 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENSR: Symbolic Regression Based in Equation Generative Space
Feb 24, 2026Symbolic Regression (SR) tries to reveal the hidden equations behind observed data. However, most methods search within a discrete equation space, where the structural modifications of equations rarely align with their numerical behavior, leaving fitting error feedback too noisy to guide exploration. To address this challenge, we propose GenSR, a generative latent space-based SR framework following the `map construction -> coarse localization -> fine search'' paradigm. Specifically, GenSR first pretrains a dual-branch Conditional Variational Autoencoder (CVAE) to reparameterize symbolic equations into a generative latent space with symbolic continuity and local numerical smoothness. This space can be regarded as a well-structured `map'' of the equation space, providing directional signals for search. At inference, the CVAE coarsely localizes the input data to promising regions in the latent space. Then, a modified CMA-ES refines the candidate region, leveraging smooth latent gradients. From a Bayesian perspective, GenSR reframes the SR task as maximizing the conditional distribution $p(\mathrm{Equ.} \mid \mathrm{Num.})$, with CVAE training achieving this objective through the Evidence Lower Bound (ELBO). This new perspective provides a theoretical guarantee for the effectiveness of GenSR. Extensive experiments show that GenSR jointly optimizes predictive accuracy, expression simplicity, and computational efficiency, while remaining robust under noise.
Uni-Retrieval: A Multi-Style Retrieval Framework for STEM's Education
Feb 09, 2025In AI-facilitated teaching, leveraging various query styles to interpret abstract text descriptions is crucial for ensuring high-quality teaching. However, current retrieval models primarily focus on natural text-image retrieval, making them insufficiently tailored to educational scenarios due to the ambiguities in the retrieval process. In this paper, we propose a diverse expression retrieval task tailored to educational scenarios, supporting retrieval based on multiple query styles and expressions. We introduce the STEM Education Retrieval Dataset (SER), which contains over 24,000 query pairs of different styles, and the Uni-Retrieval, an efficient and style-diversified retrieval vision-language model based on prompt tuning. Uni-Retrieval extracts query style features as prototypes and builds a continuously updated Prompt Bank containing prompt tokens for diverse queries. This bank can updated during test time to represent domain-specific knowledge for different subject retrieval scenarios. Our framework demonstrates scalability and robustness by dynamically retrieving prompt tokens based on prototype similarity, effectively facilitating learning for unknown queries. Experimental results indicate that Uni-Retrieval outperforms existing retrieval models in most retrieval tasks. This advancement provides a scalable and precise solution for diverse educational needs.
Context-Alignment: Activating and Enhancing LLM Capabilities in Time Series
Jan 07, 2025



Recently, leveraging pre-trained Large Language Models (LLMs) for time series (TS) tasks has gained increasing attention, which involves activating and enhancing LLMs' capabilities. Many methods aim to activate LLMs' capabilities based on token-level alignment but overlook LLMs' inherent strength on natural language processing -- their deep understanding of linguistic logic and structure rather than superficial embedding processing. We propose Context-Alignment, a new paradigm that aligns TS with a linguistic component in the language environments familiar to LLMs to enable LLMs to contextualize and comprehend TS data, thereby activating their capabilities. Specifically, such context-level alignment comprises structural alignment and logical alignment, which is achieved by a Dual-Scale Context-Alignment GNNs (DSCA-GNNs) applied to TS-language multimodal inputs. Structural alignment utilizes dual-scale nodes to describe hierarchical structure in TS-language, enabling LLMs treat long TS data as a whole linguistic component while preserving intrinsic token features. Logical alignment uses directed edges to guide logical relationships, ensuring coherence in the contextual semantics. Demonstration examples prompt are employed to construct Demonstration Examples based Context-Alignment (DECA) following DSCA-GNNs framework. DECA can be flexibly and repeatedly integrated into various layers of pre-trained LLMs to improve awareness of logic and structure, thereby enhancing performance. Extensive experiments show the effectiveness of DECA and the importance of Context-Alignment across tasks, particularly in few-shot and zero-shot forecasting, confirming that Context-Alignment provide powerful prior knowledge on context.
Multi-spatial Multi-temporal Air Quality Forecasting with Integrated Monitoring and Reanalysis Data
Dec 31, 2023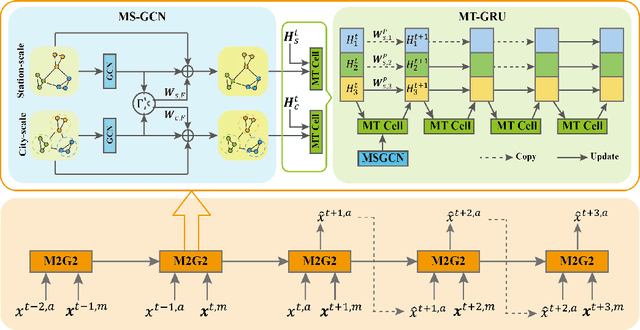
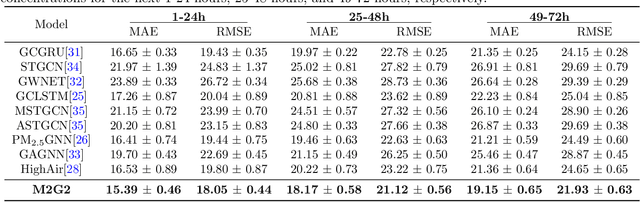
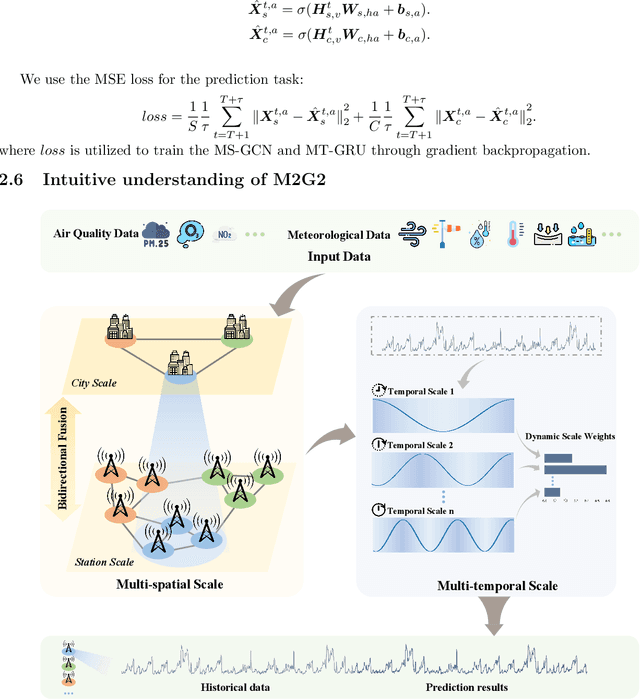
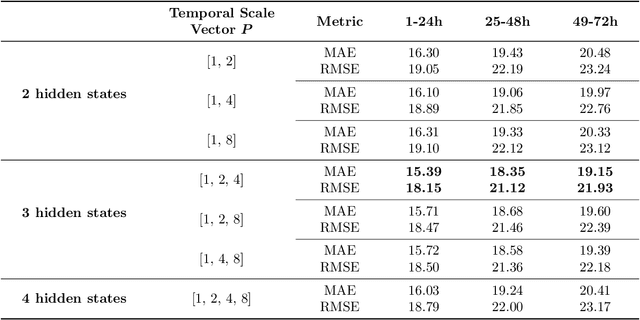
Accurate air quality forecasting is crucial for public health, environmental monitoring and protection, and urban planning. However, existing methods fail to effectively utilize multi-scale information, both spatially and temporally. Spatially, there is a lack of integration between individual monitoring stations and city-wide scales. Temporally, the periodic nature of air quality variations is often overlooked or inadequately considered. To address these limitations, we present a novel Multi-spatial Multi-temporal air quality forecasting method based on Graph Convolutional Networks and Gated Recurrent Units (M2G2), bridging the gap in air quality forecasting across spatial and temporal scales. The proposed framework consists of two modules: Multi-scale Spatial GCN (MS-GCN) for spatial information fusion and Multi-scale Temporal GRU(MT-GRU) for temporal information integration. In the spatial dimension, the MS-GCN module employs a bidirectional learnable structure and a residual structure, enabling comprehensive information exchange between individual monitoring stations and the city-scale graph. Regarding the temporal dimension, the MT-GRU module adaptively combines information from different temporal scales through parallel hidden states. Leveraging meteorological indicators and four air quality indicators, we present comprehensive comparative analyses and ablation experiments, showcasing the higher accuracy of M2G2 in comparison to nine currently available advanced approaches across all aspects. The improvements of M2G2 over the second-best method on RMSE of the 24h/48h/72h are as follows: PM2.5: (7.72%, 6.67%, 10.45%); PM10: (6.43%, 5.68%, 7.73%); NO2: (5.07%, 7.76%, 16.60%); O3: (6.46%, 6.86%, 9.79%). Furthermore, we demonstrate the effectiveness of each module of M2G2 by ablation study.
Focus on Hiders: Exploring Hidden Threats for Enhancing Adversarial Training
Dec 12, 2023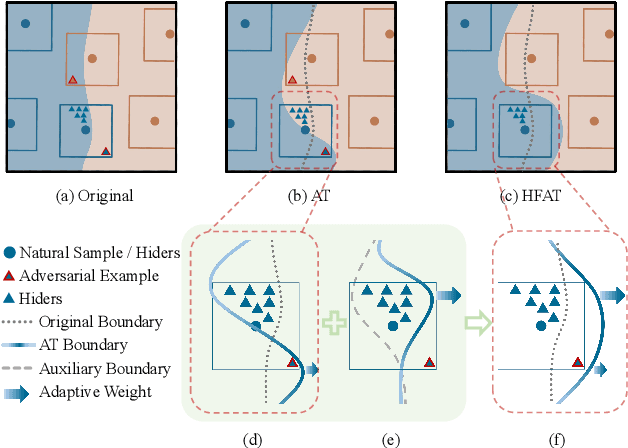
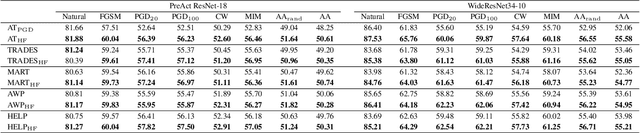
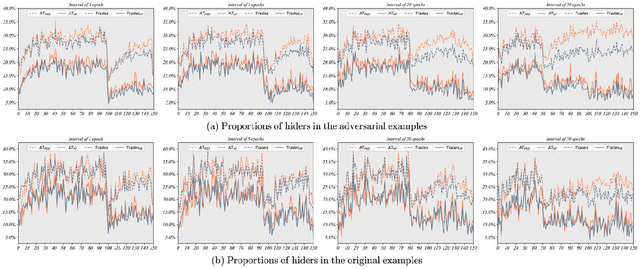
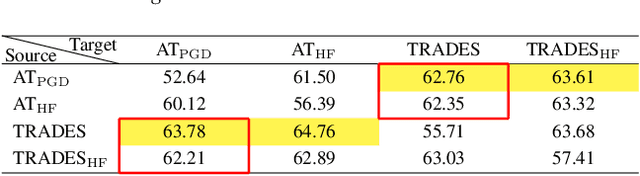
Adversarial training is often formulated as a min-max problem, however, concentrating only on the worst adversarial examples causes alternating repetitive confusion of the model, i.e., previously defended or correctly classified samples are not defensible or accurately classifiable in subsequent adversarial training. We characterize such non-ignorable samples as "hiders", which reveal the hidden high-risk regions within the secure area obtained through adversarial training and prevent the model from finding the real worst cases. We demand the model to prevent hiders when defending against adversarial examples for improving accuracy and robustness simultaneously. By rethinking and redefining the min-max optimization problem for adversarial training, we propose a generalized adversarial training algorithm called Hider-Focused Adversarial Training (HFAT). HFAT introduces the iterative evolution optimization strategy to simplify the optimization problem and employs an auxiliary model to reveal hiders, effectively combining the optimization directions of standard adversarial training and prevention hiders. Furthermore, we introduce an adaptive weighting mechanism that facilitates the model in adaptively adjusting its focus between adversarial examples and hiders during different training periods. We demonstrate the effectiveness of our method based on extensive experiments, and ensure that HFAT can provide higher robustness and accuracy.
CLeaRForecast: Contrastive Learning of High-Purity Representations for Time Series Forecasting
Dec 10, 2023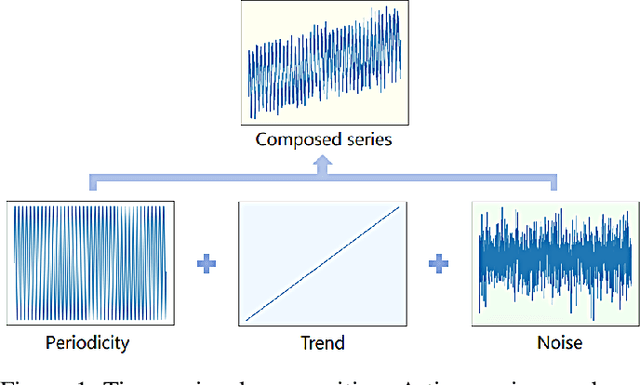
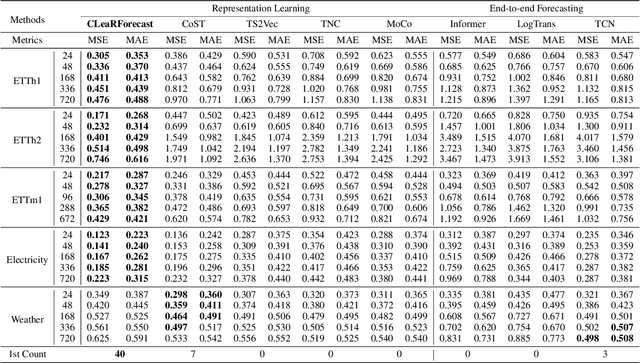
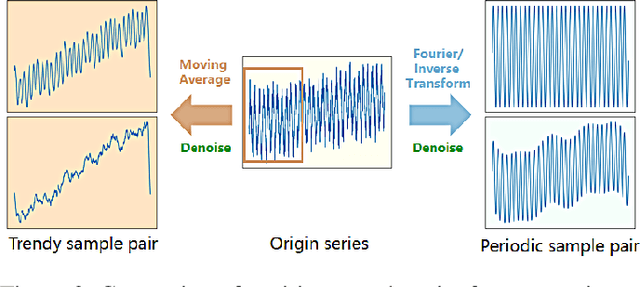
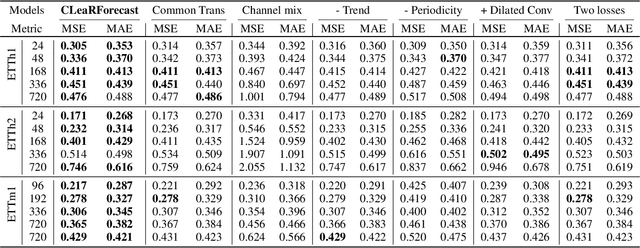
Time series forecasting (TSF) holds significant importance in modern society, spanning numerous domains. Previous representation learning-based TSF algorithms typically embrace a contrastive learning paradigm featuring segregated trend-periodicity representations. Yet, these methodologies disregard the inherent high-impact noise embedded within time series data, resulting in representation inaccuracies and seriously demoting the forecasting performance. To address this issue, we propose CLeaRForecast, a novel contrastive learning framework to learn high-purity time series representations with proposed sample, feature, and architecture purifying methods. More specifically, to avoid more noise adding caused by the transformations of original samples (series), transformations are respectively applied for trendy and periodic parts to provide better positive samples with obviously less noise. Moreover, we introduce a channel independent training manner to mitigate noise originating from unrelated variables in the multivariate series. By employing a streamlined deep-learning backbone and a comprehensive global contrastive loss function, we prevent noise introduction due to redundant or uneven learning of periodicity and trend. Experimental results show the superior performance of CLeaRForecast in various downstream TSF tasks.
Interactive Neural Painting
Jul 31, 2023



In the last few years, Neural Painting (NP) techniques became capable of producing extremely realistic artworks. This paper advances the state of the art in this emerging research domain by proposing the first approach for Interactive NP. Considering a setting where a user looks at a scene and tries to reproduce it on a painting, our objective is to develop a computational framework to assist the users creativity by suggesting the next strokes to paint, that can be possibly used to complete the artwork. To accomplish such a task, we propose I-Paint, a novel method based on a conditional transformer Variational AutoEncoder (VAE) architecture with a two-stage decoder. To evaluate the proposed approach and stimulate research in this area, we also introduce two novel datasets. Our experiments show that our approach provides good stroke suggestions and compares favorably to the state of the art. Additional details, code and examples are available at https://helia95.github.io/inp-website.
More Control for Free! Image Synthesis with Semantic Diffusion Guidance
Dec 14, 2021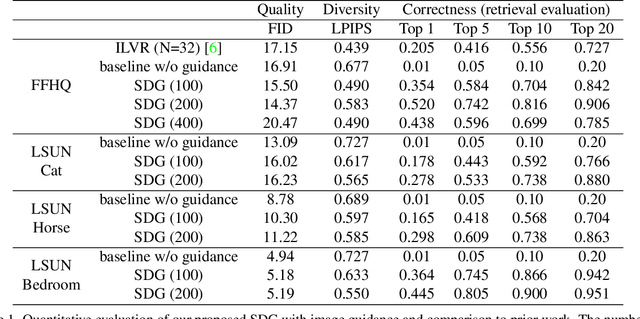
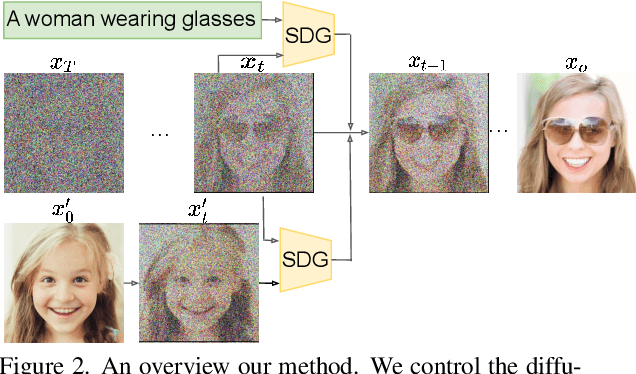
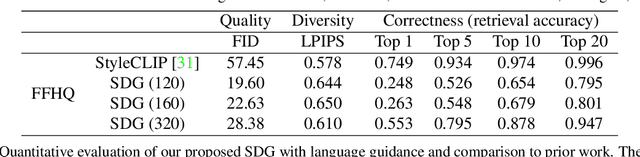

Controllable image synthesis models allow creation of diverse images based on text instructions or guidance from an example image. Recently, denoising diffusion probabilistic models have been shown to generate more realistic imagery than prior methods, and have been successfully demonstrated in unconditional and class-conditional settings. We explore fine-grained, continuous control of this model class, and introduce a novel unified framework for semantic diffusion guidance, which allows either language or image guidance, or both. Guidance is injected into a pretrained unconditional diffusion model using the gradient of image-text or image matching scores. We explore CLIP-based textual guidance as well as both content and style-based image guidance in a unified form. Our text-guided synthesis approach can be applied to datasets without associated text annotations. We conduct experiments on FFHQ and LSUN datasets, and show results on fine-grained text-guided image synthesis, synthesis of images related to a style or content example image, and examples with both textual and image guidance.
Revisit Multinomial Logistic Regression in Deep Learning: Data Dependent Model Initialization for Image Recognition
Sep 17, 2018
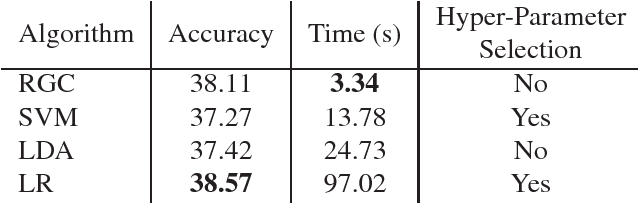
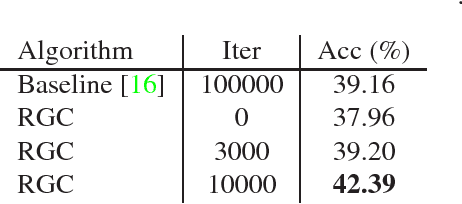
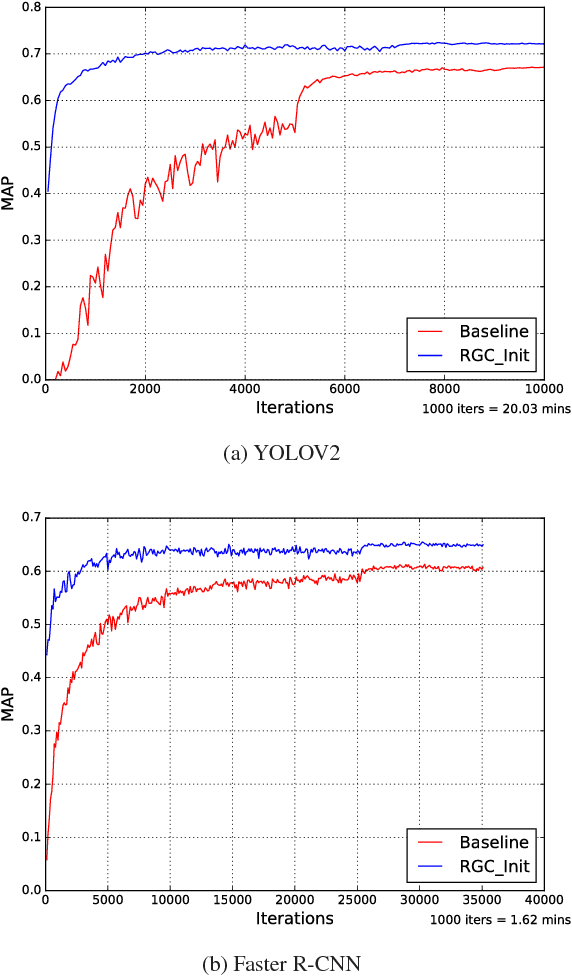
We study in this paper how to initialize the parameters of multinomial logistic regression (a fully connected layer followed with softmax and cross entropy loss), which is widely used in deep neural network (DNN) models for classification problems. As logistic regression is widely known not having a closed-form solution, it is usually randomly initialized, leading to several deficiencies especially in transfer learning where all the layers except for the last task-specific layer are initialized using a pre-trained model. The deficiencies include slow convergence speed, possibility of stuck in local minimum, and the risk of over-fitting. To address those deficiencies, we first study the properties of logistic regression and propose a closed-form approximate solution named regularized Gaussian classifier (RGC). Then we adopt this approximate solution to initialize the task-specific linear layer and demonstrate superior performance over random initialization in terms of both accuracy and convergence speed on various tasks and datasets. For example, for image classification, our approach can reduce the training time by 10 times and achieve 3.2% gain in accuracy for Flickr-style classification. For object detection, our approach can also be 10 times faster in training for the same accuracy, or 5% better in terms of mAP for VOC 2007 with slightly longer training.
MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition
Jul 27, 2016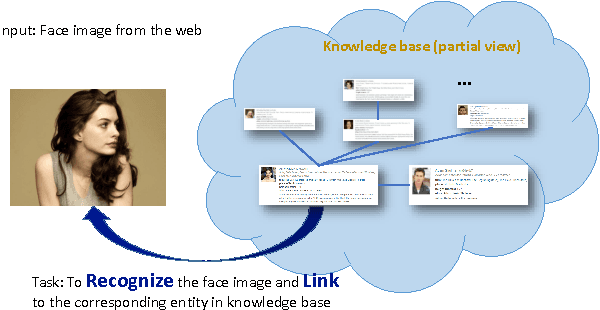
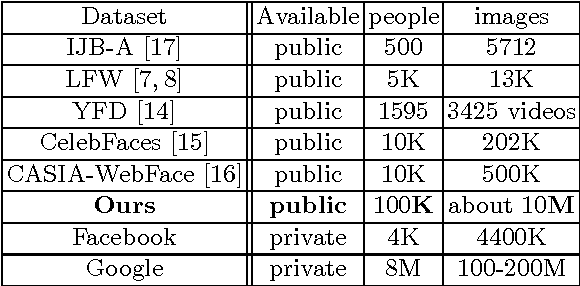
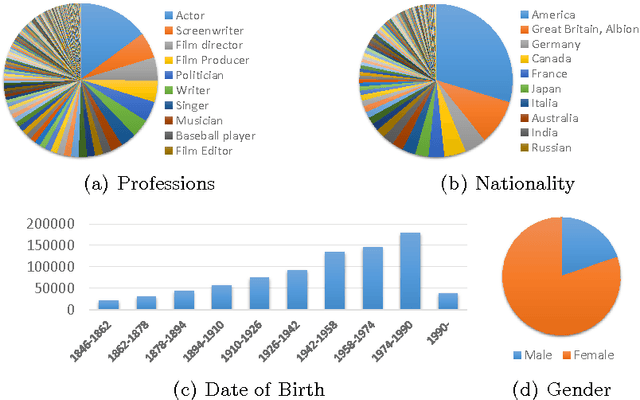
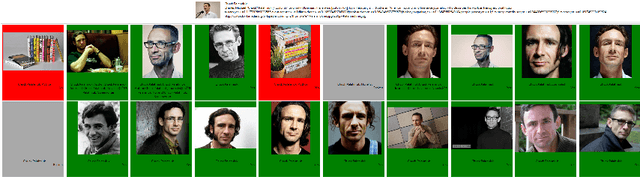
In this paper, we design a benchmark task and provide the associated datasets for recognizing face images and link them to corresponding entity keys in a knowledge base. More specifically, we propose a benchmark task to recognize one million celebrities from their face images, by using all the possibly collected face images of this individual on the web as training data. The rich information provided by the knowledge base helps to conduct disambiguation and improve the recognition accuracy, and contributes to various real-world applications, such as image captioning and news video analysis. Associated with this task, we design and provide concrete measurement set, evaluation protocol, as well as training data. We also present in details our experiment setup and report promising baseline results. Our benchmark task could lead to one of the largest classification problems in computer vision. To the best of our knowledge, our training dataset, which contains 10M images in version 1, is the largest publicly available one in the world.