 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust but Verify: Adaptive Conditioning for Reference-Based Diffusion Super-Resolution via Implicit Reference Correlation Modeling
Feb 02, 2026Recent works have explored reference-based super-resolution (RefSR) to mitigate hallucinations in diffusion-based image restoration. A key challenge is that real-world degradations make correspondences between low-quality (LQ) inputs and reference (Ref) images unreliable, requiring adaptive control of reference usage. Existing methods either ignore LQ-Ref correlations or rely on brittle explicit matching, leading to over-reliance on misleading references or under-utilization of valuable cues. To address this, we propose Ada-RefSR, a single-step diffusion framework guided by a "Trust but Verify" principle: reference information is leveraged when reliable and suppressed otherwise. Its core component, Adaptive Implicit Correlation Gating (AICG), employs learnable summary tokens to distill dominant reference patterns and capture implicit correlations with LQ features. Integrated into the attention backbone, AICG provides lightweight, adaptive regulation of reference guidance, serving as a built-in safeguard against erroneous fusion. Experiments on multiple datasets demonstrate that Ada-RefSR achieves a strong balance of fidelity, naturalness, and efficiency, while remaining robust under varying reference alignment.
OmniSegmentor: A Flexible Multi-Modal Learning Framework for Semantic Segmentation
Sep 18, 2025Recent research on representation learning has proved the merits of multi-modal clues for robust semantic segmentation. Nevertheless, a flexible pretrain-and-finetune pipeline for multiple visual modalities remains unexplored. In this paper, we propose a novel multi-modal learning framework, termed OmniSegmentor. It has two key innovations: 1) Based on ImageNet, we assemble a large-scale dataset for multi-modal pretraining, called ImageNeXt, which contains five popular visual modalities. 2) We provide an efficient pretraining manner to endow the model with the capacity to encode different modality information in the ImageNeXt. For the first time, we introduce a universal multi-modal pretraining framework that consistently amplifies the model's perceptual capabilities across various scenarios, regardless of the arbitrary combination of the involved modalities. Remarkably, our OmniSegmentor achieves new state-of-the-art records on a wide range of multi-modal semantic segmentation datasets, including NYU Depthv2, EventScape, MFNet, DeLiVER, SUNRGBD, and KITTI-360.
Revisiting Efficient Semantic Segmentation: Learning Offsets for Better Spatial and Class Feature Alignment
Aug 12, 2025Semantic segmentation is fundamental to vision systems requiring pixel-level scene understanding, yet deploying it on resource-constrained devices demands efficient architectures. Although existing methods achieve real-time inference through lightweight designs, we reveal their inherent limitation: misalignment between class representations and image features caused by a per-pixel classification paradigm. With experimental analysis, we find that this paradigm results in a highly challenging assumption for efficient scenarios: Image pixel features should not vary for the same category in different images. To address this dilemma, we propose a coupled dual-branch offset learning paradigm that explicitly learns feature and class offsets to dynamically refine both class representations and spatial image features. Based on the proposed paradigm, we construct an efficient semantic segmentation network, OffSeg. Notably, the offset learning paradigm can be adopted to existing methods with no additional architectural changes. Extensive experiments on four datasets, including ADE20K, Cityscapes, COCO-Stuff-164K, and Pascal Context, demonstrate consistent improvements with negligible parameters. For instance, on the ADE20K dataset, our proposed offset learning paradigm improves SegFormer-B0, SegNeXt-T, and Mask2Former-Tiny by 2.7%, 1.9%, and 2.6% mIoU, respectively, with only 0.1-0.2M additional parameters required.
Depth Anything at Any Condition
Jul 02, 2025We present Depth Anything at Any Condition (DepthAnything-AC), a foundation monocular depth estimation (MDE) model capable of handling diverse environmental conditions. Previous foundation MDE models achieve impressive performance across general scenes but not perform well in complex open-world environments that involve challenging conditions, such as illumination variations, adverse weather, and sensor-induced distortions. To overcome the challenges of data scarcity and the inability of generating high-quality pseudo-labels from corrupted images, we propose an unsupervised consistency regularization finetuning paradigm that requires only a relatively small amount of unlabeled data. Furthermore, we propose the Spatial Distance Constraint to explicitly enforce the model to learn patch-level relative relationships, resulting in clearer semantic boundaries and more accurate details. Experimental results demonstrate the zero-shot capabilities of DepthAnything-AC across diverse benchmarks, including real-world adverse weather benchmarks, synthetic corruption benchmarks, and general benchmarks. Project Page: https://ghost233lism.github.io/depthanything-AC-page Code: https://github.com/HVision-NKU/DepthAnythingAC
Enhancing Visual Grounding for GUI Agents via Self-Evolutionary Reinforcement Learning
May 18, 2025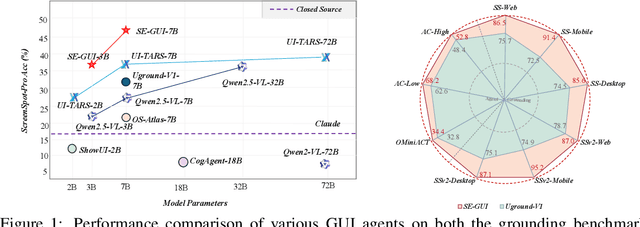
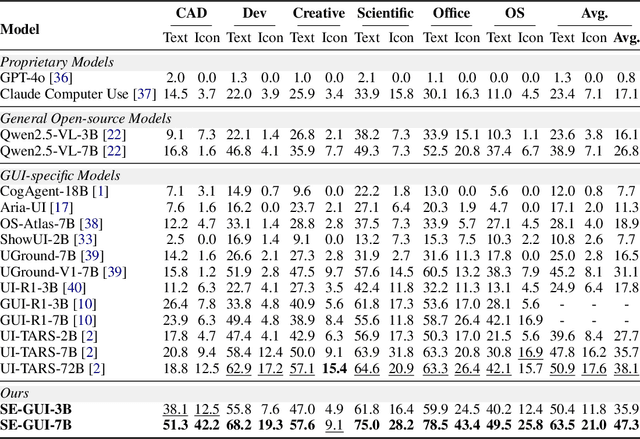
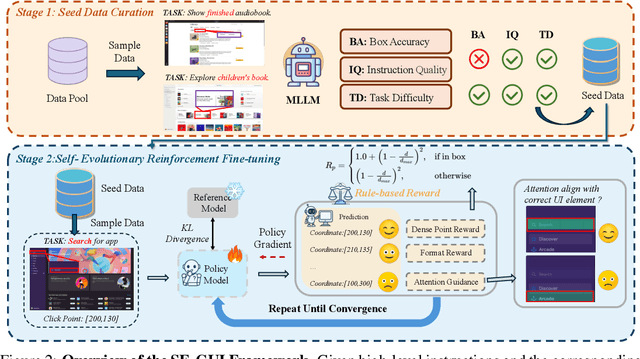
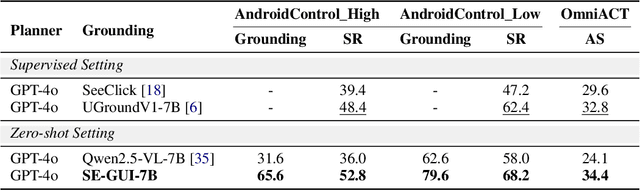
Graphical User Interface (GUI) agents have made substantial strides in understanding and executing user instructions across diverse platforms. Yet, grounding these instructions to precise interface elements remains challenging, especially in complex, high-resolution, professional environments. Traditional supervised finetuning (SFT) methods often require large volumes of diverse data and exhibit weak generalization. To overcome these limitations, we introduce a reinforcement learning (RL) based framework that incorporates three core strategies: (1) seed data curation to ensure high quality training samples, (2) a dense policy gradient that provides continuous feedback based on prediction accuracy, and (3) a self evolutionary reinforcement finetuning mechanism that iteratively refines the model using attention maps. With only 3k training samples, our 7B-parameter model achieves state-of-the-art results among similarly sized models on three grounding benchmarks. Notably, it attains 47.3\% accuracy on the ScreenSpot-Pro dataset, outperforming much larger models, such as UI-TARS-72B, by a margin of 24.2\%. These findings underscore the effectiveness of RL-based approaches in enhancing GUI agent performance, particularly in high-resolution, complex environments.
DFormerv2: Geometry Self-Attention for RGBD Semantic Segmentation
Apr 07, 2025Recent advances in scene understanding benefit a lot from depth maps because of the 3D geometry information, especially in complex conditions (e.g., low light and overexposed). Existing approaches encode depth maps along with RGB images and perform feature fusion between them to enable more robust predictions. Taking into account that depth can be regarded as a geometry supplement for RGB images, a straightforward question arises: Do we really need to explicitly encode depth information with neural networks as done for RGB images? Based on this insight, in this paper, we investigate a new way to learn RGBD feature representations and present DFormerv2, a strong RGBD encoder that explicitly uses depth maps as geometry priors rather than encoding depth information with neural networks. Our goal is to extract the geometry clues from the depth and spatial distances among all the image patch tokens, which will then be used as geometry priors to allocate attention weights in self-attention. Extensive experiments demonstrate that DFormerv2 exhibits exceptional performance in various RGBD semantic segmentation benchmarks. Code is available at: https://github.com/VCIP-RGBD/DFormer.
Re-Aligning Language to Visual Objects with an Agentic Workflow
Mar 30, 2025Language-based object detection (LOD) aims to align visual objects with language expressions. A large amount of paired data is utilized to improve LOD model generalizations. During the training process, recent studies leverage vision-language models (VLMs) to automatically generate human-like expressions for visual objects, facilitating training data scaling up. In this process, we observe that VLM hallucinations bring inaccurate object descriptions (e.g., object name, color, and shape) to deteriorate VL alignment quality. To reduce VLM hallucinations, we propose an agentic workflow controlled by an LLM to re-align language to visual objects via adaptively adjusting image and text prompts. We name this workflow Real-LOD, which includes planning, tool use, and reflection steps. Given an image with detected objects and VLM raw language expressions, Real-LOD reasons its state automatically and arranges action based on our neural symbolic designs (i.e., planning). The action will adaptively adjust the image and text prompts and send them to VLMs for object re-description (i.e., tool use). Then, we use another LLM to analyze these refined expressions for feedback (i.e., reflection). These steps are conducted in a cyclic form to gradually improve language descriptions for re-aligning to visual objects. We construct a dataset that contains a tiny amount of 0.18M images with re-aligned language expression and train a prevalent LOD model to surpass existing LOD methods by around 50% on the standard benchmarks. Our Real-LOD workflow, with automatic VL refinement, reveals a potential to preserve data quality along with scaling up data quantity, which further improves LOD performance from a data-alignment perspective.
KAC: Kolmogorov-Arnold Classifier for Continual Learning
Mar 27, 2025



Continual learning requires models to train continuously across consecutive tasks without forgetting. Most existing methods utilize linear classifiers, which struggle to maintain a stable classification space while learning new tasks. Inspired by the success of Kolmogorov-Arnold Networks (KAN) in preserving learning stability during simple continual regression tasks, we set out to explore their potential in more complex continual learning scenarios. In this paper, we introduce the Kolmogorov-Arnold Classifier (KAC), a novel classifier developed for continual learning based on the KAN structure. We delve into the impact of KAN's spline functions and introduce Radial Basis Functions (RBF) for improved compatibility with continual learning. We replace linear classifiers with KAC in several recent approaches and conduct experiments across various continual learning benchmarks, all of which demonstrate performance improvements, highlighting the effectiveness and robustness of KAC in continual learning. The code is available at https://github.com/Ethanhuhuhu/KAC.
AR-1-to-3: Single Image to Consistent 3D Object Generation via Next-View Prediction
Mar 17, 2025Novel view synthesis (NVS) is a cornerstone for image-to-3d creation. However, existing works still struggle to maintain consistency between the generated views and the input views, especially when there is a significant camera pose difference, leading to poor-quality 3D geometries and textures. We attribute this issue to their treatment of all target views with equal priority according to our empirical observation that the target views closer to the input views exhibit higher fidelity. With this inspiration, we propose AR-1-to-3, a novel next-view prediction paradigm based on diffusion models that first generates views close to the input views, which are then utilized as contextual information to progressively synthesize farther views. To encode the generated view subsequences as local and global conditions for the next-view prediction, we accordingly develop a stacked local feature encoding strategy (Stacked-LE) and an LSTM-based global feature encoding strategy (LSTM-GE). Extensive experiments demonstrate that our method significantly improves the consistency between the generated views and the input views, producing high-fidelity 3D assets.
K-LoRA: Unlocking Training-Free Fusion of Any Subject and Style LoRAs
Feb 25, 2025Recent studies have explored combining different LoRAs to jointly generate learned style and content. However, existing methods either fail to effectively preserve both the original subject and style simultaneously or require additional training. In this paper, we argue that the intrinsic properties of LoRA can effectively guide diffusion models in merging learned subject and style. Building on this insight, we propose K-LoRA, a simple yet effective training-free LoRA fusion approach. In each attention layer, K-LoRA compares the Top-K elements in each LoRA to be fused, determining which LoRA to select for optimal fusion. This selection mechanism ensures that the most representative features of both subject and style are retained during the fusion process, effectively balancing their contributions. Experimental results demonstrate that the proposed method effectively integrates the subject and style information learned by the original LoRAs, outperforming state-of-the-art training-based approaches in both qualitative and quantitative results.