 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on Learning-Based Radio Map Construction: Data, Paradigms, and Physics-Awarenes
Mar 18, 2026The integration of artificial intelligence into next-generation wireless networks necessitates the accurate construction of radio maps (RMs) as a foundational prerequisite for electromagnetic digital twins. A RM provides the digital representation of the wireless propagation environment, mapping complex geographical and topological boundary conditions to critical spatial-spectral metrics that range from received signal strength to full channel state information matrices. This tutorial presents a comprehensive survey of learning-based RM construction, systematically addressing three intertwined dimensions: data, paradigms, and physics-awareness. From the data perspective, we review physical measurement campaigns, ray tracing simulation engines, and publicly available benchmark datasets, identifying their respective strengths and fundamental limitations. From the paradigm perspective, we establish a core taxonomy that categorizes RM construction into source-aware forward prediction and source-agnostic inverse reconstruction, and examine five principal neural architecture families spanning convolutional neural networks, vision transformers, graph neural networks, generative adversarial networks, and diffusion models. We further survey optics-inspired methods adapted from neural radiance fields and 3D Gaussian splatting for continuous wireless radiation field modeling. From the physics-awareness perspective, we introduce a three-level integration framework encompassing data-level feature engineering, loss-level partial differential equation regularization, and architecture-level structural isomorphism. Open challenges including foundation model development, physical hallucination detection, and amortized inference for real-time deployment are discussed to outline future research directions.
Cross-Receiver Generalization for RF Fingerprint Identification via Feature Disentanglement and Adversarial Training
Oct 10, 2025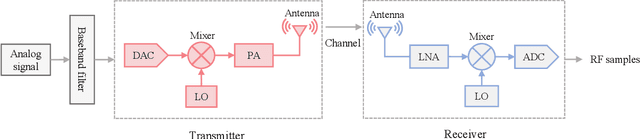
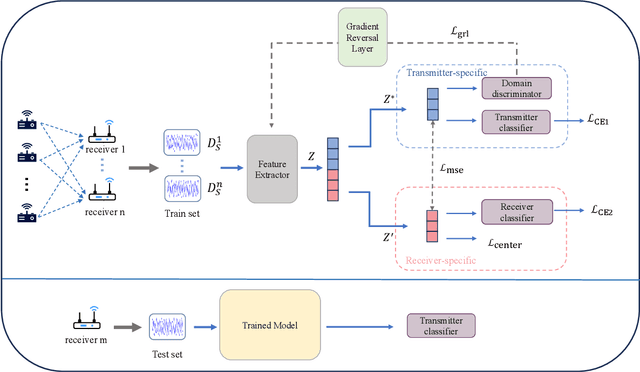
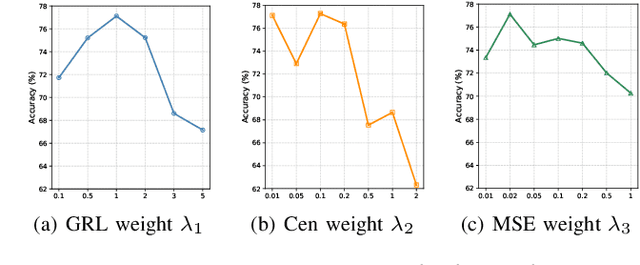
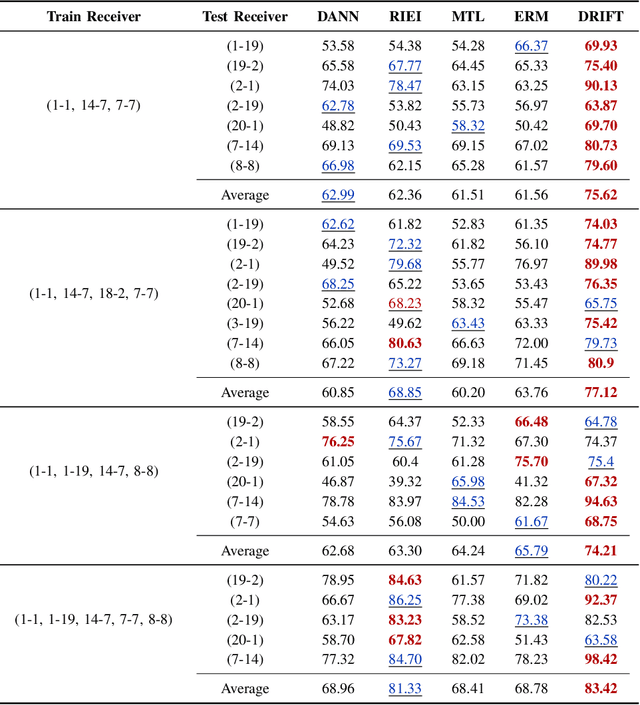
Radio frequency fingerprint identification (RFFI) is a critical technique for wireless network security, leveraging intrinsic hardware-level imperfections introduced during device manufacturing to enable precise transmitter identification. While deep neural networks have shown remarkable capability in extracting discriminative features, their real-world deployment is hindered by receiver-induced variability. In practice, RF fingerprint signals comprise transmitter-specific features as well as channel distortions and receiver-induced biases. Although channel equalization can mitigate channel noise, receiver-induced feature shifts remain largely unaddressed, causing the RFFI models to overfit to receiver-specific patterns. This limitation is particularly problematic when training and evaluation share the same receiver, as replacing the receiver in deployment can cause substantial performance degradation. To tackle this challenge, we propose an RFFI framework robust to cross-receiver variability, integrating adversarial training and style transfer to explicitly disentangle transmitter and receiver features. By enforcing domain-invariant representation learning, our method isolates genuine hardware signatures from receiver artifacts, ensuring robustness against receiver changes. Extensive experiments on multi-receiver datasets demonstrate that our approach consistently outperforms state-of-the-art baselines, achieving up to a 10% improvement in average accuracy across diverse receiver settings.
Trapezoidal Gradient Descent for Effective Reinforcement Learning in Spiking Networks
Jun 19, 2024With the rapid development of artificial intelligence technology, the field of reinforcement learning has continuously achieved breakthroughs in both theory and practice. However, traditional reinforcement learning algorithms often entail high energy consumption during interactions with the environment. Spiking Neural Network (SNN), with their low energy consumption characteristics and performance comparable to deep neural networks, have garnered widespread attention. To reduce the energy consumption of practical applications of reinforcement learning, researchers have successively proposed the Pop-SAN and MDC-SAN algorithms. Nonetheless, these algorithms use rectangular functions to approximate the spike network during the training process, resulting in low sensitivity, thus indicating room for improvement in the training effectiveness of SNN. Based on this, we propose a trapezoidal approximation gradient method to replace the spike network, which not only preserves the original stable learning state but also enhances the model's adaptability and response sensitivity under various signal dynamics. Simulation results show that the improved algorithm, using the trapezoidal approximation gradient to replace the spike network, achieves better convergence speed and performance compared to the original algorithm and demonstrates good training stability.