 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unified Probabilistic Verification and Validation of Vision-Based Autonomy
Aug 19, 2025
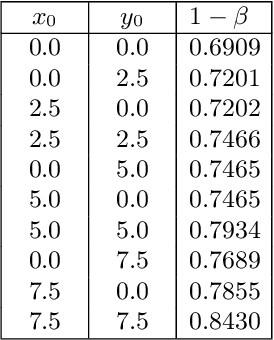
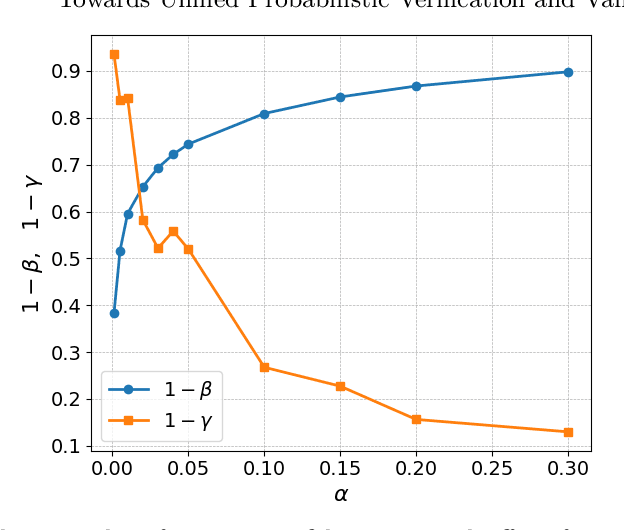
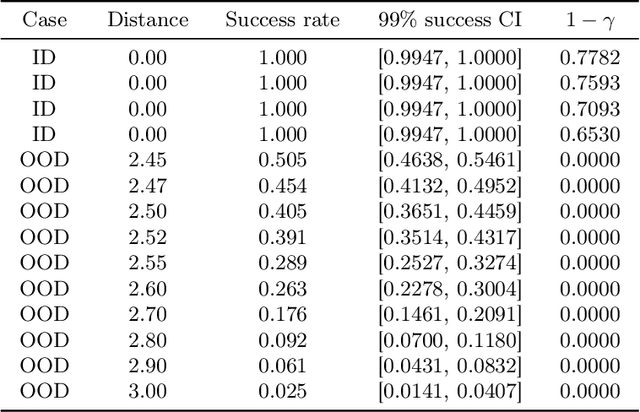
Precise and comprehensive situational awareness is a critical capability of modern autonomous systems. Deep neural networks that perceive task-critical details from rich sensory signals have become ubiquitous; however, their black-box behavior and sensitivity to environmental uncertainty and distribution shifts make them challenging to verify formally. Abstraction-based verification techniques for vision-based autonomy produce safety guarantees contingent on rigid assumptions, such as bounded errors or known unique distributions. Such overly restrictive and inflexible assumptions limit the validity of the guarantees, especially in diverse and uncertain test-time environments. We propose a methodology that unifies the verification models of perception with their offline validation. Our methodology leverages interval MDPs and provides a flexible end-to-end guarantee that adapts directly to the out-of-distribution test-time conditions. We evaluate our methodology on a synthetic perception Markov chain with well-defined state estimation distributions and a mountain car benchmark. Our findings reveal that we can guarantee tight yet rigorous bounds on overall system safety.
Four Principles for Physically Interpretable World Models
Mar 04, 2025


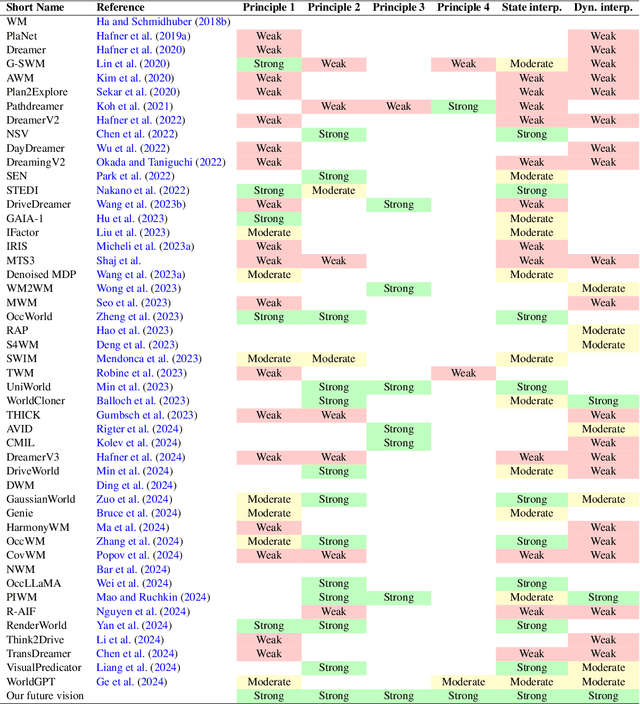
As autonomous systems are increasingly deployed in open and uncertain settings, there is a growing need for trustworthy world models that can reliably predict future high-dimensional observations. The learned latent representations in world models lack direct mapping to meaningful physical quantities and dynamics, limiting their utility and interpretability in downstream planning, control, and safety verification. In this paper, we argue for a fundamental shift from physically informed to physically interpretable world models - and crystallize four principles that leverage symbolic knowledge to achieve these ends: (1) structuring latent spaces according to the physical intent of variables, (2) learning aligned invariant and equivariant representations of the physical world, (3) adapting training to the varied granularity of supervision signals, and (4) partitioning generative outputs to support scalability and verifiability. We experimentally demonstrate the value of each principle on two benchmarks. This paper opens several intriguing research directions to achieve and capitalize on full physical interpretability in world models.