 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Uncertainty Principle: A Unified View of Adversarial Fragility and LLM Hallucination
Mar 20, 2026Adversarial vulnerability in vision and hallucination in large language models are conventionally viewed as separate problems, each addressed with modality-specific patches. This study first reveals that they share a common geometric origin: the input and its loss gradient are conjugate observables subject to an irreducible uncertainty bound. Formalizing a Neural Uncertainty Principle (NUP) under a loss-induced state, we find that in near-bound regimes, further compression must be accompanied by increased sensitivity dispersion (adversarial fragility), while weak prompt-gradient coupling leaves generation under-constrained (hallucination). Crucially, this bound is modulated by an input-gradient correlation channel, captured by a specifically designed single-backward probe. In vision, masking highly coupled components improves robustness without costly adversarial training; in language, the same prefill-stage probe detects hallucination risk before generating any answer tokens. NUP thus turns two seemingly separate failure taxonomies into a shared uncertainty-budget view and provides a principled lens for reliability analysis. Guided by this NUP theory, we propose ConjMask (masking high-contribution input components) and LogitReg (logit-side regularization) to improve robustness without adversarial training, and use the probe as a decoding-free risk signal for LLMs, enabling hallucination detection and prompt selection. NUP thus provides a unified, practical framework for diagnosing and mitigating boundary anomalies across perception and generation tasks.
Is AI Robust Enough for Scientific Research?
Dec 19, 2024



We uncover a phenomenon largely overlooked by the scientific community utilizing AI: neural networks exhibit high susceptibility to minute perturbations, resulting in significant deviations in their outputs. Through an analysis of five diverse application areas -- weather forecasting, chemical energy and force calculations, fluid dynamics, quantum chromodynamics, and wireless communication -- we demonstrate that this vulnerability is a broad and general characteristic of AI systems. This revelation exposes a hidden risk in relying on neural networks for essential scientific computations, calling further studies on their reliability and security.
Symmetry Breaking in Neural Network Optimization: Insights from Input Dimension Expansion
Sep 10, 2024



Understanding the mechanisms behind neural network optimization is crucial for improving network design and performance. While various optimization techniques have been developed, a comprehensive understanding of the underlying principles that govern these techniques remains elusive. Specifically, the role of symmetry breaking, a fundamental concept in physics, has not been fully explored in neural network optimization. This gap in knowledge limits our ability to design networks that are both efficient and effective. Here, we propose the symmetry breaking hypothesis to elucidate the significance of symmetry breaking in enhancing neural network optimization. We demonstrate that a simple input expansion can significantly improve network performance across various tasks, and we show that this improvement can be attributed to the underlying symmetry breaking mechanism. We further develop a metric to quantify the degree of symmetry breaking in neural networks, providing a practical approach to evaluate and guide network design. Our findings confirm that symmetry breaking is a fundamental principle that underpins various optimization techniques, including dropout, batch normalization, and equivariance. By quantifying the degree of symmetry breaking, our work offers a practical technique for performance enhancement and a metric to guide network design without the need for complete datasets and extensive training processes.
Constructing and Evaluating Digital Twins: An Intelligent Framework for DT Development
Jun 19, 2024The development of Digital Twins (DTs) represents a transformative advance for simulating and optimizing complex systems in a controlled digital space. Despite their potential, the challenge of constructing DTs that accurately replicate and predict the dynamics of real-world systems remains substantial. This paper introduces an intelligent framework for the construction and evaluation of DTs, specifically designed to enhance the accuracy and utility of DTs in testing algorithmic performance. We propose a novel construction methodology that integrates deep learning-based policy gradient techniques to dynamically tune the DT parameters, ensuring high fidelity in the digital replication of physical systems. Moreover, the Mean STate Error (MSTE) is proposed as a robust metric for evaluating the performance of algorithms within these digital space. The efficacy of our framework is demonstrated through extensive simulations that show our DT not only accurately mirrors the physical reality but also provides a reliable platform for algorithm evaluation. This work lays a foundation for future research into DT technologies, highlighting pathways for both theoretical enhancements and practical implementations in various industries.
Quantum-Inspired Analysis of Neural Network Vulnerabilities: The Role of Conjugate Variables in System Attacks
Feb 16, 2024


Neural networks demonstrate inherent vulnerability to small, non-random perturbations, emerging as adversarial attacks. Such attacks, born from the gradient of the loss function relative to the input, are discerned as input conjugates, revealing a systemic fragility within the network structure. Intriguingly, a mathematical congruence manifests between this mechanism and the quantum physics' uncertainty principle, casting light on a hitherto unanticipated interdisciplinarity. This inherent susceptibility within neural network systems is generally intrinsic, highlighting not only the innate vulnerability of these networks but also suggesting potential advancements in the interdisciplinary area for understanding these black-box networks.
On the uncertainty principle of neural networks
May 03, 2022
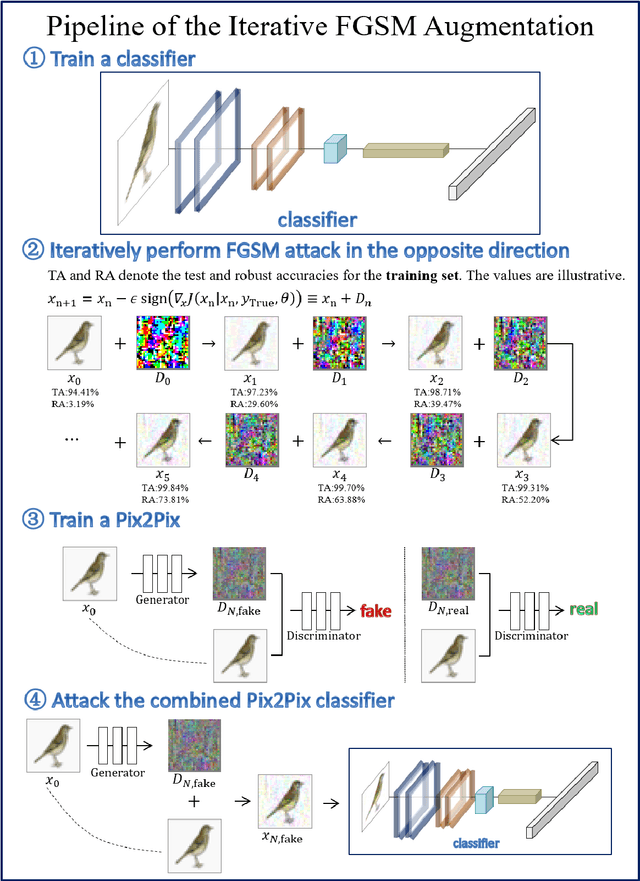
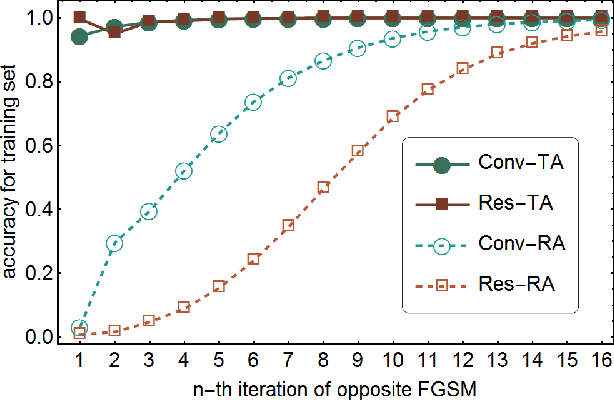
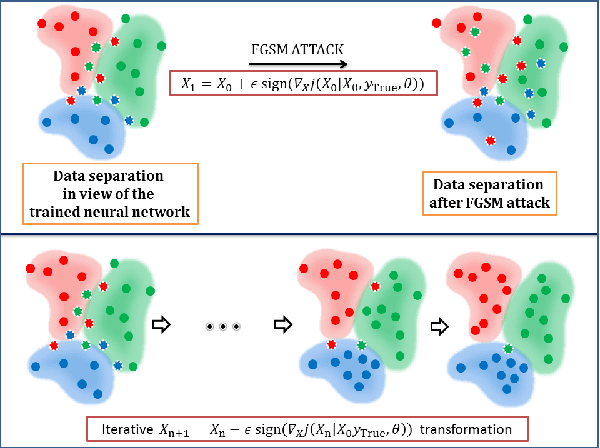
Despite the successes in many fields, it is found that neural networks are vulnerability and difficult to be both accurate and robust (robust means that the prediction of the trained network stays unchanged for inputs with non-random perturbations introduced by adversarial attacks). Various empirical and analytic studies have suggested that there is more or less a trade-off between the accuracy and robustness of neural networks. If the trade-off is inherent, applications based on the neural networks are vulnerable with untrustworthy predictions. It is then essential to ask whether the trade-off is an inherent property or not. Here, we show that the accuracy-robustness trade-off is an intrinsic property whose underlying mechanism is deeply related to the uncertainty principle in quantum mechanics. We find that for a neural network to be both accurate and robust, it needs to resolve the features of the two conjugated parts $x$ (the inputs) and $\Delta$ (the derivatives of the normalized loss function $J$ with respect to $x$), respectively. Analogous to the position-momentum conjugation in quantum mechanics, we show that the inputs and their conjugates cannot be resolved by a neural network simultaneously.