 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Confidence Chain: Temporal-Aware Uncertainty Quantification in Large Language Models
Jan 19, 2026As reasoning modules, such as the chain-of-thought mechanism, are applied to large language models, they achieve strong performance on various tasks such as answering common-sense questions and solving math problems. The main challenge now is to assess the uncertainty of answers, which can help prevent misleading or serious hallucinations for users. Although current methods analyze long reasoning sequences by filtering unrelated tokens and examining potential connections between nearby tokens or sentences, the temporal spread of confidence is often overlooked. This oversight can lead to inflated overall confidence, even when earlier steps exhibit very low confidence. To address this issue, we propose a novel method that incorporates inter-step attention to analyze semantic correlations across steps. For handling long-horizon responses, we introduce a hidden confidence mechanism to retain historical confidence information, which is then combined with stepwise confidence to produce a more accurate overall estimate. We evaluate our method on the GAOKAO math benchmark and the CLadder causal reasoning dataset using mainstream open-source large language models. Our approach is shown to outperform state-of-the-art methods by achieving a superior balance between predictive quality and calibration, demonstrated by strong performance on both Negative Log-Likelihood and Expected Calibration Error.
Confidence over Time: Confidence Calibration with Temporal Logic for Large Language Model Reasoning
Jan 19, 2026Large Language Models (LLMs) increasingly rely on long-form, multi-step reasoning to solve complex tasks such as mathematical problem solving and scientific question answering. Despite strong performance, existing confidence estimation methods typically reduce an entire reasoning process to a single scalar score, ignoring how confidence evolves throughout the generation. As a result, these methods are often sensitive to superficial factors such as response length or verbosity, and struggle to distinguish correct reasoning from confidently stated errors. We propose to characterize the stepwise confidence signal using Signal Temporal Logic (STL). Using a discriminative STL mining procedure, we discover temporal formulas that distinguish confidence signals of correct and incorrect responses. Our analysis found that the STL patterns generalize across tasks, and numeric parameters exhibit sensitivity to individual questions. Based on these insights, we develop a confidence estimation approach that informs STL blocks with parameter hypernetworks. Experiments on multiple reasoning tasks show our confidence scores are more calibrated than the baselines.
Temporalizing Confidence: Evaluation of Chain-of-Thought Reasoning with Signal Temporal Logic
Jun 09, 2025Large Language Models (LLMs) have shown impressive performance in mathematical reasoning tasks when guided by Chain-of-Thought (CoT) prompting. However, they tend to produce highly confident yet incorrect outputs, which poses significant risks in domains like education, where users may lack the expertise to assess reasoning steps. To address this, we propose a structured framework that models stepwise confidence as a temporal signal and evaluates it using Signal Temporal Logic (STL). In particular, we define formal STL-based constraints to capture desirable temporal properties and compute robustness scores that serve as structured, interpretable confidence estimates. Our approach also introduces a set of uncertainty reshaping strategies to enforce smoothness, monotonicity, and causal consistency across the reasoning trajectory. Experiments show that our approach consistently improves calibration metrics and provides more reliable uncertainty estimates than conventional confidence aggregation and post-hoc calibration.
Generalizable Image Repair for Robust Visual Autonomous Racing
Mar 07, 2025
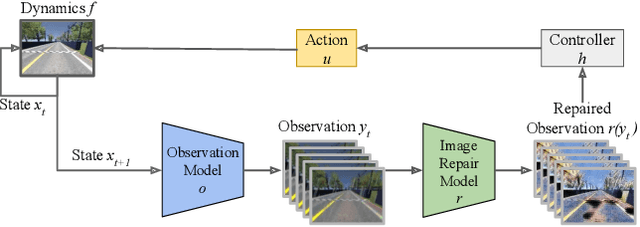
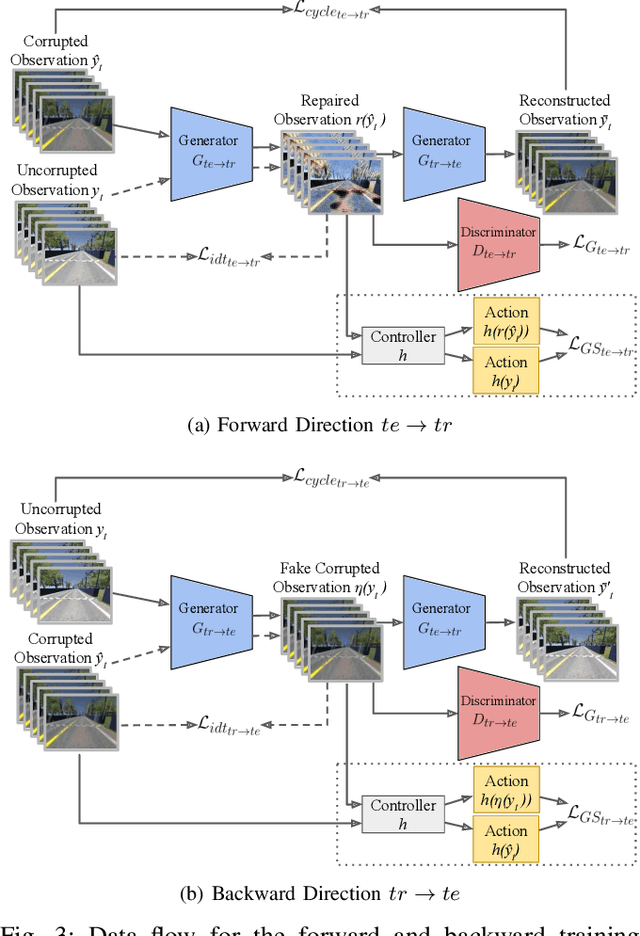

Vision-based autonomous racing relies on accurate perception for robust control. However, image distribution changes caused by sensor noise, adverse weather, and dynamic lighting can degrade perception, leading to suboptimal control decisions. Existing approaches, including domain adaptation and adversarial training, improve robustness but struggle to generalize to unseen corruptions while introducing computational overhead. To address this challenge, we propose a real-time image repair module that restores corrupted images before they are used by the controller. Our method leverages generative adversarial models, specifically CycleGAN and pix2pix, for image repair. CycleGAN enables unpaired image-to-image translation to adapt to novel corruptions, while pix2pix exploits paired image data when available to improve the quality. To ensure alignment with control performance, we introduce a control-focused loss function that prioritizes perceptual consistency in repaired images. We evaluated our method in a simulated autonomous racing environment with various visual corruptions. The results show that our approach significantly improves performance compared to baselines, mitigating distribution shift and enhancing controller reliability.
Four Principles for Physically Interpretable World Models
Mar 04, 2025


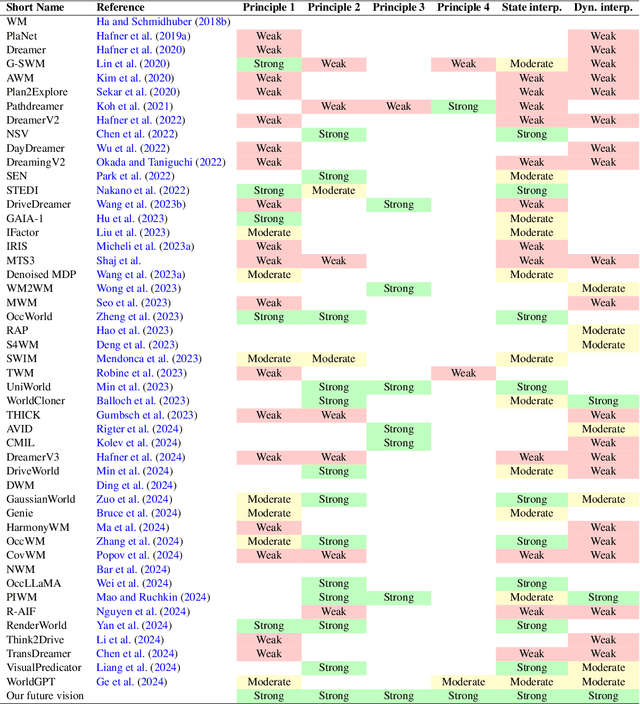
As autonomous systems are increasingly deployed in open and uncertain settings, there is a growing need for trustworthy world models that can reliably predict future high-dimensional observations. The learned latent representations in world models lack direct mapping to meaningful physical quantities and dynamics, limiting their utility and interpretability in downstream planning, control, and safety verification. In this paper, we argue for a fundamental shift from physically informed to physically interpretable world models - and crystallize four principles that leverage symbolic knowledge to achieve these ends: (1) structuring latent spaces according to the physical intent of variables, (2) learning aligned invariant and equivariant representations of the physical world, (3) adapting training to the varied granularity of supervision signals, and (4) partitioning generative outputs to support scalability and verifiability. We experimentally demonstrate the value of each principle on two benchmarks. This paper opens several intriguing research directions to achieve and capitalize on full physical interpretability in world models.
Towards Physically Interpretable World Models: Meaningful Weakly Supervised Representations for Visual Trajectory Prediction
Dec 17, 2024Deep learning models are increasingly employed for perception, prediction, and control in complex systems. Embedding physical knowledge into these models is crucial for achieving realistic and consistent outputs, a challenge often addressed by physics-informed machine learning. However, integrating physical knowledge with representation learning becomes difficult when dealing with high-dimensional observation data, such as images, particularly under conditions of incomplete or imprecise state information. To address this, we propose Physically Interpretable World Models, a novel architecture that aligns learned latent representations with real-world physical quantities. Our method combines a variational autoencoder with a dynamical model that incorporates unknown system parameters, enabling the discovery of physically meaningful representations. By employing weak supervision with interval-based constraints, our approach eliminates the reliance on ground-truth physical annotations. Experimental results demonstrate that our method improves the quality of learned representations while achieving accurate predictions of future states, advancing the field of representation learning in dynamic systems.
Language-Enhanced Latent Representations for Out-of-Distribution Detection in Autonomous Driving
May 02, 2024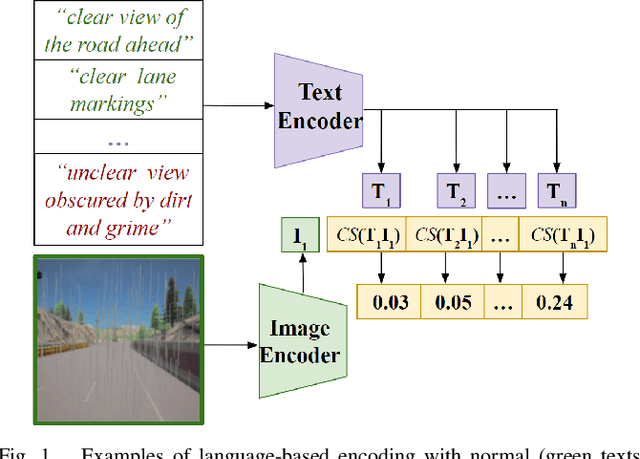


Out-of-distribution (OOD) detection is essential in autonomous driving, to determine when learning-based components encounter unexpected inputs. Traditional detectors typically use encoder models with fixed settings, thus lacking effective human interaction capabilities. With the rise of large foundation models, multimodal inputs offer the possibility of taking human language as a latent representation, thus enabling language-defined OOD detection. In this paper, we use the cosine similarity of image and text representations encoded by the multimodal model CLIP as a new representation to improve the transparency and controllability of latent encodings used for visual anomaly detection. We compare our approach with existing pre-trained encoders that can only produce latent representations that are meaningless from the user's standpoint. Our experiments on realistic driving data show that the language-based latent representation performs better than the traditional representation of the vision encoder and helps improve the detection performance when combined with standard representations.
Zero-shot Safety Prediction for Autonomous Robots with Foundation World Models
Apr 02, 2024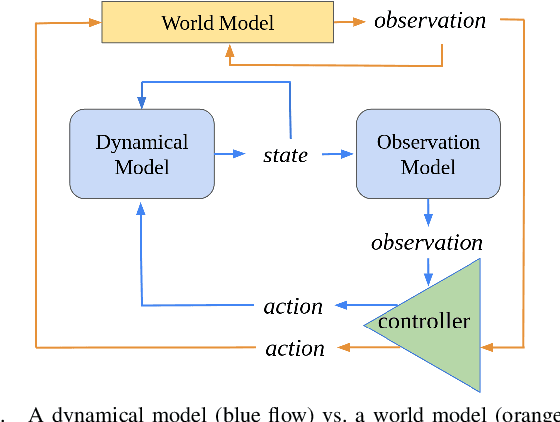



A world model creates a surrogate world to train a controller and predict safety violations by learning the internal dynamic model of systems. However, the existing world models rely solely on statistical learning of how observations change in response to actions, lacking precise quantification of how accurate the surrogate dynamics are, which poses a significant challenge in safety-critical systems. To address this challenge, we propose foundation world models that embed observations into meaningful and causally latent representations. This enables the surrogate dynamics to directly predict causal future states by leveraging a training-free large language model. In two common benchmarks, this novel model outperforms standard world models in the safety prediction task and has a performance comparable to supervised learning despite not using any data. We evaluate its performance with a more specialized and system-relevant metric by comparing estimated states instead of aggregating observation-wide error.
How Safe Am I Given What I See? Calibrated Prediction of Safety Chances for Image-Controlled Autonomy
Aug 23, 2023



End-to-end learning has emerged as a major paradigm for developing autonomous systems. Unfortunately, with its performance and convenience comes an even greater challenge of safety assurance. A key factor of this challenge is the absence of the notion of a low-dimensional and interpretable dynamical state, around which traditional assurance methods revolve. Focusing on the online safety prediction problem, this paper proposes a configurable family of learning pipelines based on generative world models, which do not require low-dimensional states. To implement these pipelines, we overcome the challenges of learning safety-informed latent representations and missing safety labels under prediction-induced distribution shift. These pipelines come with statistical calibration guarantees on their safety chance predictions based on conformal prediction. We perform an extensive evaluation of the proposed learning pipelines on two case studies of image-controlled systems: a racing car and a cartpole.