 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACFNet: Adaptively-Cooperative Fusion Network for RGB-D Salient Object Detection
Paper and Code
Sep 10, 2021
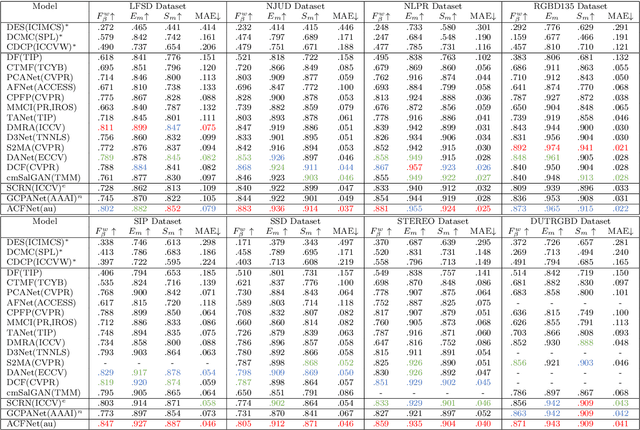
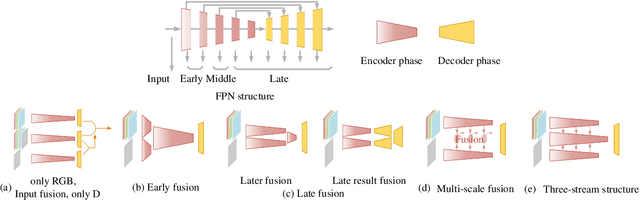
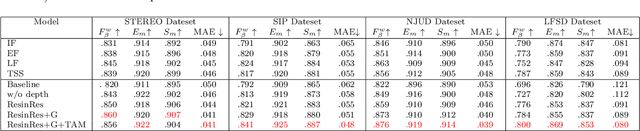
The reasonable employment of RGB and depth data show great significance in promoting the development of computer vision tasks and robot-environment interaction. However, there are different advantages and disadvantages in the early and late fusion of the two types of data. Besides, due to the diversity of object information, using a single type of data in a specific scenario tends to result in semantic misleading. Based on the above considerations, we propose an adaptively-cooperative fusion network (ACFNet) with ResinRes structure for salient object detection. This structure is designed to flexibly utilize the advantages of feature fusion in early and late stages. Secondly, an adaptively-cooperative semantic guidance (ACG) scheme is designed to suppress inaccurate features in the guidance phase. Further, we proposed a type-based attention module (TAM) to optimize the network and enhance the multi-scale perception of different objects. For different objects, the features generated by different types of convolution are enhanced or suppressed by the gated mechanism for segmentation optimization. ACG and TAM optimize the transfer of feature streams according to their data attributes and convolution attributes, respectively. Sufficient experiments conducted on RGB-D SOD datasets illustrate that the proposed network performs favorably against 18 state-of-the-art algorithms.