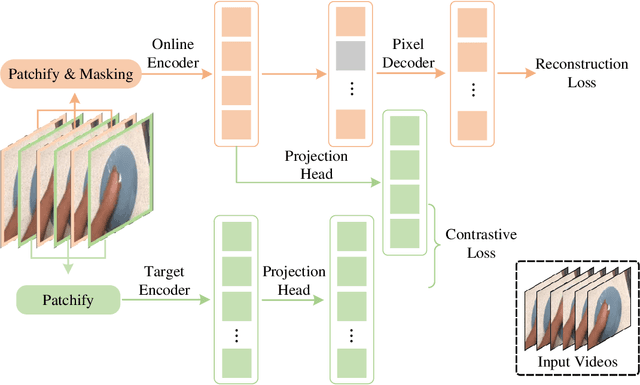
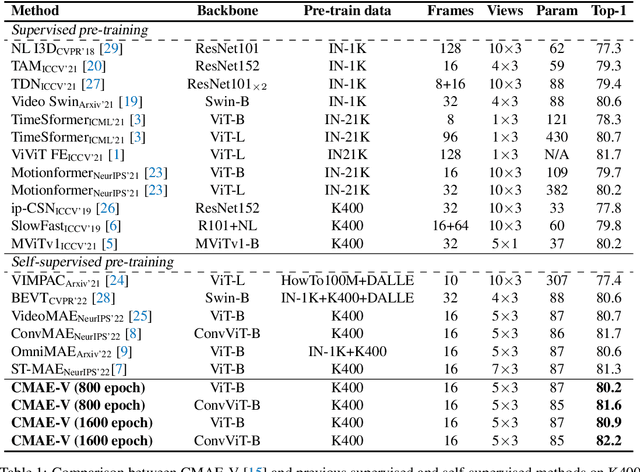
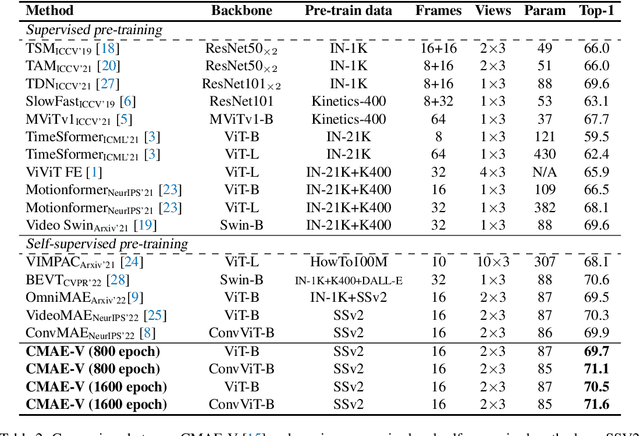
Contrastive Masked Autoencoder (CMAE), as a new self-supervised framework, has shown its potential of learning expressive feature representations in visual image recognition. This work shows that CMAE also trivially generalizes well on video action recognition without modifying the architecture and the loss criterion. By directly replacing the original pixel shift with the temporal shift, our CMAE for visual action recognition, CMAE-V for short, can generate stronger feature representations than its counterpart based on pure masked autoencoders. Notably, CMAE-V, with a hybrid architecture, can achieve 82.2% and 71.6% top-1 accuracy on the Kinetics-400 and Something-something V2 datasets, respectively. We hope this report could provide some informative inspiration for future works.
Conv2Former: A Simple Transformer-Style ConvNet for Visual Recognition
Nov 22, 2022This paper does not attempt to design a state-of-the-art method for visual recognition but investigates a more efficient way to make use of convolutions to encode spatial features. By comparing the design principles of the recent convolutional neural networks ConvNets) and Vision Transformers, we propose to simplify the self-attention by leveraging a convolutional modulation operation. We show that such a simple approach can better take advantage of the large kernels (>=7x7) nested in convolutional layers. We build a family of hierarchical ConvNets using the proposed convolutional modulation, termed Conv2Former. Our network is simple and easy to follow. Experiments show that our Conv2Former outperforms existent popular ConvNets and vision Transformers, like Swin Transformer and ConvNeXt in all ImageNet classification, COCO object detection and ADE20k semantic segmentation.
SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
Sep 18, 2022
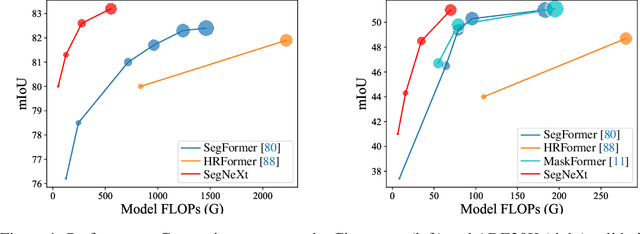
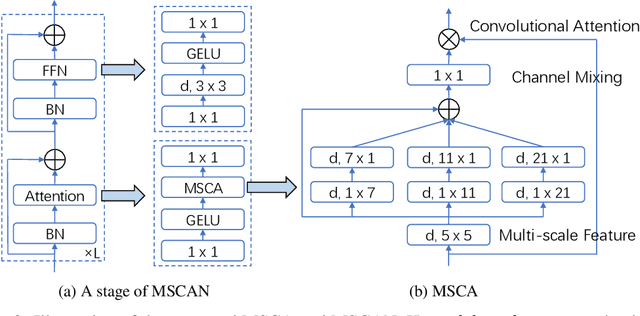
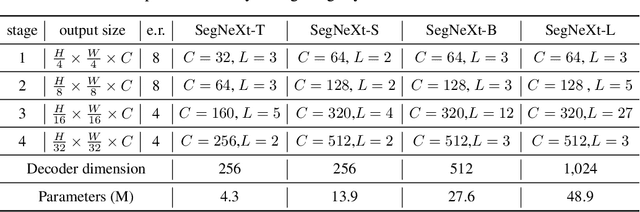
We present SegNeXt, a simple convolutional network architecture for semantic segmentation. Recent transformer-based models have dominated the field of semantic segmentation due to the efficiency of self-attention in encoding spatial information. In this paper, we show that convolutional attention is a more efficient and effective way to encode contextual information than the self-attention mechanism in transformers. By re-examining the characteristics owned by successful segmentation models, we discover several key components leading to the performance improvement of segmentation models. This motivates us to design a novel convolutional attention network that uses cheap convolutional operations. Without bells and whistles, our SegNeXt significantly improves the performance of previous state-of-the-art methods on popular benchmarks, including ADE20K, Cityscapes, COCO-Stuff, Pascal VOC, Pascal Context, and iSAID. Notably, SegNeXt outperforms EfficientNet-L2 w/ NAS-FPN and achieves 90.6% mIoU on the Pascal VOC 2012 test leaderboard using only 1/10 parameters of it. On average, SegNeXt achieves about 2.0% mIoU improvements compared to the state-of-the-art methods on the ADE20K datasets with the same or fewer computations. Code is available at https://github.com/uyzhang/JSeg (Jittor) and https://github.com/Visual-Attention-Network/SegNeXt (Pytorch).
Towards An End-to-End Framework for Flow-Guided Video Inpainting
Apr 07, 2022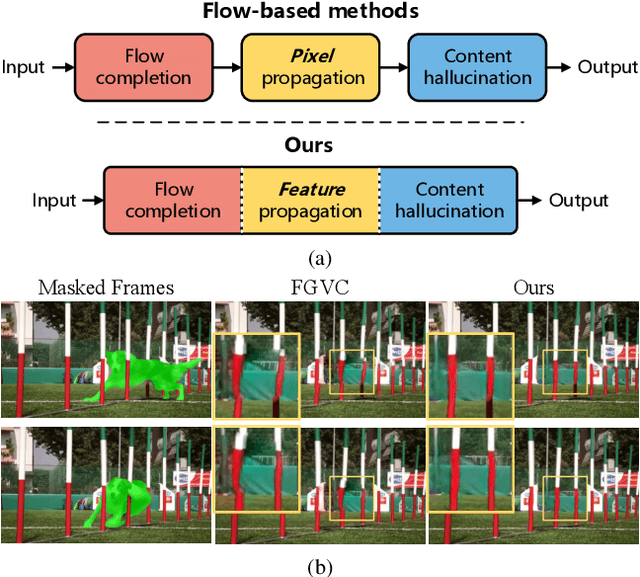
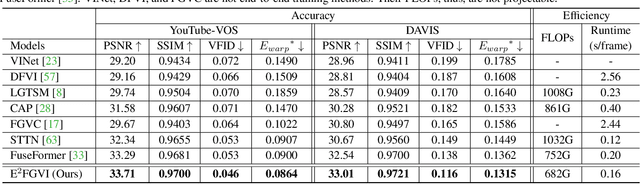
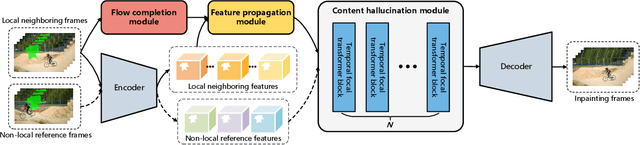
Optical flow, which captures motion information across frames, is exploited in recent video inpainting methods through propagating pixels along its trajectories. However, the hand-crafted flow-based processes in these methods are applied separately to form the whole inpainting pipeline. Thus, these methods are less efficient and rely heavily on the intermediate results from earlier stages. In this paper, we propose an End-to-End framework for Flow-Guided Video Inpainting (E$^2$FGVI) through elaborately designed three trainable modules, namely, flow completion, feature propagation, and content hallucination modules. The three modules correspond with the three stages of previous flow-based methods but can be jointly optimized, leading to a more efficient and effective inpainting process. Experimental results demonstrate that the proposed method outperforms state-of-the-art methods both qualitatively and quantitatively and shows promising efficiency. The code is available at https://github.com/MCG-NKU/E2FGVI.
Visual Attention Network
Mar 08, 2022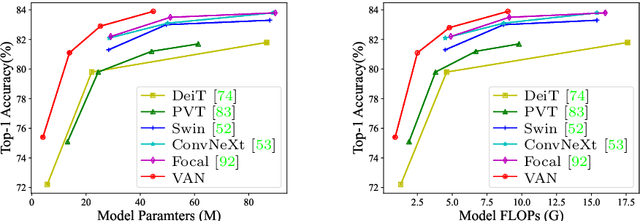


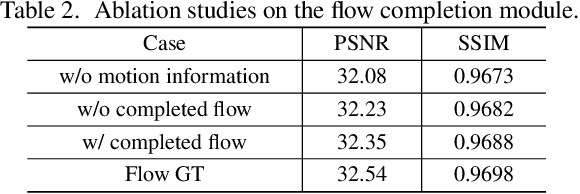
While originally designed for natural language processing tasks, the self-attention mechanism has recently taken various computer vision areas by storm. However, the 2D nature of images brings three challenges for applying self-attention in computer vision. (1) Treating images as 1D sequences neglects their 2D structures. (2) The quadratic complexity is too expensive for high-resolution images. (3) It only captures spatial adaptability but ignores channel adaptability. In this paper, we propose a novel large kernel attention (LKA) module to enable self-adaptive and long-range correlations in self-attention while avoiding the above issues. We further introduce a novel neural network based on LKA, namely Visual Attention Network (VAN). While extremely simple, VAN outperforms the state-of-the-art vision transformers and convolutional neural networks with a large margin in extensive experiments, including image classification, object detection, semantic segmentation, instance segmentation, etc. Code is available at https://github.com/Visual-Attention-Network.