 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond empirical models: Discovering new constitutive laws in solids with graph-based equation discovery
Nov 13, 2025Constitutive models are fundamental to solid mechanics and materials science, underpinning the quantitative description and prediction of material responses under diverse loading conditions. Traditional phenomenological models, which are derived through empirical fitting, often lack generalizability and rely heavily on expert intuition and predefined functional forms. In this work, we propose a graph-based equation discovery framework for the automated discovery of constitutive laws directly from multisource experimental data. This framework expresses equations as directed graphs, where nodes represent operators and variables, edges denote computational relations, and edge features encode parametric dependencies. This enables the generation and optimization of free-form symbolic expressions with undetermined material-specific parameters. Through the proposed framework, we have discovered new constitutive models for strain-rate effects in alloy steel materials and the deformation behavior of lithium metal. Compared with conventional empirical models, these new models exhibit compact analytical structures and achieve higher accuracy. The proposed graph-based equation discovery framework provides a generalizable and interpretable approach for data-driven scientific modelling, particularly in contexts where traditional empirical formulations are inadequate for representing complex physical phenomena.
BuildSTG: A Multi-building Energy Load Forecasting Method using Spatio-Temporal Graph Neural Network
Jul 28, 2025Due to the extensive availability of operation data, data-driven methods show strong capabilities in predicting building energy loads. Buildings with similar features often share energy patterns, reflected by spatial dependencies in their operational data, which conventional prediction methods struggle to capture. To overcome this, we propose a multi-building prediction approach using spatio-temporal graph neural networks, comprising graph representation, graph learning, and interpretation. First, a graph is built based on building characteristics and environmental factors. Next, a multi-level graph convolutional architecture with attention is developed for energy prediction. Lastly, a method interpreting the optimized graph structure is introduced. Experiments on the Building Data Genome Project 2 dataset confirm superior performance over baselines such as XGBoost, SVR, FCNN, GRU, and Naive, highlighting the method's robustness, generalization, and interpretability in capturing meaningful building similarities and spatial relationships.
Generative Discovery of Partial Differential Equations by Learning from Math Handbooks
May 09, 2025Data driven discovery of partial differential equations (PDEs) is a promising approach for uncovering the underlying laws governing complex systems. However, purely data driven techniques face the dilemma of balancing search space with optimization efficiency. This study introduces a knowledge guided approach that incorporates existing PDEs documented in a mathematical handbook to facilitate the discovery process. These PDEs are encoded as sentence like structures composed of operators and basic terms, and used to train a generative model, called EqGPT, which enables the generation of free form PDEs. A loop of generation evaluation optimization is constructed to autonomously identify the most suitable PDE. Experimental results demonstrate that this framework can recover a variety of PDE forms with high accuracy and computational efficiency, particularly in cases involving complex temporal derivatives or intricate spatial terms, which are often beyond the reach of conventional methods. The approach also exhibits generalizability to irregular spatial domains and higher dimensional settings. Notably, it succeeds in discovering a previously unreported PDE governing strongly nonlinear surface gravity waves propagating toward breaking, based on real world experimental data, highlighting its applicability to practical scenarios and its potential to support scientific discovery.
Context-Alignment: Activating and Enhancing LLM Capabilities in Time Series
Jan 07, 2025



Recently, leveraging pre-trained Large Language Models (LLMs) for time series (TS) tasks has gained increasing attention, which involves activating and enhancing LLMs' capabilities. Many methods aim to activate LLMs' capabilities based on token-level alignment but overlook LLMs' inherent strength on natural language processing -- their deep understanding of linguistic logic and structure rather than superficial embedding processing. We propose Context-Alignment, a new paradigm that aligns TS with a linguistic component in the language environments familiar to LLMs to enable LLMs to contextualize and comprehend TS data, thereby activating their capabilities. Specifically, such context-level alignment comprises structural alignment and logical alignment, which is achieved by a Dual-Scale Context-Alignment GNNs (DSCA-GNNs) applied to TS-language multimodal inputs. Structural alignment utilizes dual-scale nodes to describe hierarchical structure in TS-language, enabling LLMs treat long TS data as a whole linguistic component while preserving intrinsic token features. Logical alignment uses directed edges to guide logical relationships, ensuring coherence in the contextual semantics. Demonstration examples prompt are employed to construct Demonstration Examples based Context-Alignment (DECA) following DSCA-GNNs framework. DECA can be flexibly and repeatedly integrated into various layers of pre-trained LLMs to improve awareness of logic and structure, thereby enhancing performance. Extensive experiments show the effectiveness of DECA and the importance of Context-Alignment across tasks, particularly in few-shot and zero-shot forecasting, confirming that Context-Alignment provide powerful prior knowledge on context.
A Data-Driven Framework for Discovering Fractional Differential Equations in Complex Systems
Dec 05, 2024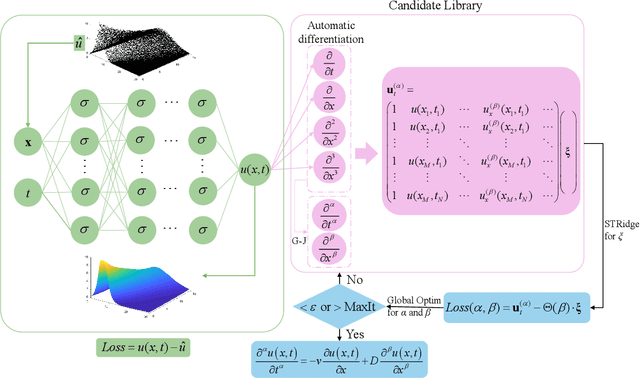



In complex physical systems, conventional differential equations often fall short in capturing non-local and memory effects, as they are limited to local dynamics and integer-order interactions. This study introduces a stepwise data-driven framework for discovering fractional differential equations (FDEs) directly from data. FDEs, known for their capacity to model non-local dynamics with fewer parameters than integer-order derivatives, can represent complex systems with long-range interactions. Our framework applies deep neural networks as surrogate models for denoising and reconstructing sparse and noisy observations while using Gaussian-Jacobi quadrature to handle the challenges posed by singularities in fractional derivatives. To optimize both the sparse coefficients and fractional order, we employ an alternating optimization approach that combines sparse regression with global optimization techniques. We validate the framework across various datasets, including synthetic anomalous diffusion data, experimental data on the creep behavior of frozen soils, and single-particle trajectories modeled by L\'{e}vy motion. Results demonstrate the framework's robustness in identifying the structure of FDEs across diverse noise levels and its capacity to capture integer-order dynamics, offering a flexible approach for modeling memory effects in complex systems.
AutoPV: Automatically Design Your Photovoltaic Power Forecasting Model
Aug 01, 2024Photovoltaic power forecasting (PVPF) is a critical area in time series forecasting (TSF), enabling the efficient utilization of solar energy. With advancements in machine learning and deep learning, various models have been applied to PVPF tasks. However, constructing an optimal predictive architecture for specific PVPF tasks remains challenging, as it requires cross-domain knowledge and significant labor costs. To address this challenge, we introduce AutoPV, a novel framework for the automated search and construction of PVPF models based on neural architecture search (NAS) technology. We develop a brand new NAS search space that incorporates various data processing techniques from state-of-the-art (SOTA) TSF models and typical PVPF deep learning models. The effectiveness of AutoPV is evaluated on diverse PVPF tasks using a dataset from the Daqing Photovoltaic Station in China. Experimental results demonstrate that AutoPV can complete the predictive architecture construction process in a relatively short time, and the newly constructed architecture is superior to SOTA predefined models. This work bridges the gap in applying NAS to TSF problems, assisting non-experts and industries in automatically designing effective PVPF models.
Constructing and Evaluating Digital Twins: An Intelligent Framework for DT Development
Jun 19, 2024The development of Digital Twins (DTs) represents a transformative advance for simulating and optimizing complex systems in a controlled digital space. Despite their potential, the challenge of constructing DTs that accurately replicate and predict the dynamics of real-world systems remains substantial. This paper introduces an intelligent framework for the construction and evaluation of DTs, specifically designed to enhance the accuracy and utility of DTs in testing algorithmic performance. We propose a novel construction methodology that integrates deep learning-based policy gradient techniques to dynamically tune the DT parameters, ensuring high fidelity in the digital replication of physical systems. Moreover, the Mean STate Error (MSTE) is proposed as a robust metric for evaluating the performance of algorithms within these digital space. The efficacy of our framework is demonstrated through extensive simulations that show our DT not only accurately mirrors the physical reality but also provides a reliable platform for algorithm evaluation. This work lays a foundation for future research into DT technologies, highlighting pathways for both theoretical enhancements and practical implementations in various industries.
When Swarm Learning meets energy series data: A decentralized collaborative learning design based on blockchain
Jun 07, 2024
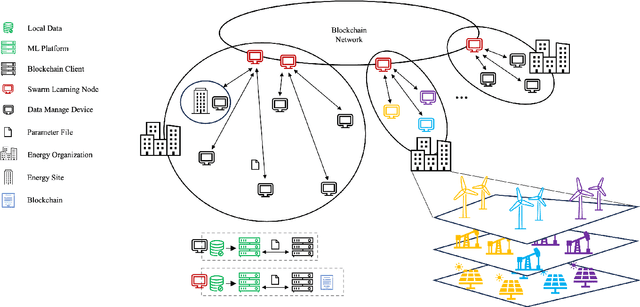


Machine learning models offer the capability to forecast future energy production or consumption and infer essential unknown variables from existing data. However, legal and policy constraints within specific energy sectors render the data sensitive, presenting technical hurdles in utilizing data from diverse sources. Therefore, we propose adopting a Swarm Learning (SL) scheme, which replaces the centralized server with a blockchain-based distributed network to address the security and privacy issues inherent in Federated Learning (FL)'s centralized architecture. Within this distributed Collaborative Learning framework, each participating organization governs nodes for inter-organizational communication. Devices from various organizations utilize smart contracts for parameter uploading and retrieval. Consensus mechanism ensures distributed consistency throughout the learning process, guarantees the transparent trustworthiness and immutability of parameters on-chain. The efficacy of the proposed framework is substantiated across three real-world energy series modeling scenarios with superior performance compared to Local Learning approaches, simultaneously emphasizing enhanced data security and privacy over Centralized Learning and FL method. Notably, as the number of data volume and the count of local epochs increases within a threshold, there is an improvement in model performance accompanied by a reduction in the variance of performance errors. Consequently, this leads to an increased stability and reliability in the outcomes produced by the model.
Optimization of geological carbon storage operations with multimodal latent dynamic model and deep reinforcement learning
Jun 07, 2024



Maximizing storage performance in geological carbon storage (GCS) is crucial for commercial deployment, but traditional optimization demands resource-intensive simulations, posing computational challenges. This study introduces the multimodal latent dynamic (MLD) model, a deep learning framework for fast flow prediction and well control optimization in GCS. The MLD model includes a representation module for compressed latent representations, a transition module for system state evolution, and a prediction module for flow responses. A novel training strategy combining regression loss and joint-embedding consistency loss enhances temporal consistency and multi-step prediction accuracy. Unlike existing models, the MLD supports diverse input modalities, allowing comprehensive data interactions. The MLD model, resembling a Markov decision process (MDP), can train deep reinforcement learning agents, specifically using the soft actor-critic (SAC) algorithm, to maximize net present value (NPV) through continuous interactions. The approach outperforms traditional methods, achieving the highest NPV while reducing computational resources by over 60%. It also demonstrates strong generalization performance, providing improved decisions for new scenarios based on knowledge from previous ones.
Cross-variable Linear Integrated ENhanced Transformer for Photovoltaic power forecasting
Jun 06, 2024Photovoltaic (PV) power forecasting plays a crucial role in optimizing the operation and planning of PV systems, thereby enabling efficient energy management and grid integration. However, un certainties caused by fluctuating weather conditions and complex interactions between different variables pose significant challenges to accurate PV power forecasting. In this study, we propose PV-Client (Cross-variable Linear Integrated ENhanced Transformer for Photovoltaic power forecasting) to address these challenges and enhance PV power forecasting accuracy. PV-Client employs an ENhanced Transformer module to capture complex interactions of various features in PV systems, and utilizes a linear module to learn trend information in PV power. Diverging from conventional time series-based Transformer models that use cross-time Attention to learn dependencies between different time steps, the Enhanced Transformer module integrates cross-variable Attention to capture dependencies between PV power and weather factors. Furthermore, PV-Client streamlines the embedding and position encoding layers by replacing the Decoder module with a projection layer. Experimental results on three real-world PV power datasets affirm PV-Client's state-of-the-art (SOTA) performance in PV power forecasting. Specifically, PV-Client surpasses the second-best model GRU by 5.3% in MSE metrics and 0.9% in accuracy metrics at the Jingang Station. Similarly, PV-Client outperforms the second-best model SVR by 10.1% in MSE metrics and 0.2% in accuracy metrics at the Xinqingnian Station, and PV-Client exhibits superior performance compared to the second-best model SVR with enhancements of 3.4% in MSE metrics and 0.9% in accuracy metrics at the Hongxing Station.