 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Four Principles for Physically Interpretable World Models
Mar 04, 2025


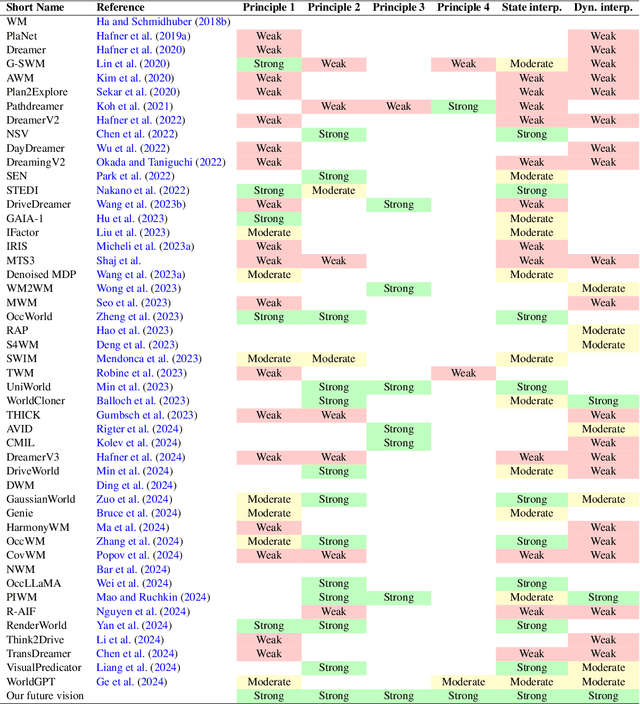
As autonomous systems are increasingly deployed in open and uncertain settings, there is a growing need for trustworthy world models that can reliably predict future high-dimensional observations. The learned latent representations in world models lack direct mapping to meaningful physical quantities and dynamics, limiting their utility and interpretability in downstream planning, control, and safety verification. In this paper, we argue for a fundamental shift from physically informed to physically interpretable world models - and crystallize four principles that leverage symbolic knowledge to achieve these ends: (1) structuring latent spaces according to the physical intent of variables, (2) learning aligned invariant and equivariant representations of the physical world, (3) adapting training to the varied granularity of supervision signals, and (4) partitioning generative outputs to support scalability and verifiability. We experimentally demonstrate the value of each principle on two benchmarks. This paper opens several intriguing research directions to achieve and capitalize on full physical interpretability in world models.
A-SDM: Accelerating Stable Diffusion through Redundancy Removal and Performance Optimization
Dec 27, 2023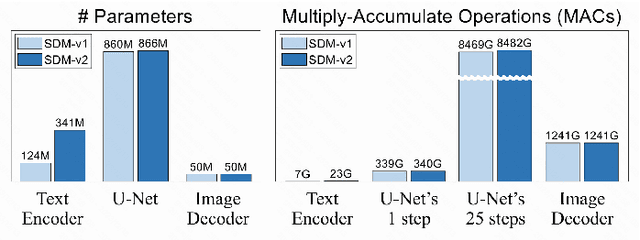
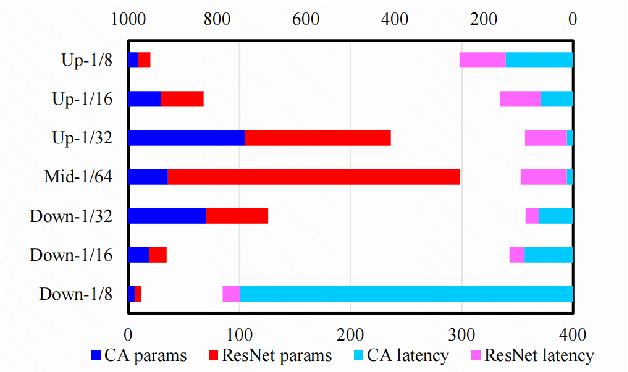
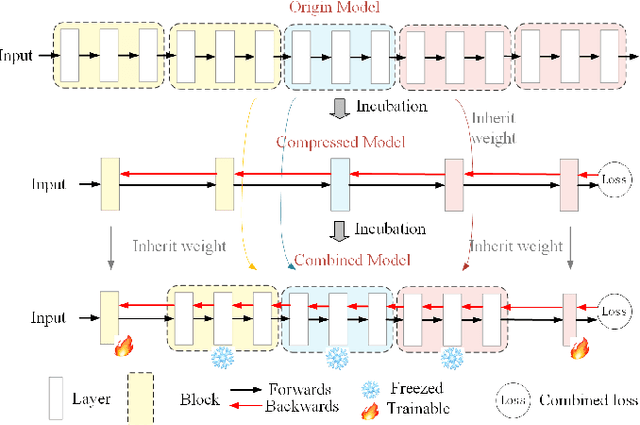
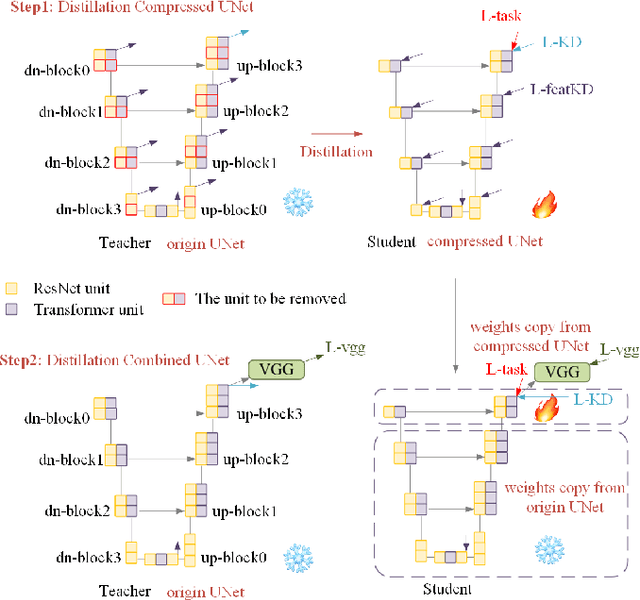
The Stable Diffusion Model (SDM) is a popular and efficient text-to-image (t2i) generation and image-to-image (i2i) generation model. Although there have been some attempts to reduce sampling steps, model distillation, and network quantization, these previous methods generally retain the original network architecture. Billion scale parameters and high computing requirements make the research of model architecture adjustment scarce. In this work, we first explore the computational redundancy part of the network, and then prune the redundancy blocks of the model and maintain the network performance through a progressive incubation strategy. Secondly, in order to maintaining the model performance, we add cross-layer multi-expert conditional convolution (CLME-Condconv) to the block pruning part to inherit the original convolution parameters. Thirdly, we propose a global-regional interactive (GRI) attention to speed up the computationally intensive attention part. Finally, we use semantic-aware supervision (SAS) to align the outputs of the teacher model and student model at the semantic level. Experiments show that this method can effectively train a lightweight model close to the performance of the original SD model, and effectively improve the model speed under limited resources. Experiments show that the proposed method can effectively train a light-weight model close to the performance of the original SD model, and effectively improve the model speed under limited resources. After acceleration, the UNet part of the model is 22% faster and the overall speed is 19% faster.
Layer-adaptive Structured Pruning Guided by Latency
May 23, 2023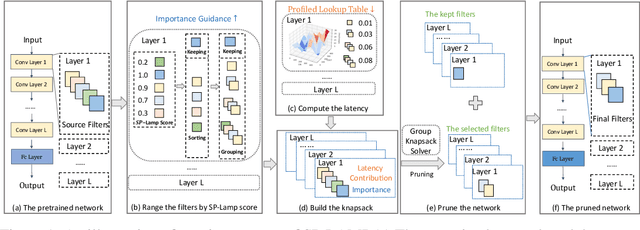
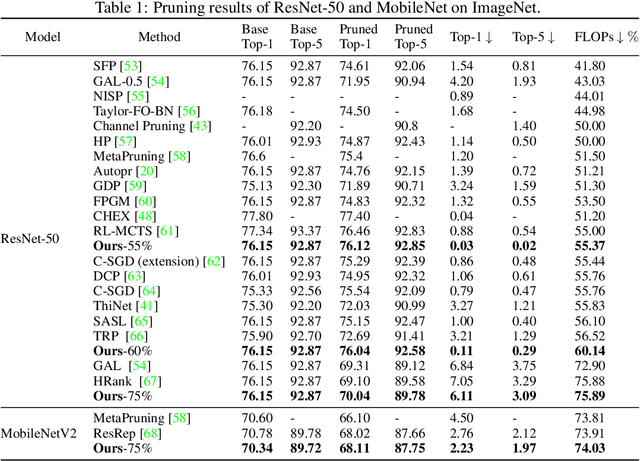
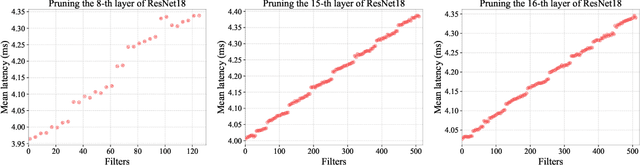
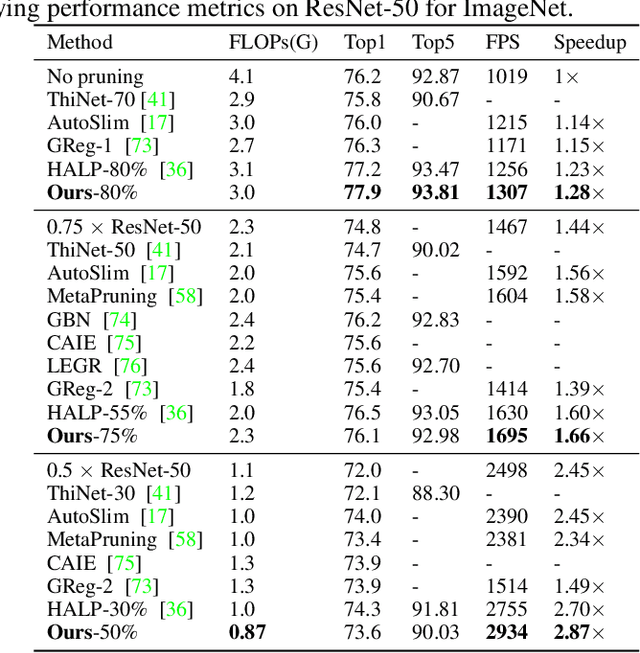
Structured pruning can simplify network architecture and improve inference speed. Combined with the underlying hardware and inference engine in which the final model is deployed, better results can be obtained by using latency collaborative loss function to guide network pruning together. Existing pruning methods that optimize latency have demonstrated leading performance, however, they often overlook the hardware features and connection in the network. To address this problem, we propose a global importance score SP-LAMP(Structured Pruning Layer-Adaptive Magnitude-based Pruning) by deriving a global importance score LAMP from unstructured pruning to structured pruning. In SP-LAMP, each layer includes a filter with an SP-LAMP score of 1, and the remaining filters are grouped. We utilize a group knapsack solver to maximize the SP-LAMP score under latency constraints. In addition, we improve the strategy of collect the latency to make it more accurate. In particular, for ResNet50/ResNet18 on ImageNet and CIFAR10, SP-LAMP is 1.28x/8.45x faster with +1.7%/-1.57% top-1 accuracy changed, respectively. Experimental results in ResNet56 on CIFAR10 demonstrate that our algorithm achieves lower latency compared to alternative approaches while ensuring accuracy and FLOPs.
Augmentation-Aware Self-Supervision for Data-Efficient GAN Training
May 31, 2022
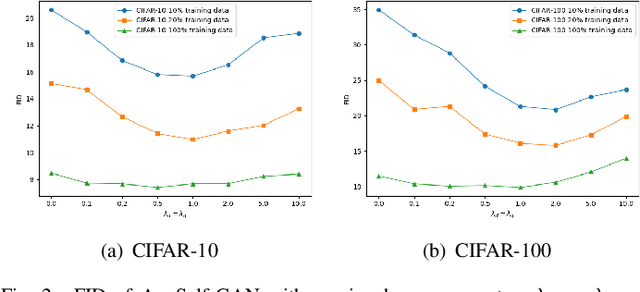

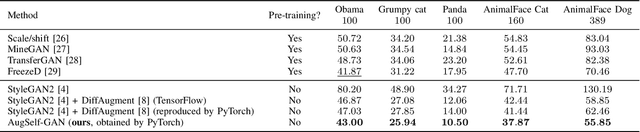
Training generative adversarial networks (GANs) with limited data is valuable but challenging because discriminators are prone to over-fitting in such situations. Recently proposed differentiable data augmentation techniques for discriminators demonstrate improved data efficiency of training GANs. However, the naive data augmentation introduces undesired invariance to augmentation into the discriminator. The invariance may degrade the representation learning ability of the discriminator, thereby affecting the generative modeling performance of the generator. To mitigate the invariance while inheriting the benefits of data augmentation, we propose a novel augmentation-aware self-supervised discriminator that predicts the parameter of augmentation given the augmented and original data. Moreover, the prediction task is required to distinguishable between real data and generated data since they are different during training. We further encourage the generator to learn from the proposed discriminator by generating augmentation-predictable real data. We compare the proposed method with state-of-the-arts across the class-conditional BigGAN and unconditional StyleGAN2 architectures on CIFAR-10/100 and several low-shot datasets, respectively. Experimental results show a significantly improved generation performance of our method over competing methods for training data-efficient GANs.
Fine-tuning Pruned Networks with Linear Over-parameterization
Apr 25, 2022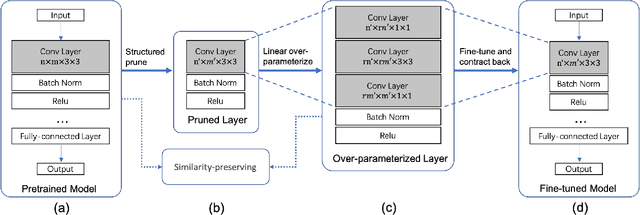
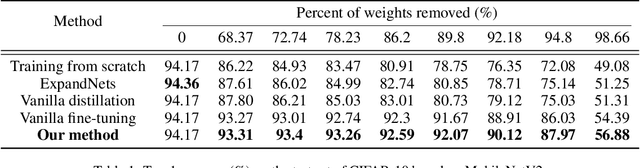
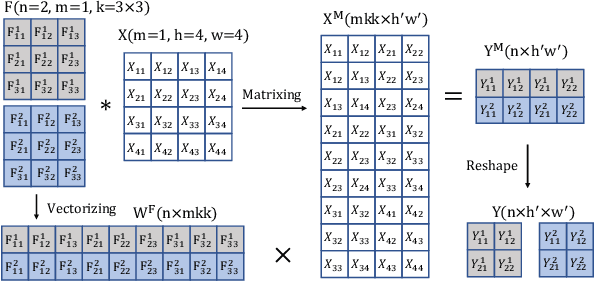
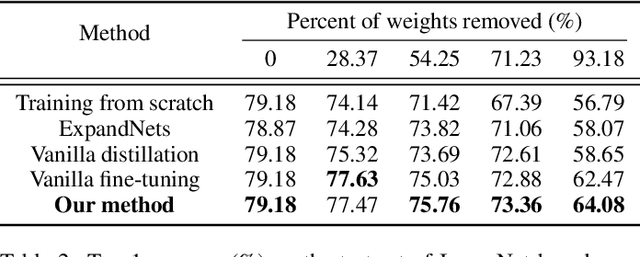
Structured pruning compresses neural networks by reducing channels (filters) for fast inference and low footprint at run-time. To restore accuracy after pruning, fine-tuning is usually applied to pruned networks. However, too few remaining parameters in pruned networks inevitably bring a great challenge to fine-tuning to restore accuracy. To address this challenge, we propose a novel method that first linearly over-parameterizes the compact layers in pruned networks to enlarge the number of fine-tuning parameters and then re-parameterizes them to the original layers after fine-tuning. Specifically, we equivalently expand the convolution/linear layer with several consecutive convolution/linear layers that do not alter the current output feature maps. Furthermore, we utilize similarity-preserving knowledge distillation that encourages the over-parameterized block to learn the immediate data-to-data similarities of the corresponding dense layer to maintain its feature learning ability. The proposed method is comprehensively evaluated on CIFAR-10 and ImageNet which significantly outperforms the vanilla fine-tuning strategy, especially for large pruning ratio.