 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Uncertainty-Guided and Top-k Codebook Matching for Real-World Blind Image Super-Resolution
Jun 09, 2025Recent advancements in codebook-based real image super-resolution (SR) have shown promising results in real-world applications. The core idea involves matching high-quality image features from a codebook based on low-resolution (LR) image features. However, existing methods face two major challenges: inaccurate feature matching with the codebook and poor texture detail reconstruction. To address these issues, we propose a novel Uncertainty-Guided and Top-k Codebook Matching SR (UGTSR) framework, which incorporates three key components: (1) an uncertainty learning mechanism that guides the model to focus on texture-rich regions, (2) a Top-k feature matching strategy that enhances feature matching accuracy by fusing multiple candidate features, and (3) an Align-Attention module that enhances the alignment of information between LR and HR features. Experimental results demonstrate significant improvements in texture realism and reconstruction fidelity compared to existing methods. We will release the code upon formal publication.
Adaptive Blind Super-Resolution Network for Spatial-Specific and Spatial-Agnostic Degradations
Jun 09, 2025Prior methodologies have disregarded the diversities among distinct degradation types during image reconstruction, employing a uniform network model to handle multiple deteriorations. Nevertheless, we discover that prevalent degradation modalities, including sampling, blurring, and noise, can be roughly categorized into two classes. We classify the first class as spatial-agnostic dominant degradations, less affected by regional changes in image space, such as downsampling and noise degradation. The second class degradation type is intimately associated with the spatial position of the image, such as blurring, and we identify them as spatial-specific dominant degradations. We introduce a dynamic filter network integrating global and local branches to address these two degradation types. This network can greatly alleviate the practical degradation problem. Specifically, the global dynamic filtering layer can perceive the spatial-agnostic dominant degradation in different images by applying weights generated by the attention mechanism to multiple parallel standard convolution kernels, enhancing the network's representation ability. Meanwhile, the local dynamic filtering layer converts feature maps of the image into a spatially specific dynamic filtering operator, which performs spatially specific convolution operations on the image features to handle spatial-specific dominant degradations. By effectively integrating both global and local dynamic filtering operators, our proposed method outperforms state-of-the-art blind super-resolution algorithms in both synthetic and real image datasets.
Proto-FG3D: Prototype-based Interpretable Fine-Grained 3D Shape Classification
May 23, 2025Deep learning-based multi-view coarse-grained 3D shape classification has achieved remarkable success over the past decade, leveraging the powerful feature learning capabilities of CNN-based and ViT-based backbones. However, as a challenging research area critical for detailed shape understanding, fine-grained 3D classification remains understudied due to the limited discriminative information captured during multi-view feature aggregation, particularly for subtle inter-class variations, class imbalance, and inherent interpretability limitations of parametric model. To address these problems, we propose the first prototype-based framework named Proto-FG3D for fine-grained 3D shape classification, achieving a paradigm shift from parametric softmax to non-parametric prototype learning. Firstly, Proto-FG3D establishes joint multi-view and multi-category representation learning via Prototype Association. Secondly, prototypes are refined via Online Clustering, improving both the robustness of multi-view feature allocation and inter-subclass balance. Finally, prototype-guided supervised learning is established to enhance fine-grained discrimination via prototype-view correlation analysis and enables ad-hoc interpretability through transparent case-based reasoning. Experiments on FG3D and ModelNet40 show Proto-FG3D surpasses state-of-the-art methods in accuracy, transparent predictions, and ad-hoc interpretability with visualizations, challenging conventional fine-grained 3D recognition approaches.
AR-1-to-3: Single Image to Consistent 3D Object Generation via Next-View Prediction
Mar 17, 2025Novel view synthesis (NVS) is a cornerstone for image-to-3d creation. However, existing works still struggle to maintain consistency between the generated views and the input views, especially when there is a significant camera pose difference, leading to poor-quality 3D geometries and textures. We attribute this issue to their treatment of all target views with equal priority according to our empirical observation that the target views closer to the input views exhibit higher fidelity. With this inspiration, we propose AR-1-to-3, a novel next-view prediction paradigm based on diffusion models that first generates views close to the input views, which are then utilized as contextual information to progressively synthesize farther views. To encode the generated view subsequences as local and global conditions for the next-view prediction, we accordingly develop a stacked local feature encoding strategy (Stacked-LE) and an LSTM-based global feature encoding strategy (LSTM-GE). Extensive experiments demonstrate that our method significantly improves the consistency between the generated views and the input views, producing high-fidelity 3D assets.
GroupTransNet: Group Transformer Network for RGB-D Salient Object Detection
Mar 21, 2022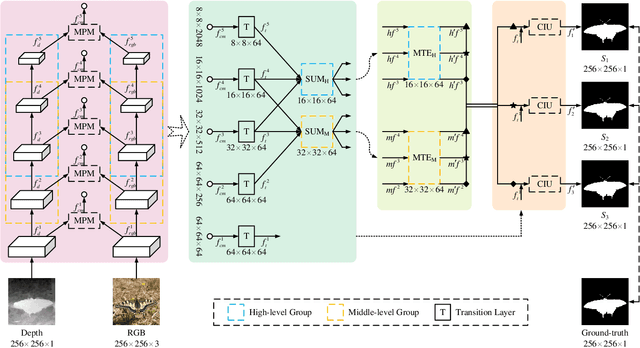
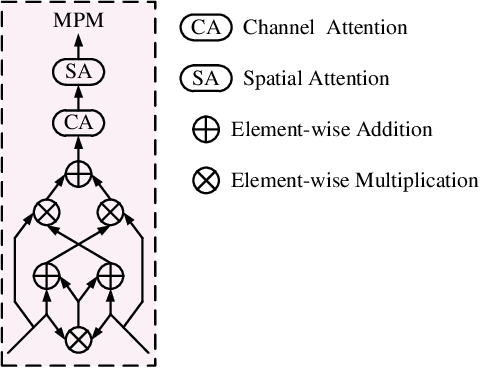
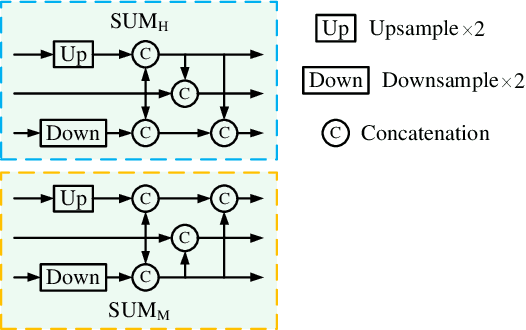
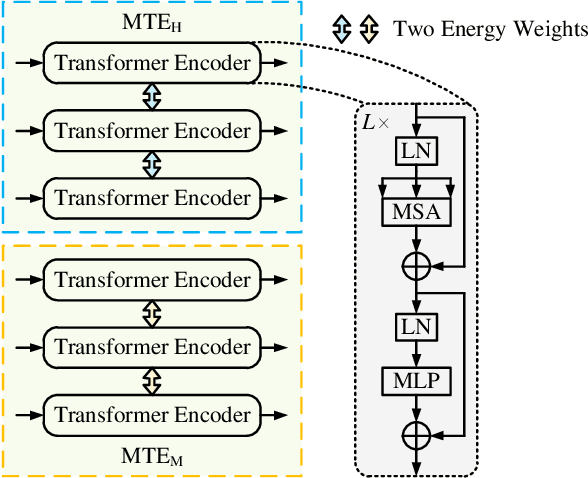
Salient object detection on RGB-D images is an active topic in computer vision. Although the existing methods have achieved appreciable performance, there are still some challenges. The locality of convolutional neural network requires that the model has a sufficiently deep global receptive field, which always leads to the loss of local details. To address the challenge, we propose a novel Group Transformer Network (GroupTransNet) for RGB-D salient object detection. This method is good at learning the long-range dependencies of cross layer features to promote more perfect feature expression. At the beginning, the features of the slightly higher classes of the middle three levels and the latter three levels are soft grouped to absorb the advantages of the high-level features. The input features are repeatedly purified and enhanced by the attention mechanism to purify the cross modal features of color modal and depth modal. The features of the intermediate process are first fused by the features of different layers, and then processed by several transformers in multiple groups, which not only makes the size of the features of each scale unified and interrelated, but also achieves the effect of sharing the weight of the features within the group. The output features in different groups complete the clustering staggered by two owing to the level difference, and combine with the low-level features. Extensive experiments demonstrate that GroupTransNet outperforms the comparison models and achieves the new state-of-the-art performance.
LC3Net: Ladder context correlation complementary network for salient object detection
Oct 21, 2021
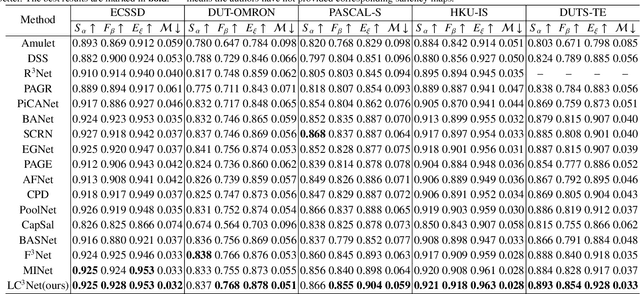
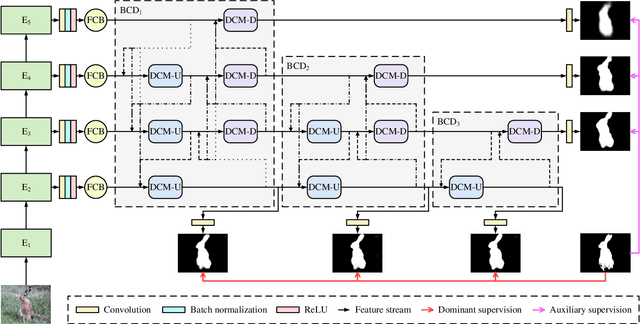
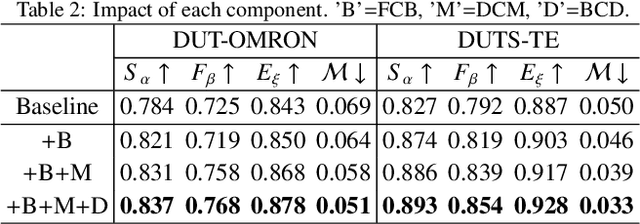
Currently, existing salient object detection methods based on convolutional neural networks commonly resort to constructing discriminative networks to aggregate high level and low level features. However, contextual information is always not fully and reasonably utilized, which usually causes either the absence of useful features or contamination of redundant features. To address these issues, we propose a novel ladder context correlation complementary network (LC3Net) in this paper, which is equipped with three crucial components. At the beginning, we propose a filterable convolution block (FCB) to assist the automatic collection of information on the diversity of initial features, and it is simple yet practical. Besides, we propose a dense cross module (DCM) to facilitate the intimate aggregation of different levels of features by validly integrating semantic information and detailed information of both adjacent and non-adjacent layers. Furthermore, we propose a bidirectional compression decoder (BCD) to help the progressive shrinkage of multi-scale features from coarse to fine by leveraging multiple pairs of alternating top-down and bottom-up feature interaction flows. Extensive experiments demonstrate the superiority of our method against 16 state-of-the-art methods.
M2RNet: Multi-modal and Multi-scale Refined Network for RGB-D Salient Object Detection
Sep 16, 2021
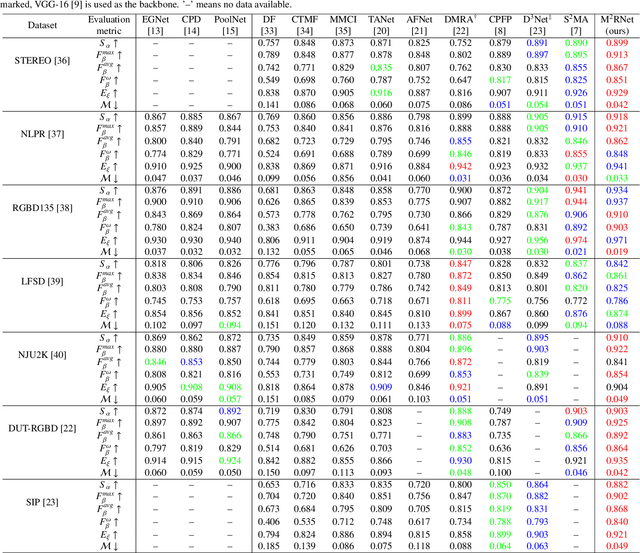
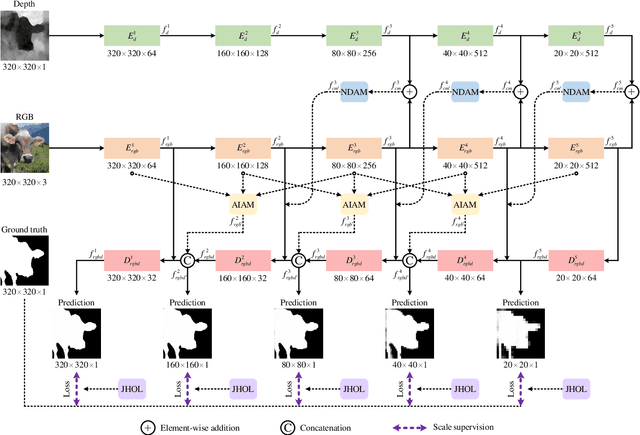

Salient object detection is a fundamental topic in computer vision. Previous methods based on RGB-D often suffer from the incompatibility of multi-modal feature fusion and the insufficiency of multi-scale feature aggregation. To tackle these two dilemmas, we propose a novel multi-modal and multi-scale refined network (M2RNet). Three essential components are presented in this network. The nested dual attention module (NDAM) explicitly exploits the combined features of RGB and depth flows. The adjacent interactive aggregation module (AIAM) gradually integrates the neighbor features of high, middle and low levels. The joint hybrid optimization loss (JHOL) makes the predictions have a prominent outline. Extensive experiments demonstrate that our method outperforms other state-of-the-art approaches.