 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-adaptive Structured Pruning Guided by Latency
Paper and Code
May 23, 2023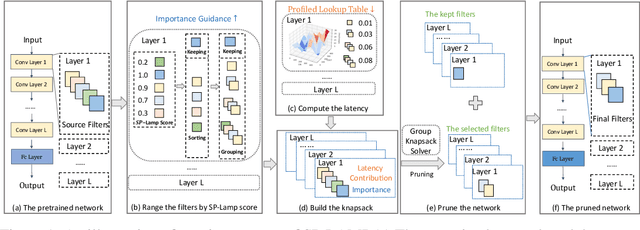
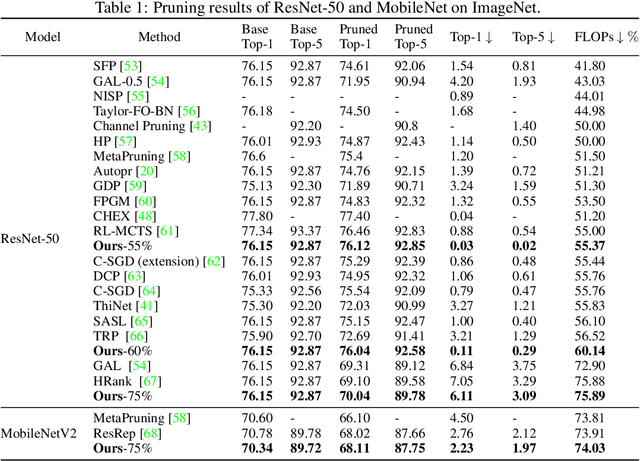
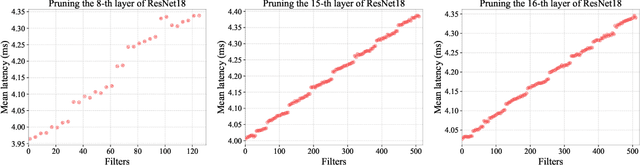
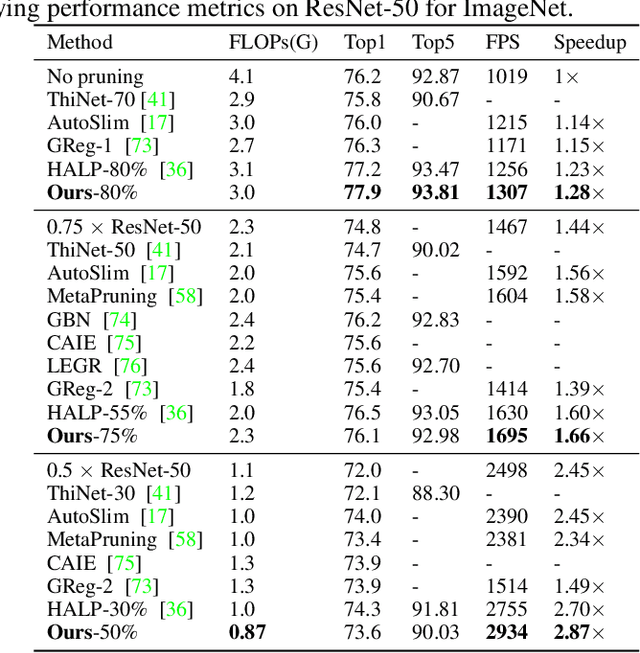
Structured pruning can simplify network architecture and improve inference speed. Combined with the underlying hardware and inference engine in which the final model is deployed, better results can be obtained by using latency collaborative loss function to guide network pruning together. Existing pruning methods that optimize latency have demonstrated leading performance, however, they often overlook the hardware features and connection in the network. To address this problem, we propose a global importance score SP-LAMP(Structured Pruning Layer-Adaptive Magnitude-based Pruning) by deriving a global importance score LAMP from unstructured pruning to structured pruning. In SP-LAMP, each layer includes a filter with an SP-LAMP score of 1, and the remaining filters are grouped. We utilize a group knapsack solver to maximize the SP-LAMP score under latency constraints. In addition, we improve the strategy of collect the latency to make it more accurate. In particular, for ResNet50/ResNet18 on ImageNet and CIFAR10, SP-LAMP is 1.28x/8.45x faster with +1.7%/-1.57% top-1 accuracy changed, respectively. Experimental results in ResNet56 on CIFAR10 demonstrate that our algorithm achieves lower latency compared to alternative approaches while ensuring accuracy and FLOPs.