 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCo: Code as CoT for Text-to-Image Preview and Rare Concept Generation
Mar 09, 2026Recent advancements in Unified Multimodal Models (UMMs) have significantly advanced text-to-image (T2I) generation, particularly through the integration of Chain-of-Thought (CoT) reasoning. However, existing CoT-based T2I methods largely rely on abstract natural-language planning, which lacks the precision required for complex spatial layouts, structured visual elements, and dense textual content. In this work, we propose CoCo (Code-as-CoT), a code-driven reasoning framework that represents the reasoning process as executable code, enabling explicit and verifiable intermediate planning for image generation. Given a text prompt, CoCo first generates executable code that specifies the structural layout of the scene, which is then executed in a sandboxed environment to render a deterministic draft image. The model subsequently refines this draft through fine-grained image editing to produce the final high-fidelity result. To support this training paradigm, we construct CoCo-10K, a curated dataset containing structured draft-final image pairs designed to teach both structured draft construction and corrective visual refinement. Empirical evaluations on StructT2IBench, OneIG-Bench, and LongText-Bench show that CoCo achieves improvements of +68.83%, +54.8%, and +41.23% over direct generation, while also outperforming other generation methods empowered by CoT. These results demonstrate that executable code is an effective and reliable reasoning paradigm for precise, controllable, and structured text-to-image generation. The code is available at: https://github.com/micky-li-hd/CoCo
GAZEploit: Remote Keystroke Inference Attack by Gaze Estimation from Avatar Views in VR/MR Devices
Sep 12, 2024
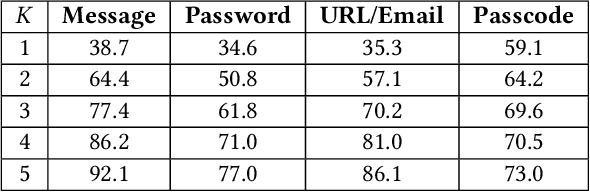


The advent and growing popularity of Virtual Reality (VR) and Mixed Reality (MR) solutions have revolutionized the way we interact with digital platforms. The cutting-edge gaze-controlled typing methods, now prevalent in high-end models of these devices, e.g., Apple Vision Pro, have not only improved user experience but also mitigated traditional keystroke inference attacks that relied on hand gestures, head movements and acoustic side-channels. However, this advancement has paradoxically given birth to a new, potentially more insidious cyber threat, GAZEploit. In this paper, we unveil GAZEploit, a novel eye-tracking based attack specifically designed to exploit these eye-tracking information by leveraging the common use of virtual appearances in VR applications. This widespread usage significantly enhances the practicality and feasibility of our attack compared to existing methods. GAZEploit takes advantage of this vulnerability to remotely extract gaze estimations and steal sensitive keystroke information across various typing scenarios-including messages, passwords, URLs, emails, and passcodes. Our research, involving 30 participants, achieved over 80% accuracy in keystroke inference. Alarmingly, our study also identified over 15 top-rated apps in the Apple Store as vulnerable to the GAZEploit attack, emphasizing the urgent need for bolstered security measures for this state-of-the-art VR/MR text entry method.
Zero-shot Safety Prediction for Autonomous Robots with Foundation World Models
Apr 02, 2024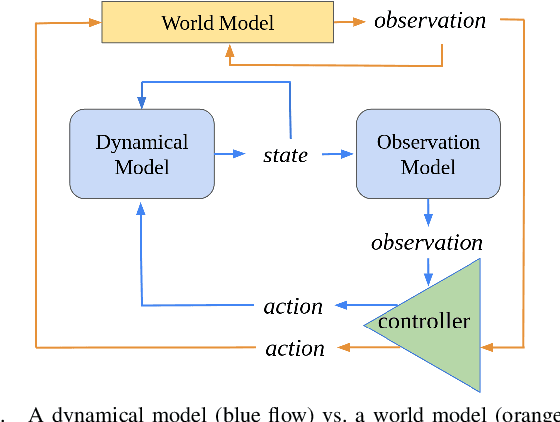



A world model creates a surrogate world to train a controller and predict safety violations by learning the internal dynamic model of systems. However, the existing world models rely solely on statistical learning of how observations change in response to actions, lacking precise quantification of how accurate the surrogate dynamics are, which poses a significant challenge in safety-critical systems. To address this challenge, we propose foundation world models that embed observations into meaningful and causally latent representations. This enables the surrogate dynamics to directly predict causal future states by leveraging a training-free large language model. In two common benchmarks, this novel model outperforms standard world models in the safety prediction task and has a performance comparable to supervised learning despite not using any data. We evaluate its performance with a more specialized and system-relevant metric by comparing estimated states instead of aggregating observation-wide error.
CLeaRForecast: Contrastive Learning of High-Purity Representations for Time Series Forecasting
Dec 10, 2023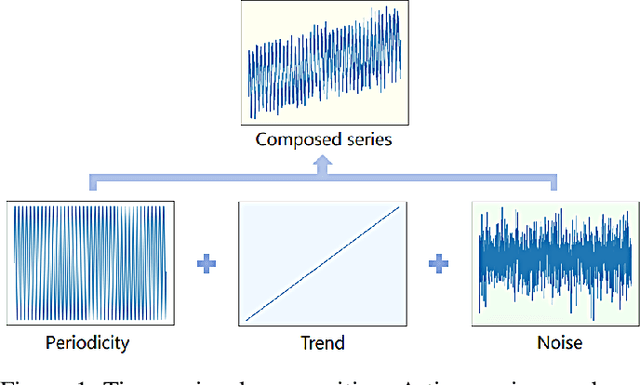
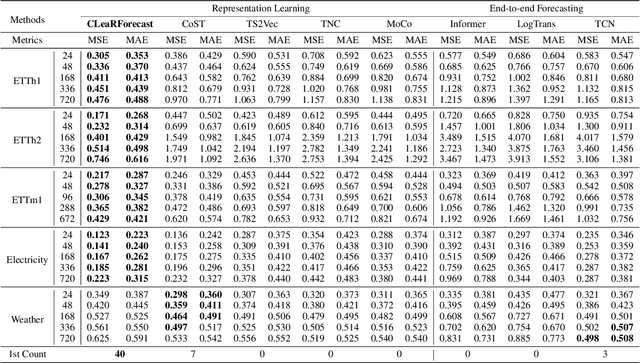
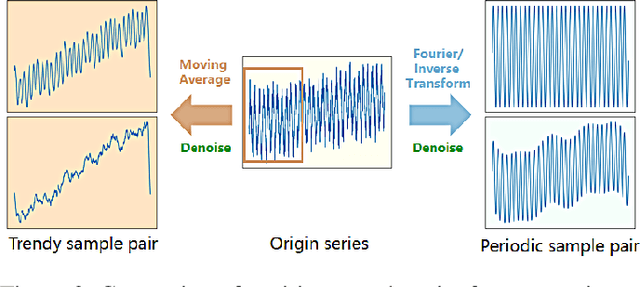
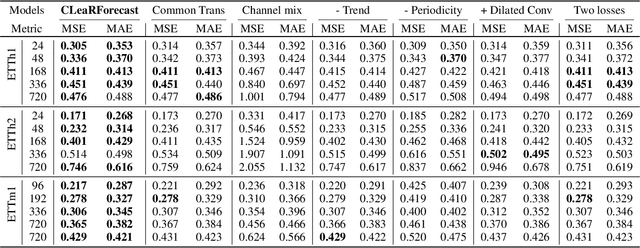
Time series forecasting (TSF) holds significant importance in modern society, spanning numerous domains. Previous representation learning-based TSF algorithms typically embrace a contrastive learning paradigm featuring segregated trend-periodicity representations. Yet, these methodologies disregard the inherent high-impact noise embedded within time series data, resulting in representation inaccuracies and seriously demoting the forecasting performance. To address this issue, we propose CLeaRForecast, a novel contrastive learning framework to learn high-purity time series representations with proposed sample, feature, and architecture purifying methods. More specifically, to avoid more noise adding caused by the transformations of original samples (series), transformations are respectively applied for trendy and periodic parts to provide better positive samples with obviously less noise. Moreover, we introduce a channel independent training manner to mitigate noise originating from unrelated variables in the multivariate series. By employing a streamlined deep-learning backbone and a comprehensive global contrastive loss function, we prevent noise introduction due to redundant or uneven learning of periodicity and trend. Experimental results show the superior performance of CLeaRForecast in various downstream TSF tasks.