 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-SDM: Accelerating Stable Diffusion through Redundancy Removal and Performance Optimization
Dec 27, 2023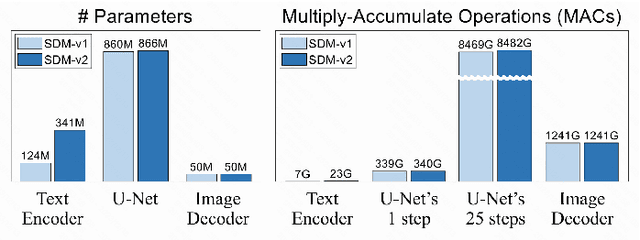
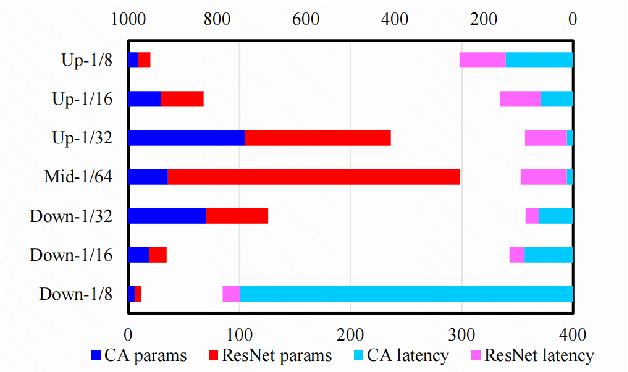
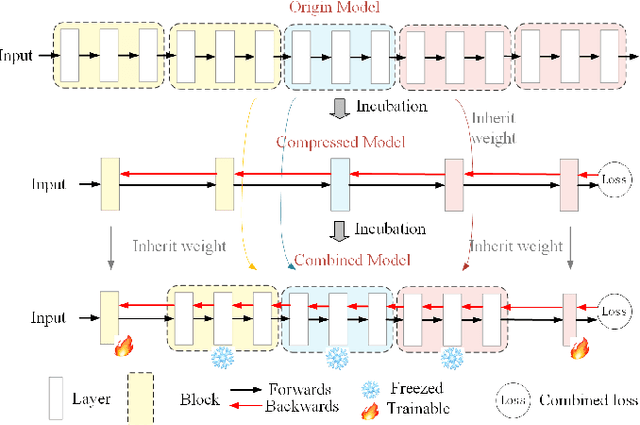
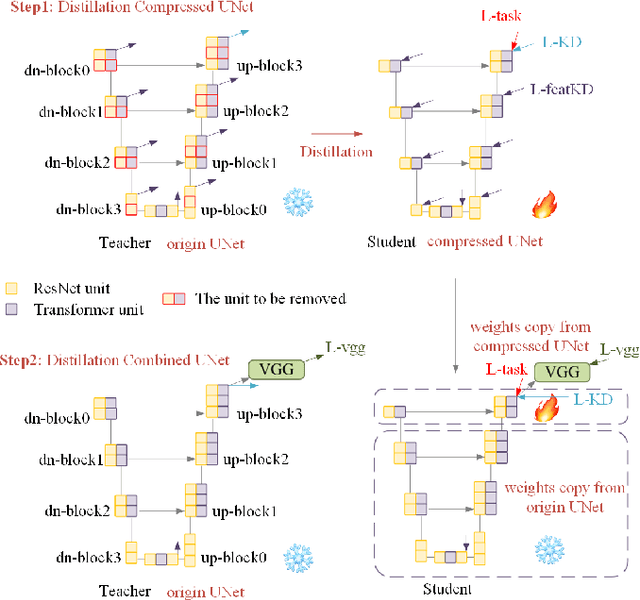
The Stable Diffusion Model (SDM) is a popular and efficient text-to-image (t2i) generation and image-to-image (i2i) generation model. Although there have been some attempts to reduce sampling steps, model distillation, and network quantization, these previous methods generally retain the original network architecture. Billion scale parameters and high computing requirements make the research of model architecture adjustment scarce. In this work, we first explore the computational redundancy part of the network, and then prune the redundancy blocks of the model and maintain the network performance through a progressive incubation strategy. Secondly, in order to maintaining the model performance, we add cross-layer multi-expert conditional convolution (CLME-Condconv) to the block pruning part to inherit the original convolution parameters. Thirdly, we propose a global-regional interactive (GRI) attention to speed up the computationally intensive attention part. Finally, we use semantic-aware supervision (SAS) to align the outputs of the teacher model and student model at the semantic level. Experiments show that this method can effectively train a lightweight model close to the performance of the original SD model, and effectively improve the model speed under limited resources. Experiments show that the proposed method can effectively train a light-weight model close to the performance of the original SD model, and effectively improve the model speed under limited resources. After acceleration, the UNet part of the model is 22% faster and the overall speed is 19% faster.
Layer-adaptive Structured Pruning Guided by Latency
May 23, 2023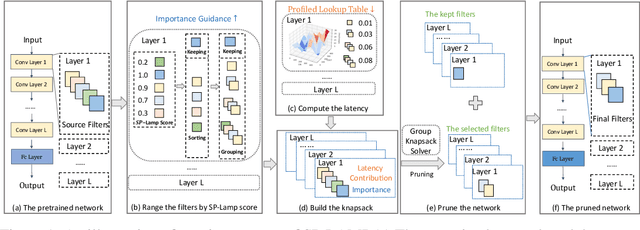
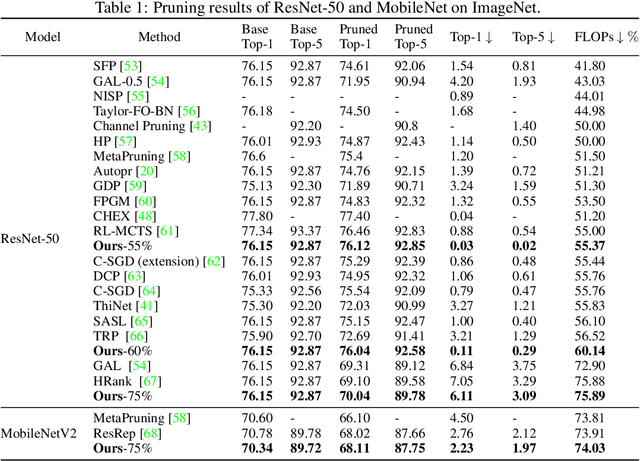
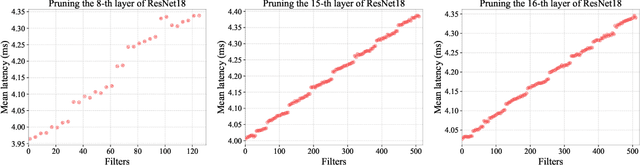
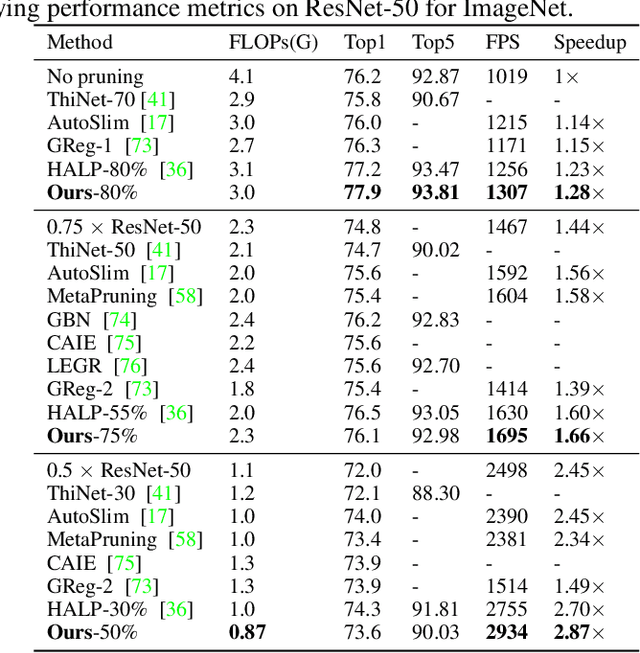
Structured pruning can simplify network architecture and improve inference speed. Combined with the underlying hardware and inference engine in which the final model is deployed, better results can be obtained by using latency collaborative loss function to guide network pruning together. Existing pruning methods that optimize latency have demonstrated leading performance, however, they often overlook the hardware features and connection in the network. To address this problem, we propose a global importance score SP-LAMP(Structured Pruning Layer-Adaptive Magnitude-based Pruning) by deriving a global importance score LAMP from unstructured pruning to structured pruning. In SP-LAMP, each layer includes a filter with an SP-LAMP score of 1, and the remaining filters are grouped. We utilize a group knapsack solver to maximize the SP-LAMP score under latency constraints. In addition, we improve the strategy of collect the latency to make it more accurate. In particular, for ResNet50/ResNet18 on ImageNet and CIFAR10, SP-LAMP is 1.28x/8.45x faster with +1.7%/-1.57% top-1 accuracy changed, respectively. Experimental results in ResNet56 on CIFAR10 demonstrate that our algorithm achieves lower latency compared to alternative approaches while ensuring accuracy and FLOPs.
Fine-tuning Pruned Networks with Linear Over-parameterization
Apr 25, 2022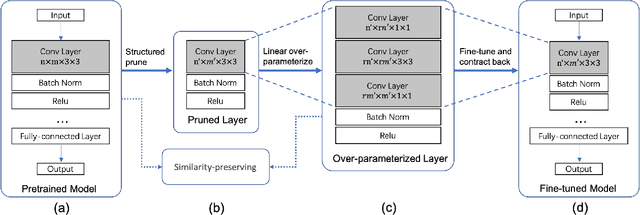
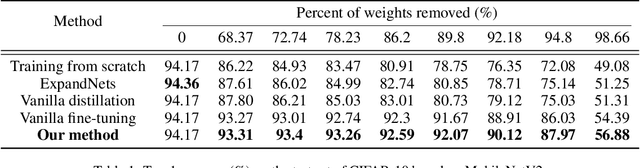
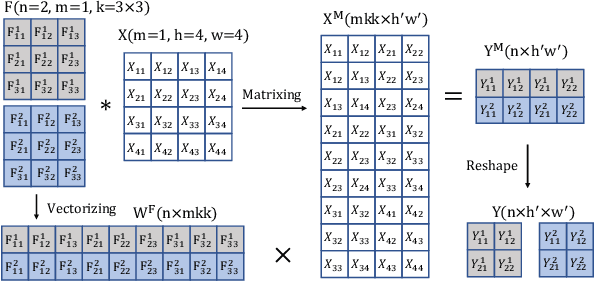
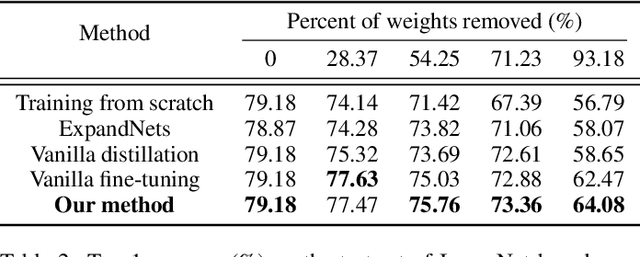
Structured pruning compresses neural networks by reducing channels (filters) for fast inference and low footprint at run-time. To restore accuracy after pruning, fine-tuning is usually applied to pruned networks. However, too few remaining parameters in pruned networks inevitably bring a great challenge to fine-tuning to restore accuracy. To address this challenge, we propose a novel method that first linearly over-parameterizes the compact layers in pruned networks to enlarge the number of fine-tuning parameters and then re-parameterizes them to the original layers after fine-tuning. Specifically, we equivalently expand the convolution/linear layer with several consecutive convolution/linear layers that do not alter the current output feature maps. Furthermore, we utilize similarity-preserving knowledge distillation that encourages the over-parameterized block to learn the immediate data-to-data similarities of the corresponding dense layer to maintain its feature learning ability. The proposed method is comprehensively evaluated on CIFAR-10 and ImageNet which significantly outperforms the vanilla fine-tuning strategy, especially for large pruning ratio.
Wavelet Knowledge Distillation: Towards Efficient Image-to-Image Translation
Mar 12, 2022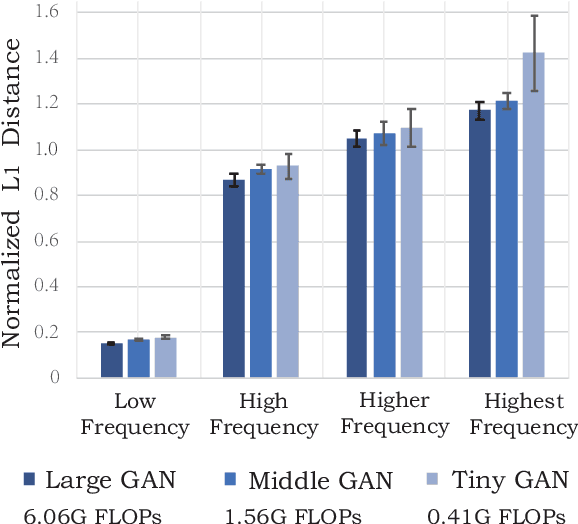
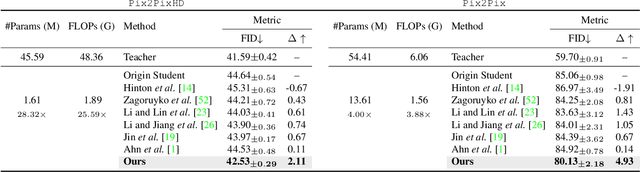
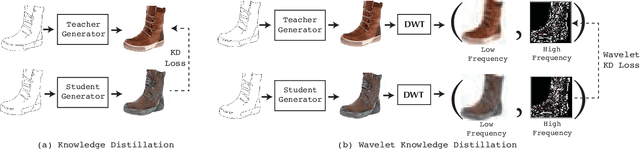
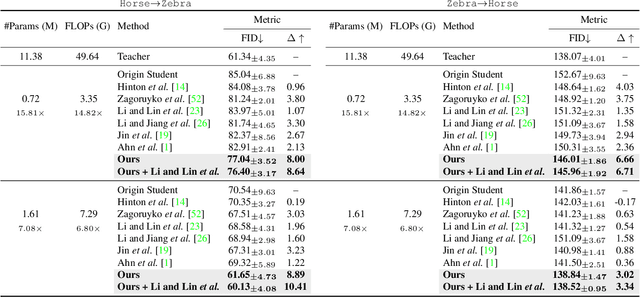
Remarkable achievements have been attained with Generative Adversarial Networks (GANs) in image-to-image translation. However, due to a tremendous amount of parameters, state-of-the-art GANs usually suffer from low efficiency and bulky memory usage. To tackle this challenge, firstly, this paper investigates GANs performance from a frequency perspective. The results show that GANs, especially small GANs lack the ability to generate high-quality high frequency information. To address this problem, we propose a novel knowledge distillation method referred to as wavelet knowledge distillation. Instead of directly distilling the generated images of teachers, wavelet knowledge distillation first decomposes the images into different frequency bands with discrete wavelet transformation and then only distills the high frequency bands. As a result, the student GAN can pay more attention to its learning on high frequency bands. Experiments demonstrate that our method leads to 7.08 times compression and 6.80 times acceleration on CycleGAN with almost no performance drop. Additionally, we have studied the relation between discriminators and generators which shows that the compression of discriminators can promote the performance of compressed generators.
N3H-Core: Neuron-designed Neural Network Accelerator via FPGA-based Heterogeneous Computing Cores
Dec 15, 2021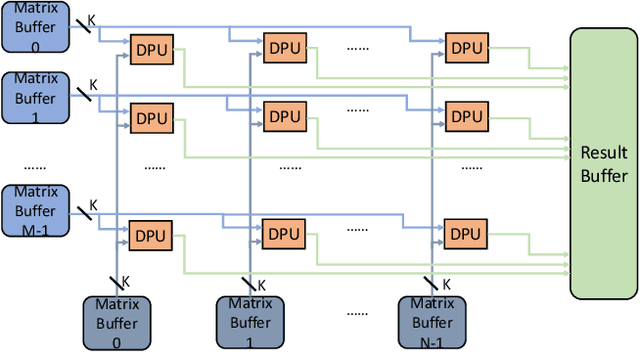
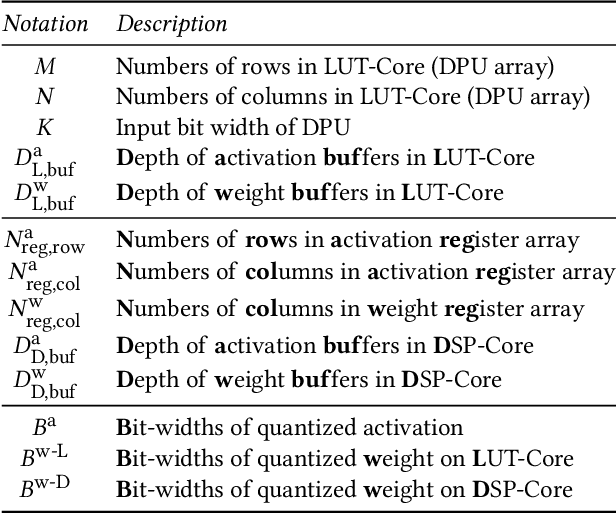
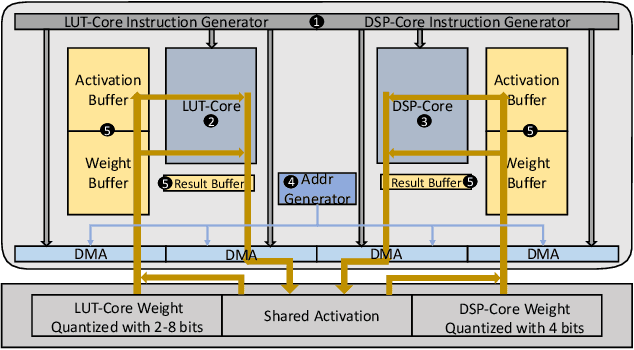
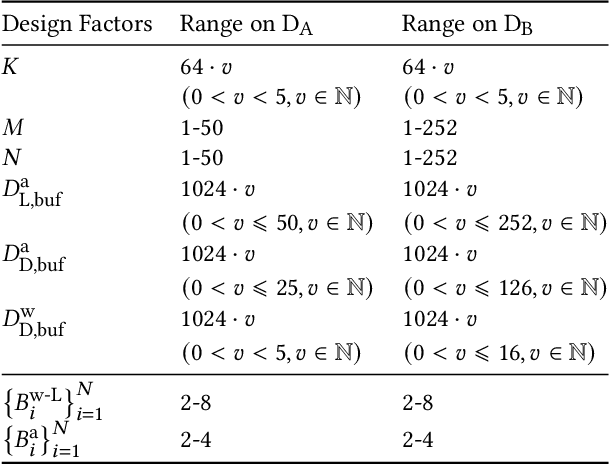
Accelerating the neural network inference by FPGA has emerged as a popular option, since the reconfigurability and high performance computing capability of FPGA intrinsically satisfies the computation demand of the fast-evolving neural algorithms. However, the popular neural accelerators on FPGA (e.g., Xilinx DPU) mainly utilize the DSP resources for constructing their processing units, while the rich LUT resources are not well exploited. Via the software-hardware co-design approach, in this work, we develop an FPGA-based heterogeneous computing system for neural network acceleration. From the hardware perspective, the proposed accelerator consists of DSP- and LUT-based GEneral Matrix-Multiplication (GEMM) computing cores, which forms the entire computing system in a heterogeneous fashion. The DSP- and LUT-based GEMM cores are computed w.r.t a unified Instruction Set Architecture (ISA) and unified buffers. Along the data flow of the neural network inference path, the computation of the convolution/fully-connected layer is split into two portions, handled by the DSP- and LUT-based GEMM cores asynchronously. From the software perspective, we mathematically and systematically model the latency and resource utilization of the proposed heterogeneous accelerator, regarding varying system design configurations. Through leveraging the reinforcement learning technique, we construct a framework to achieve end-to-end selection and optimization of the design specification of target heterogeneous accelerator, including workload split strategy, mixed-precision quantization scheme, and resource allocation of DSP- and LUT-core. In virtue of the proposed design framework and heterogeneous computing system, our design outperforms the state-of-the-art Mix&Match design with latency reduced by 1.12-1.32x with higher inference accuracy. The N3H-core is open-sourced at: https://github.com/elliothe/N3H_Core.