 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeamAgent: LLM-Aided MIMO Beamforming with Decoupled Intent Parsing and Alternating Optimization for Joint Site Selection and Precoding
Mar 19, 2026Integrating large language models (LLMs) into wireless communication optimization is a promising yet challenging direction. Existing approaches either use LLMs as black-box solvers or code generators, tightly coupling them with numerical computation. However, LLMs lack the precision required for physical-layer optimization, and the scarcity of wireless training data makes domain-specific fine-tuning impractical. We propose BeamAgent, an LLM-aided MIMO beamforming framework that explicitly decouples semantic intent parsing from numerical optimization. The LLM serves solely as a semantic translator that converts natural language descriptions into structured spatial constraints. A dedicated gradient-based optimizer then jointly solves the discrete base station site selection and continuous precoding design through an alternating optimization algorithm. A scene-aware prompt enables grounded spatial reasoning without fine-tuning, and a multi-round interaction mechanism with dual-layer intent classification ensures robust constraint verification. A penalty-based loss function enforces dark-zone power constraints while releasing optimization degrees of freedom for bright-zone gain maximization. Experiments on a ray-tracing-based urban MIMO scenario show that BeamAgent achieves a bright-zone power of 84.0\,dB, outperforming exhaustive zero-forcing by 7.1 dB under the same dark-zone constraint. The end-to-end system reaches within 3.3 dB of the expert upper bound, with the full optimization completing in under 2 s on a laptop.
Learn for Variation: Variationally Guided AAV Trajectory Learning in Differentiable Environments
Mar 19, 2026Autonomous aerial vehicles (AAVs) empower sixth-generation (6G) Internet-of-Things (IoT) networks through mobility-driven data collection. However, conventional reward-driven reinforcement learning for AAV trajectory planning suffers from severe credit assignment issues and training instability, because sparse scalar rewards fail to capture the long-term and nonlinear effects of sequential movements. To address these challenges, this paper proposes Learn for Variation (L4V), a gradient-informed trajectory learning framework that replaces high-variance scalar reward signals with dense and analytically grounded policy gradients. Particularly, the coupled evolution of AAV kinematics, distance-dependent channel gains, and per-user data-collection progress is first unrolled into an end-to-end differentiable computational graph. Backpropagation through time then serves as a discrete adjoint solver, which propagates exact sensitivities from the cumulative mission objective to every control action and policy parameter. These structured gradients are used to train a deterministic neural policy with temporal smoothness regularization and gradient clipping. Extensive simulations demonstrate that L4V consistently outperforms representative baselines, including a genetic algorithm, DQN, A2C, and DDPG, in mission completion time, average transmission rate, and training cost
RadioDiff-FS: Physics-Informed Manifold Alignment in Few-Shot Diffusion Models for High-Fidelity Radio Map Construction
Mar 19, 2026Radio maps (RMs) provide spatially continuous propagation characterizations essential for 6G network planning, but high-fidelity RM construction remains challenging. Rigorous electromagnetic solvers incur prohibitive computational latency, while data-driven models demand massive labeled datasets and generalize poorly from simplified simulations to complex multipath environments. This paper proposes RadioDiff-FS, a few-shot diffusion framework that adapts a pre-trained main-path generator to multipath-rich target domains with only a small number of high-fidelity samples. The adaptation is grounded in a theoretical decomposition of the multipath RM into a dominant main-path component and a directionally sparse residual. This decomposition shows that the cross-domain shift corresponds to a bounded and geometrically structured feature translation rather than an arbitrary distribution change. A Direction-Consistency Loss (DCL) is then introduced to constrain diffusion score updates along physically plausible propagation directions, suppressing phase-inconsistent artifacts that arise in the low-data regime. Experiments show that RadioDiff-FS reduces NMSE by 59.5% on static RMs and by 74.0% on dynamic RMs relative to the vanilla diffusion baseline, achieving an SSIM of 0.9752 and a PSNR of 36.37 dB under severely limited supervision.
A Tutorial on Learning-Based Radio Map Construction: Data, Paradigms, and Physics-Awarenes
Mar 18, 2026The integration of artificial intelligence into next-generation wireless networks necessitates the accurate construction of radio maps (RMs) as a foundational prerequisite for electromagnetic digital twins. A RM provides the digital representation of the wireless propagation environment, mapping complex geographical and topological boundary conditions to critical spatial-spectral metrics that range from received signal strength to full channel state information matrices. This tutorial presents a comprehensive survey of learning-based RM construction, systematically addressing three intertwined dimensions: data, paradigms, and physics-awareness. From the data perspective, we review physical measurement campaigns, ray tracing simulation engines, and publicly available benchmark datasets, identifying their respective strengths and fundamental limitations. From the paradigm perspective, we establish a core taxonomy that categorizes RM construction into source-aware forward prediction and source-agnostic inverse reconstruction, and examine five principal neural architecture families spanning convolutional neural networks, vision transformers, graph neural networks, generative adversarial networks, and diffusion models. We further survey optics-inspired methods adapted from neural radiance fields and 3D Gaussian splatting for continuous wireless radiation field modeling. From the physics-awareness perspective, we introduce a three-level integration framework encompassing data-level feature engineering, loss-level partial differential equation regularization, and architecture-level structural isomorphism. Open challenges including foundation model development, physical hallucination detection, and amortized inference for real-time deployment are discussed to outline future research directions.
Neural Electromagnetic Fields for High-Resolution Material Parameter Reconstruction
Mar 03, 2026Creating functional Digital Twins, simulatable 3D replicas of the real world, is a central challenge in computer vision. Current methods like NeRF produce visually rich but functionally incomplete twins. The key barrier is the lack of underlying material properties (e.g., permittivity, conductivity). Acquiring this information for every point in a scene via non-contact, non-invasive sensing is a primary goal, but it demands solving a notoriously ill-posed physical inversion problem. Standard remote signals, like images and radio frequencies (RF), deeply entangle the unknown geometry, ambient field, and target materials. We introduce NEMF, a novel framework for dense, non-invasive physical inversion designed to build functional digital twins. Our key insight is a systematic disentanglement strategy. NEMF leverages high-fidelity geometry from images as a powerful anchor, which first enables the resolution of the ambient field. By constraining both geometry and field using only non-invasive data, the original ill-posed problem transforms into a well-posed, physics-supervised learning task. This transformation unlocks our core inversion module: a decoder. Guided by ambient RF signals and a differentiable layer incorporating physical reflection models, it learns to explicitly output a continuous, spatially-varying field of the scene's underlying material parameters. We validate our framework on high-fidelity synthetic datasets. Experiments show our non-invasive inversion reconstructs these material maps with high accuracy, and the resulting functional twin enables high-fidelity physical simulation. This advance moves beyond passive visual replicas, enabling the creation of truly functional and simulatable models of the physical world.
RadioDiff-Flux: Efficient Radio Map Construction via Generative Denoise Diffusion Model Trajectory Midpoint Reuse
Jan 06, 2026Accurate radio map (RM) construction is essential to enabling environment-aware and adaptive wireless communication. However, in future 6G scenarios characterized by high-speed network entities and fast-changing environments, it is very challenging to meet real-time requirements. Although generative diffusion models (DMs) can achieve state-of-the-art accuracy with second-level delay, their iterative nature leads to prohibitive inference latency in delay-sensitive scenarios. In this paper, by uncovering a key structural property of diffusion processes: the latent midpoints remain highly consistent across semantically similar scenes, we propose RadioDiff-Flux, a novel two-stage latent diffusion framework that decouples static environmental modeling from dynamic refinement, enabling the reuse of precomputed midpoints to bypass redundant denoising. In particular, the first stage generates a coarse latent representation using only static scene features, which can be cached and shared across similar scenarios. The second stage adapts this representation to dynamic conditions and transmitter locations using a pre-trained model, thereby avoiding repeated early-stage computation. The proposed RadioDiff-Flux significantly reduces inference time while preserving fidelity. Experiment results show that RadioDiff-Flux can achieve up to 50 acceleration with less than 0.15% accuracy loss, demonstrating its practical utility for fast, scalable RM generation in future 6G networks.
Cross-Receiver Generalization for RF Fingerprint Identification via Feature Disentanglement and Adversarial Training
Oct 10, 2025
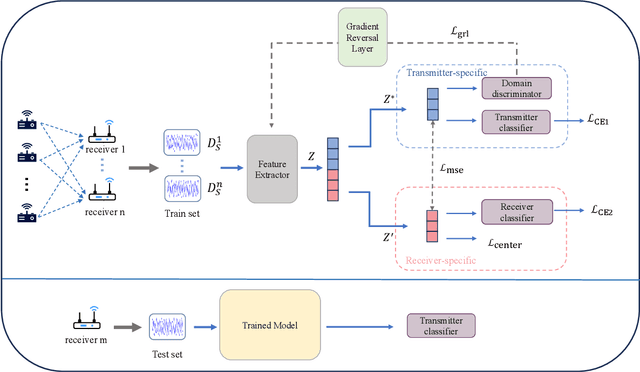
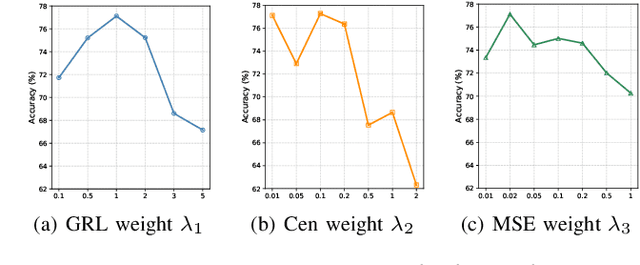
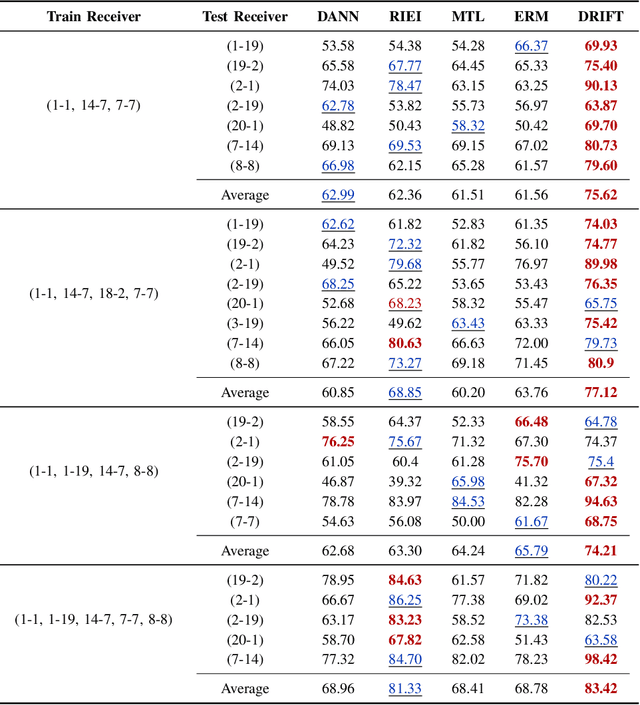
Radio frequency fingerprint identification (RFFI) is a critical technique for wireless network security, leveraging intrinsic hardware-level imperfections introduced during device manufacturing to enable precise transmitter identification. While deep neural networks have shown remarkable capability in extracting discriminative features, their real-world deployment is hindered by receiver-induced variability. In practice, RF fingerprint signals comprise transmitter-specific features as well as channel distortions and receiver-induced biases. Although channel equalization can mitigate channel noise, receiver-induced feature shifts remain largely unaddressed, causing the RFFI models to overfit to receiver-specific patterns. This limitation is particularly problematic when training and evaluation share the same receiver, as replacing the receiver in deployment can cause substantial performance degradation. To tackle this challenge, we propose an RFFI framework robust to cross-receiver variability, integrating adversarial training and style transfer to explicitly disentangle transmitter and receiver features. By enforcing domain-invariant representation learning, our method isolates genuine hardware signatures from receiver artifacts, ensuring robustness against receiver changes. Extensive experiments on multi-receiver datasets demonstrate that our approach consistently outperforms state-of-the-art baselines, achieving up to a 10% improvement in average accuracy across diverse receiver settings.
QoE-Aware Service Provision for Mobile AR Rendering: An Agent-Driven Approach
Aug 12, 2025Mobile augmented reality (MAR) is envisioned as a key immersive application in 6G, enabling virtual content rendering aligned with the physical environment through device pose estimation. In this paper, we propose a novel agent-driven communication service provisioning approach for edge-assisted MAR, aiming to reduce communication overhead between MAR devices and the edge server while ensuring the quality of experience (QoE). First, to address the inaccessibility of MAR application-specific information to the network controller, we establish a digital agent powered by large language models (LLMs) on behalf of the MAR service provider, bridging the data and function gap between the MAR service and network domains. Second, to cope with the user-dependent and dynamic nature of data traffic patterns for individual devices, we develop a user-level QoE modeling method that captures the relationship between communication resource demands and perceived user QoE, enabling personalized, agent-driven communication resource management. Trace-driven simulation results demonstrate that the proposed approach outperforms conventional LLM-based QoE-aware service provisioning methods in both user-level QoE modeling accuracy and communication resource efficiency.
RadioDiff-3D: A 3D$\times$3D Radio Map Dataset and Generative Diffusion Based Benchmark for 6G Environment-Aware Communication
Jul 16, 2025Radio maps (RMs) serve as a critical foundation for enabling environment-aware wireless communication, as they provide the spatial distribution of wireless channel characteristics. Despite recent progress in RM construction using data-driven approaches, most existing methods focus solely on pathloss prediction in a fixed 2D plane, neglecting key parameters such as direction of arrival (DoA), time of arrival (ToA), and vertical spatial variations. Such a limitation is primarily due to the reliance on static learning paradigms, which hinder generalization beyond the training data distribution. To address these challenges, we propose UrbanRadio3D, a large-scale, high-resolution 3D RM dataset constructed via ray tracing in realistic urban environments. UrbanRadio3D is over 37$\times$3 larger than previous datasets across a 3D space with 3 metrics as pathloss, DoA, and ToA, forming a novel 3D$\times$33D dataset with 7$\times$3 more height layers than prior state-of-the-art (SOTA) dataset. To benchmark 3D RM construction, a UNet with 3D convolutional operators is proposed. Moreover, we further introduce RadioDiff-3D, a diffusion-model-based generative framework utilizing the 3D convolutional architecture. RadioDiff-3D supports both radiation-aware scenarios with known transmitter locations and radiation-unaware settings based on sparse spatial observations. Extensive evaluations on UrbanRadio3D validate that RadioDiff-3D achieves superior performance in constructing rich, high-dimensional radio maps under diverse environmental dynamics. This work provides a foundational dataset and benchmark for future research in 3D environment-aware communication. The dataset is available at https://github.com/UNIC-Lab/UrbanRadio3D.
Latent Diffusion Model Based Denoising Receiver for 6G Semantic Communication: From Stochastic Differential Theory to Application
Jun 06, 2025In this paper, a novel semantic communication framework empowered by generative artificial intelligence (GAI) is proposed, specifically leveraging the capabilities of diffusion models (DMs). A rigorous theoretical foundation is established based on stochastic differential equations (SDEs), which elucidates the denoising properties of DMs in mitigating additive white Gaussian noise (AWGN) in latent semantic representations. Crucially, a closed-form analytical relationship between the signal-to-noise ratio (SNR) and the denoising timestep is derived, enabling the optimal selection of diffusion parameters for any given channel condition. To address the distribution mismatch between the received signal and the DM's training data, a mathematically principled scaling mechanism is introduced, ensuring robust performance across a wide range of SNRs without requiring model fine-tuning. Built upon this theoretical insight, we develop a latent diffusion model (LDM)-based semantic transceiver, wherein a variational autoencoder (VAE) is employed for efficient semantic compression, and a pretrained DM serves as a universal denoiser. Notably, the proposed architecture is fully training-free at inference time, offering high modularity and compatibility with large-scale pretrained LDMs. This design inherently supports zero-shot generalization and mitigates the challenges posed by out-of-distribution inputs. Extensive experimental evaluations demonstrate that the proposed framework significantly outperforms conventional neural-network-based semantic communication baselines, particularly under low SNR conditions and distributional shifts, thereby establishing a promising direction for GAI-driven robust semantic transmission in future 6G systems.