 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Low-Rank Adaptation for Pre-Trained Vision Transformers
Dec 31, 2025Low-rank adaptation (LoRA) has achieved remarkable success in fine-tuning pre-trained vision transformers for various downstream tasks. Existing studies mainly focus on exploring more parameter-efficient strategies or more effective representation learning schemes. However, these methods either sacrifice fine-tuning performance or introduce excessive trainable parameters, failing to strike a balance between learning performance and parameter efficiency. To address this problem, we propose a novel tuning method named collaborative low-rank adaptation (CLoRA) in this paper. CLoRA consists of base-space sharing and sample-agnostic diversity enhancement (SADE) components. To maintain parameter efficiency while expanding the learning capacity of low-rank modules (LRMs), base-space sharing allows all LRMs to share a set of down/up-projection spaces. In CLoRA, the low-rank matrices obtained from the shared spaces collaboratively construct each LRM. Since the representations extracted by these matrices may contain redundant information, SADE is employed to regularize the similarities among them to encourage diverse representations in the training process. We conduct extensive experiments on widely used image and point cloud datasets to evaluate the performance of CLoRA. Experimental results demonstrate that CLoRA strikes a better balance between learning performance and parameter efficiency, while requiring the fewest GFLOPs for point cloud analysis, compared with the state-of-the-art methods.
Multiple-Exit Tuning: Towards Inference-Efficient Adaptation for Vision Transformer
Sep 21, 2024Parameter-efficient transfer learning (PETL) has shown great potential in adapting a vision transformer (ViT) pre-trained on large-scale datasets to various downstream tasks. Existing studies primarily focus on minimizing the number of learnable parameters. Although these methods are storage-efficient, they allocate excessive computational resources to easy samples, leading to inefficient inference. To address this issue, we introduce an inference-efficient tuning method termed multiple-exit tuning (MET). MET integrates multiple exits into the pre-trained ViT backbone. Since the predictions in ViT are made by a linear classifier, each exit is equipped with a linear prediction head. In inference stage, easy samples will exit at early exits and only hard enough samples will flow to the last exit, thus saving the computational cost for easy samples. MET consists of exit-specific adapters (E-adapters) and graph regularization. E-adapters are designed to extract suitable representations for different exits. To ensure parameter efficiency, all E-adapters share the same down-projection and up-projection matrices. As the performances of linear classifiers are influenced by the relationship among samples, we employ graph regularization to improve the representations fed into the classifiers at early exits. Finally, we conduct extensive experiments to verify the performance of MET. Experimental results show that MET has an obvious advantage over the state-of-the-art methods in terms of both accuracy and inference efficiency.
Progressive Confident Masking Attention Network for Audio-Visual Segmentation
Jun 04, 2024
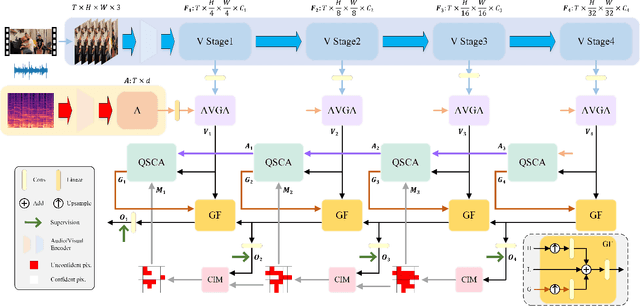
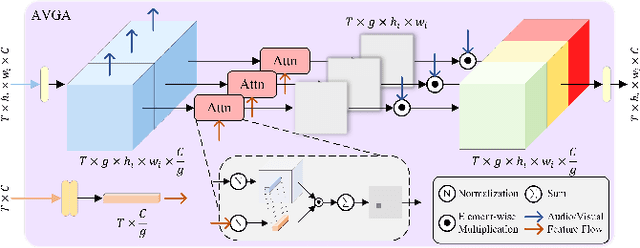
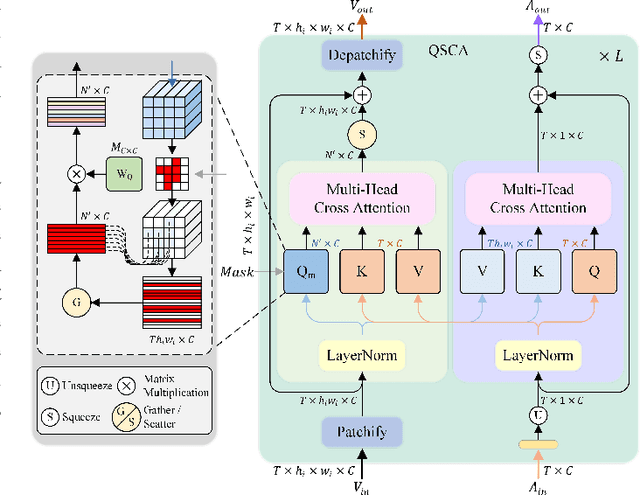
Audio and visual signals typically occur simultaneously, and humans possess an innate ability to correlate and synchronize information from these two modalities. Recently, a challenging problem known as Audio-Visual Segmentation (AVS) has emerged, intending to produce segmentation maps for sounding objects within a scene. However, the methods proposed so far have not sufficiently integrated audio and visual information, and the computational costs have been extremely high. Additionally, the outputs of different stages have not been fully utilized. To facilitate this research, we introduce a novel Progressive Confident Masking Attention Network (PMCANet). It leverages attention mechanisms to uncover the intrinsic correlations between audio signals and visual frames. Furthermore, we design an efficient and effective cross-attention module to enhance semantic perception by selecting query tokens. This selection is determined through confidence-driven units based on the network's multi-stage predictive outputs. Experiments demonstrate that our network outperforms other AVS methods while requiring less computational resources.
A-SDM: Accelerating Stable Diffusion through Redundancy Removal and Performance Optimization
Dec 27, 2023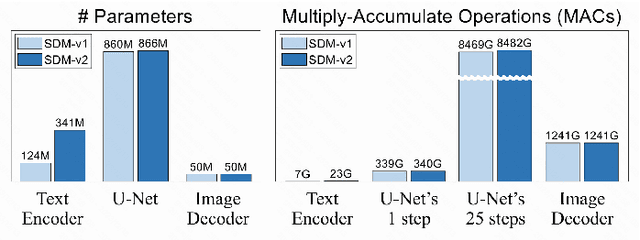
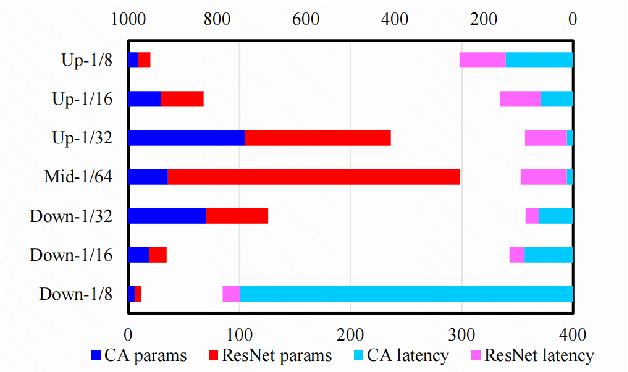
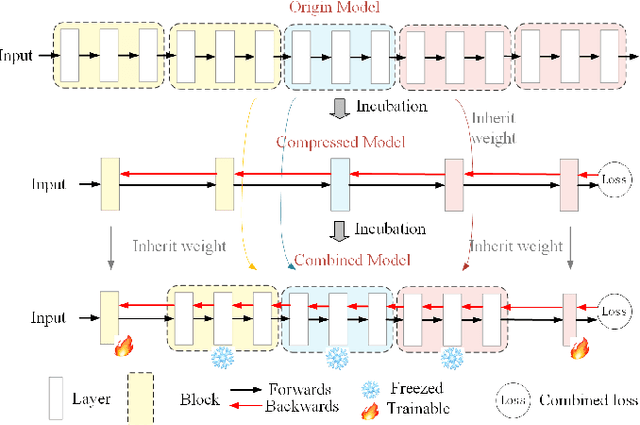
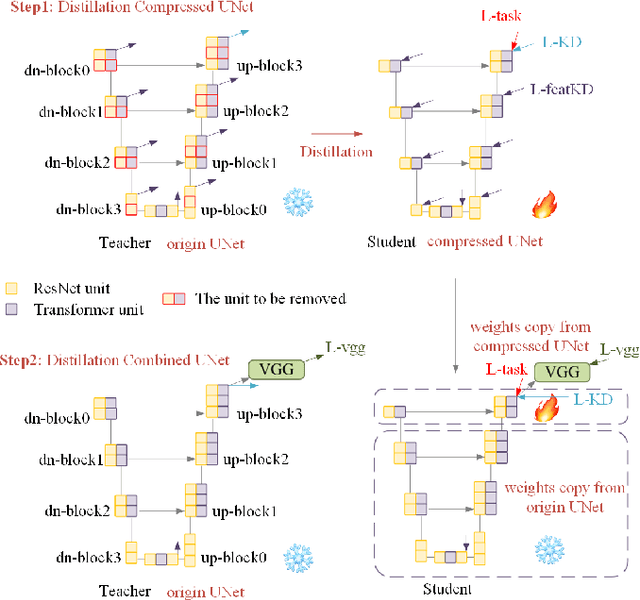
The Stable Diffusion Model (SDM) is a popular and efficient text-to-image (t2i) generation and image-to-image (i2i) generation model. Although there have been some attempts to reduce sampling steps, model distillation, and network quantization, these previous methods generally retain the original network architecture. Billion scale parameters and high computing requirements make the research of model architecture adjustment scarce. In this work, we first explore the computational redundancy part of the network, and then prune the redundancy blocks of the model and maintain the network performance through a progressive incubation strategy. Secondly, in order to maintaining the model performance, we add cross-layer multi-expert conditional convolution (CLME-Condconv) to the block pruning part to inherit the original convolution parameters. Thirdly, we propose a global-regional interactive (GRI) attention to speed up the computationally intensive attention part. Finally, we use semantic-aware supervision (SAS) to align the outputs of the teacher model and student model at the semantic level. Experiments show that this method can effectively train a lightweight model close to the performance of the original SD model, and effectively improve the model speed under limited resources. Experiments show that the proposed method can effectively train a light-weight model close to the performance of the original SD model, and effectively improve the model speed under limited resources. After acceleration, the UNet part of the model is 22% faster and the overall speed is 19% faster.
Interactive Context-Aware Network for RGB-T Salient Object Detection
Nov 11, 2022
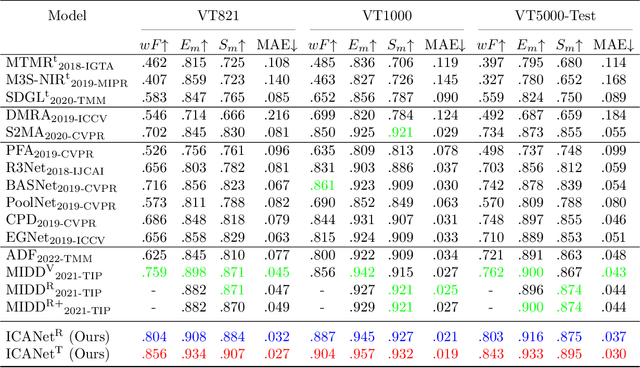

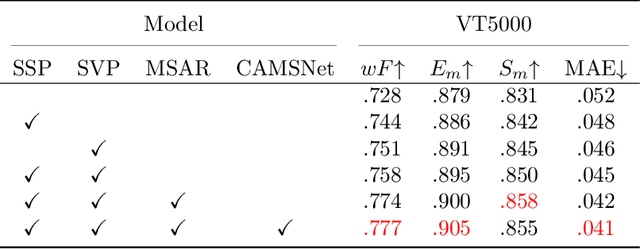
Salient object detection (SOD) focuses on distinguishing the most conspicuous objects in the scene. However, most related works are based on RGB images, which lose massive useful information. Accordingly, with the maturity of thermal technology, RGB-T (RGB-Thermal) multi-modality tasks attain more and more attention. Thermal infrared images carry important information which can be used to improve the accuracy of SOD prediction. To accomplish it, the methods to integrate multi-modal information and suppress noises are critical. In this paper, we propose a novel network called Interactive Context-Aware Network (ICANet). It contains three modules that can effectively perform the cross-modal and cross-scale fusions. We design a Hybrid Feature Fusion (HFF) module to integrate the features of two modalities, which utilizes two types of feature extraction. The Multi-Scale Attention Reinforcement (MSAR) and Upper Fusion (UF) blocks are responsible for the cross-scale fusion that converges different levels of features and generate the prediction maps. We also raise a novel Context-Aware Multi-Supervised Network (CAMSNet) to calculate the content loss between the prediction and the ground truth (GT). Experiments prove that our network performs favorably against the state-of-the-art RGB-T SOD methods.
LC3Net: Ladder context correlation complementary network for salient object detection
Oct 21, 2021
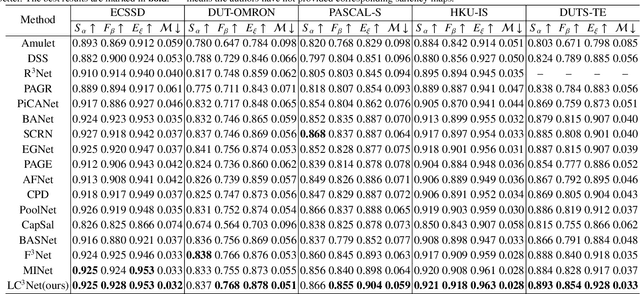
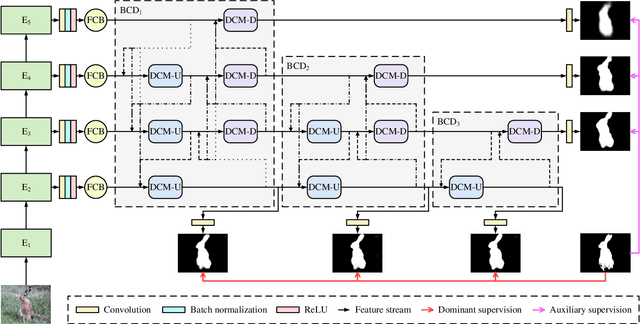
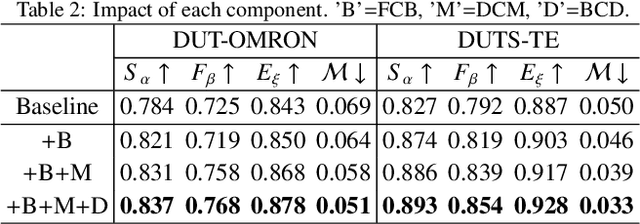
Currently, existing salient object detection methods based on convolutional neural networks commonly resort to constructing discriminative networks to aggregate high level and low level features. However, contextual information is always not fully and reasonably utilized, which usually causes either the absence of useful features or contamination of redundant features. To address these issues, we propose a novel ladder context correlation complementary network (LC3Net) in this paper, which is equipped with three crucial components. At the beginning, we propose a filterable convolution block (FCB) to assist the automatic collection of information on the diversity of initial features, and it is simple yet practical. Besides, we propose a dense cross module (DCM) to facilitate the intimate aggregation of different levels of features by validly integrating semantic information and detailed information of both adjacent and non-adjacent layers. Furthermore, we propose a bidirectional compression decoder (BCD) to help the progressive shrinkage of multi-scale features from coarse to fine by leveraging multiple pairs of alternating top-down and bottom-up feature interaction flows. Extensive experiments demonstrate the superiority of our method against 16 state-of-the-art methods.
M2RNet: Multi-modal and Multi-scale Refined Network for RGB-D Salient Object Detection
Sep 16, 2021
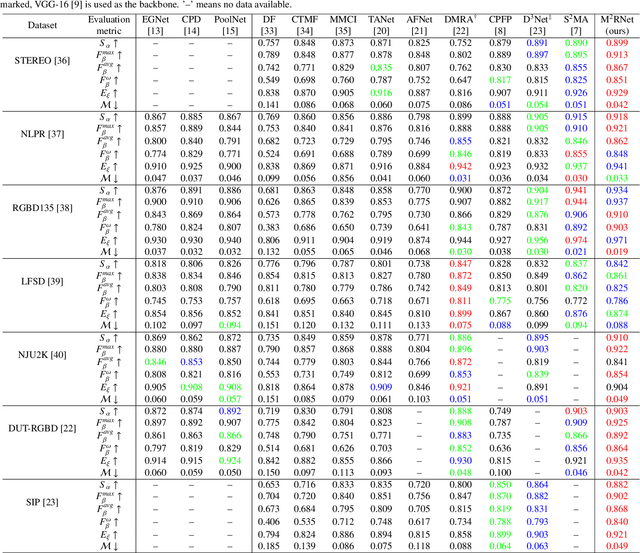
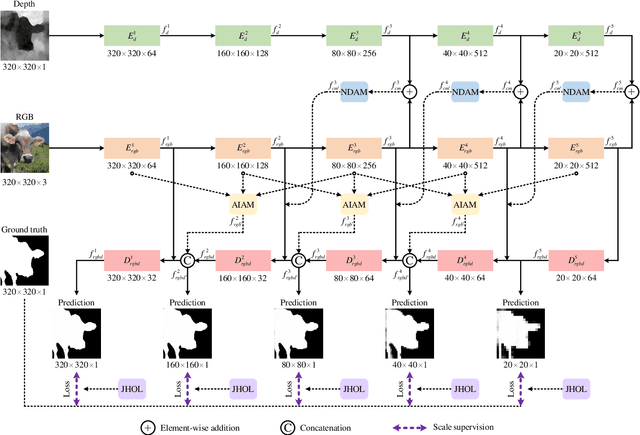

Salient object detection is a fundamental topic in computer vision. Previous methods based on RGB-D often suffer from the incompatibility of multi-modal feature fusion and the insufficiency of multi-scale feature aggregation. To tackle these two dilemmas, we propose a novel multi-modal and multi-scale refined network (M2RNet). Three essential components are presented in this network. The nested dual attention module (NDAM) explicitly exploits the combined features of RGB and depth flows. The adjacent interactive aggregation module (AIAM) gradually integrates the neighbor features of high, middle and low levels. The joint hybrid optimization loss (JHOL) makes the predictions have a prominent outline. Extensive experiments demonstrate that our method outperforms other state-of-the-art approaches.
ACFNet: Adaptively-Cooperative Fusion Network for RGB-D Salient Object Detection
Sep 10, 2021
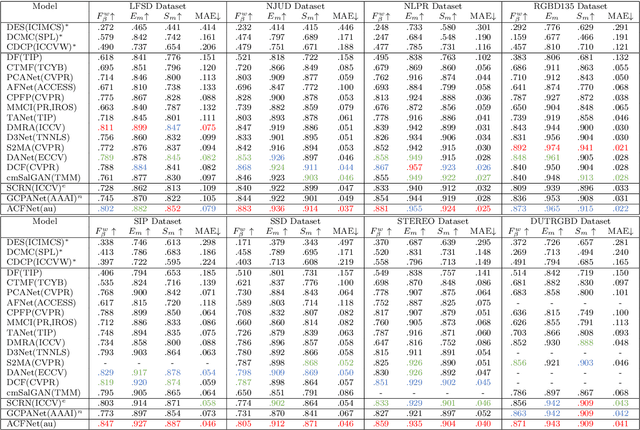
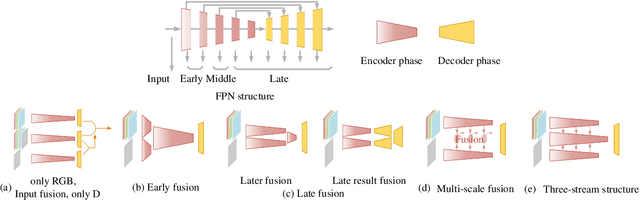
The reasonable employment of RGB and depth data show great significance in promoting the development of computer vision tasks and robot-environment interaction. However, there are different advantages and disadvantages in the early and late fusion of the two types of data. Besides, due to the diversity of object information, using a single type of data in a specific scenario tends to result in semantic misleading. Based on the above considerations, we propose an adaptively-cooperative fusion network (ACFNet) with ResinRes structure for salient object detection. This structure is designed to flexibly utilize the advantages of feature fusion in early and late stages. Secondly, an adaptively-cooperative semantic guidance (ACG) scheme is designed to suppress inaccurate features in the guidance phase. Further, we proposed a type-based attention module (TAM) to optimize the network and enhance the multi-scale perception of different objects. For different objects, the features generated by different types of convolution are enhanced or suppressed by the gated mechanism for segmentation optimization. ACG and TAM optimize the transfer of feature streams according to their data attributes and convolution attributes, respectively. Sufficient experiments conducted on RGB-D SOD datasets illustrate that the proposed network performs favorably against 18 state-of-the-art algorithms.
Modal-Adaptive Gated Recoding Network for RGB-D Salient Object Detection
Aug 13, 2021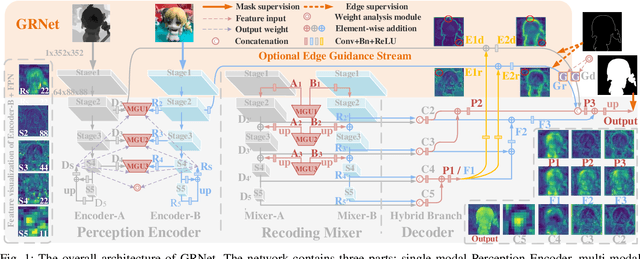
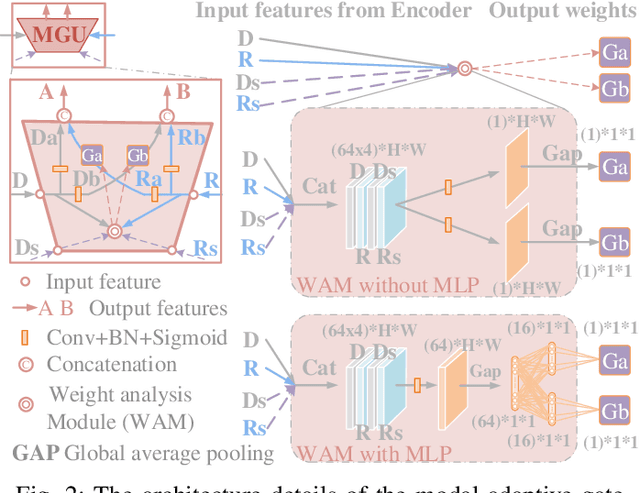

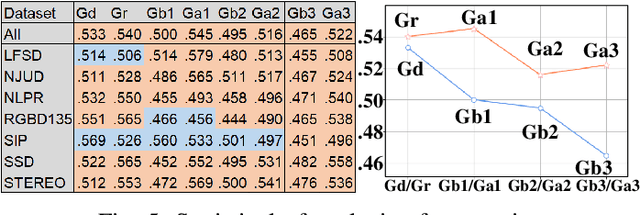
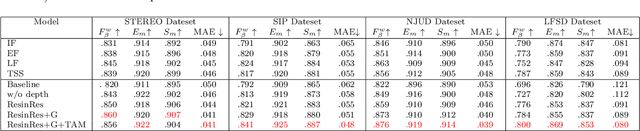
The multi-modal salient object detection model based on RGB-D information has better robustness in the real world. However, it remains nontrivial to better adaptively balance effective multi-modal information in the feature fusion phase. In this letter, we propose a novel gated recoding network (GRNet) to evaluate the information validity of the two modes, and balance their influence. Our framework is divided into three phases: perception phase, recoding mixing phase and feature integration phase. First, A perception encoder is adopted to extract multi-level single-modal features, which lays the foundation for multi-modal semantic comparative analysis. Then, a modal-adaptive gate unit (MGU) is proposed to suppress the invalid information and transfer the effective modal features to the recoding mixer and the hybrid branch decoder. The recoding mixer is responsible for recoding and mixing the balanced multi-modal information. Finally, the hybrid branch decoder completes the multi-level feature integration under the guidance of an optional edge guidance stream (OEGS). Experiments and analysis on eight popular benchmarks verify that our framework performs favorably against 9 state-of-art methods.
Perception-and-Regulation Network for Salient Object Detection
Jul 27, 2021

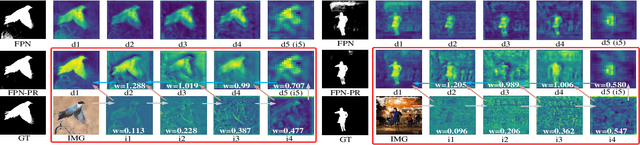

Effective fusion of different types of features is the key to salient object detection. The majority of existing network structure design is based on the subjective experience of scholars and the process of feature fusion does not consider the relationship between the fused features and highest-level features. In this paper, we focus on the feature relationship and propose a novel global attention unit, which we term the "perception- and-regulation" (PR) block, that adaptively regulates the feature fusion process by explicitly modeling interdependencies between features. The perception part uses the structure of fully-connected layers in classification networks to learn the size and shape of objects. The regulation part selectively strengthens and weakens the features to be fused. An imitating eye observation module (IEO) is further employed for improving the global perception ability of the network. The imitation of foveal vision and peripheral vision enables IEO to scrutinize highly detailed objects and to organize the broad spatial scene to better segment objects. Sufficient experiments conducted on SOD datasets demonstrate that the proposed method performs favorably against 22 state-of-the-art methods.