 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniAgent: Audio-Guided Active Perception Agent for Omnimodal Audio-Video Understanding
Dec 29, 2025Omnimodal large language models have made significant strides in unifying audio and visual modalities; however, they often lack the fine-grained cross-modal understanding and have difficulty with multimodal alignment. To address these limitations, we introduce OmniAgent, a fully audio-guided active perception agent that dynamically orchestrates specialized tools to achieve more fine-grained audio-visual reasoning. Unlike previous works that rely on rigid, static workflows and dense frame-captioning, this paper demonstrates a paradigm shift from passive response generation to active multimodal inquiry. OmniAgent employs dynamic planning to autonomously orchestrate tool invocation on demand, strategically concentrating perceptual attention on task-relevant cues. Central to our approach is a novel coarse-to-fine audio-guided perception paradigm, which leverages audio cues to localize temporal events and guide subsequent reasoning. Extensive empirical evaluations on three audio-video understanding benchmarks demonstrate that OmniAgent achieves state-of-the-art performance, surpassing leading open-source and proprietary models by substantial margins of 10% - 20% accuracy.
StreamingAssistant: Efficient Visual Token Pruning for Accelerating Online Video Understanding
Dec 14, 2025Online video understanding is essential for applications like public surveillance and AI glasses. However, applying Multimodal Large Language Models (MLLMs) to this domain is challenging due to the large number of video frames, resulting in high GPU memory usage and computational latency. To address these challenges, we propose token pruning as a means to reduce context length while retaining critical information. Specifically, we introduce a novel redundancy metric, Maximum Similarity to Spatially Adjacent Video Tokens (MSSAVT), which accounts for both token similarity and spatial position. To mitigate the bidirectional dependency between pruning and redundancy, we further design a masked pruning strategy that ensures only mutually unadjacent tokens are pruned. We also integrate an existing temporal redundancy-based pruning method to eliminate temporal redundancy of the video modality. Experimental results on multiple online and offline video understanding benchmarks demonstrate that our method significantly improves the accuracy (i.e., by 4\% at most) while incurring a negligible pruning latency (i.e., less than 1ms). Our full implementation will be made publicly available.
OmniZip: Audio-Guided Dynamic Token Compression for Fast Omnimodal Large Language Models
Nov 18, 2025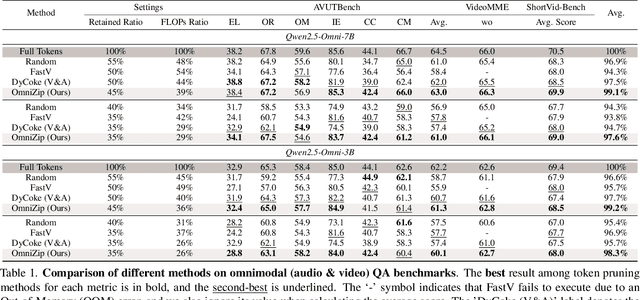
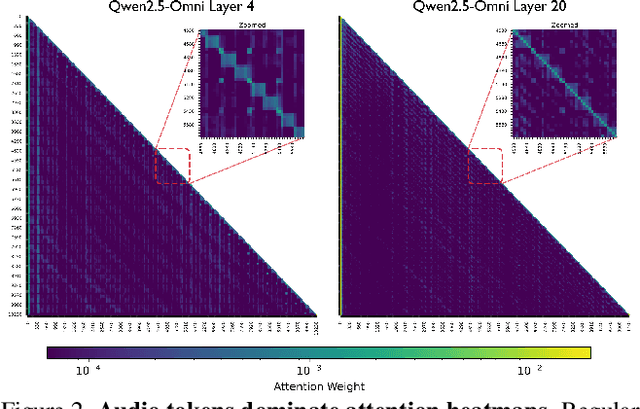
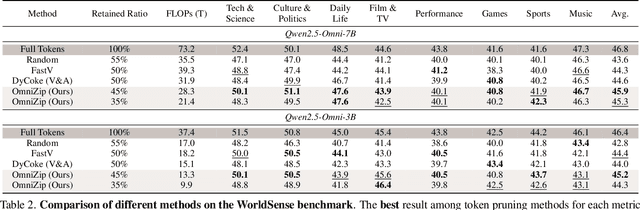
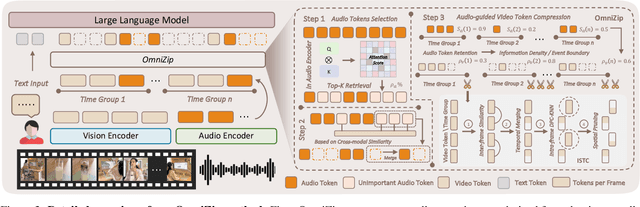
Omnimodal large language models (OmniLLMs) have attracted increasing research attention of late towards unified audio-video understanding, wherein processing audio-video token sequences creates a significant computational bottleneck, however. Existing token compression methods have yet to accommodate this emerging need of jointly compressing multimodal tokens. To bridge this gap, we present OmniZip, a training-free, audio-guided audio-visual token-compression framework that optimizes multimodal token representation and accelerates inference. Specifically, OmniZip first identifies salient audio tokens, then computes an audio retention score for each time group to capture information density, thereby dynamically guiding video token pruning and preserving cues from audio anchors enhanced by cross-modal similarity. For each time window, OmniZip compresses the video tokens using an interleaved spatio-temporal scheme. Extensive empirical results demonstrate the merits of OmniZip - it achieves 3.42X inference speedup and 1.4X memory reduction over other top-performing counterparts, while maintaining performance with no training.
When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios
Jul 27, 2025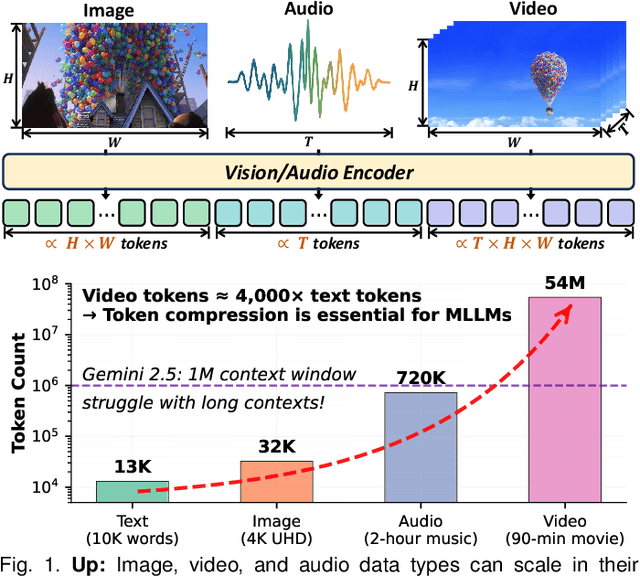
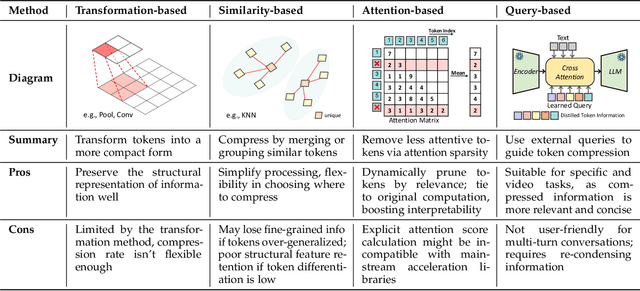
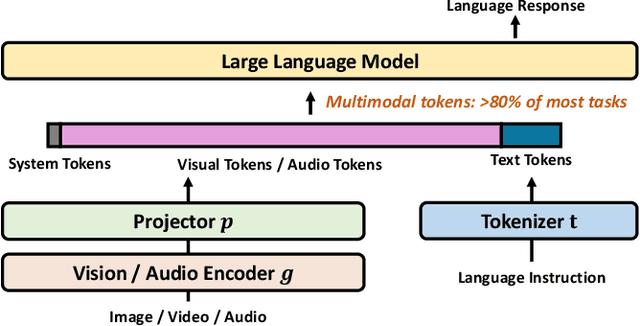
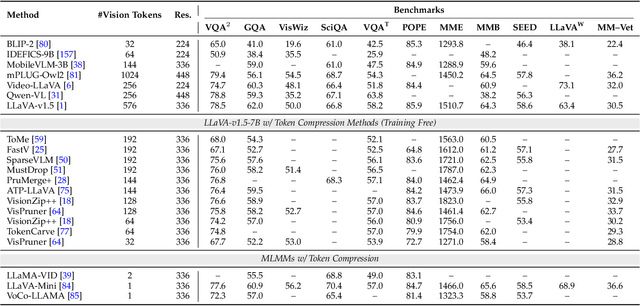
Multimodal large language models (MLLMs) have made remarkable strides, largely driven by their ability to process increasingly long and complex contexts, such as high-resolution images, extended video sequences, and lengthy audio input. While this ability significantly enhances MLLM capabilities, it introduces substantial computational challenges, primarily due to the quadratic complexity of self-attention mechanisms with numerous input tokens. To mitigate these bottlenecks, token compression has emerged as an auspicious and critical approach, efficiently reducing the number of tokens during both training and inference. In this paper, we present the first systematic survey and synthesis of the burgeoning field of multimodal long context token compression. Recognizing that effective compression strategies are deeply tied to the unique characteristics and redundancies of each modality, we categorize existing approaches by their primary data focus, enabling researchers to quickly access and learn methods tailored to their specific area of interest: (1) image-centric compression, which addresses spatial redundancy in visual data; (2) video-centric compression, which tackles spatio-temporal redundancy in dynamic sequences; and (3) audio-centric compression, which handles temporal and spectral redundancy in acoustic signals. Beyond this modality-driven categorization, we further dissect methods based on their underlying mechanisms, including transformation-based, similarity-based, attention-based, and query-based approaches. By providing a comprehensive and structured overview, this survey aims to consolidate current progress, identify key challenges, and inspire future research directions in this rapidly evolving domain. We also maintain a public repository to continuously track and update the latest advances in this promising area.
PhotoArtAgent: Intelligent Photo Retouching with Language Model-Based Artist Agents
May 29, 2025Photo retouching is integral to photographic art, extending far beyond simple technical fixes to heighten emotional expression and narrative depth. While artists leverage expertise to create unique visual effects through deliberate adjustments, non-professional users often rely on automated tools that produce visually pleasing results but lack interpretative depth and interactive transparency. In this paper, we introduce PhotoArtAgent, an intelligent system that combines Vision-Language Models (VLMs) with advanced natural language reasoning to emulate the creative process of a professional artist. The agent performs explicit artistic analysis, plans retouching strategies, and outputs precise parameters to Lightroom through an API. It then evaluates the resulting images and iteratively refines them until the desired artistic vision is achieved. Throughout this process, PhotoArtAgent provides transparent, text-based explanations of its creative rationale, fostering meaningful interaction and user control. Experimental results show that PhotoArtAgent not only surpasses existing automated tools in user studies but also achieves results comparable to those of professional human artists.
HoliTom: Holistic Token Merging for Fast Video Large Language Models
May 28, 2025Video large language models (video LLMs) excel at video comprehension but face significant computational inefficiency due to redundant video tokens. Existing token pruning methods offer solutions. However, approaches operating within the LLM (inner-LLM pruning), such as FastV, incur intrinsic computational overhead in shallow layers. In contrast, methods performing token pruning before the LLM (outer-LLM pruning) primarily address spatial redundancy within individual frames or limited temporal windows, neglecting the crucial global temporal dynamics and correlations across longer video sequences. This leads to sub-optimal spatio-temporal reduction and does not leverage video compressibility fully. Crucially, the synergistic potential and mutual influence of combining these strategies remain unexplored. To further reduce redundancy, we introduce HoliTom, a novel training-free holistic token merging framework. HoliTom employs outer-LLM pruning through global redundancy-aware temporal segmentation, followed by spatial-temporal merging to reduce visual tokens by over 90%, significantly alleviating the LLM's computational burden. Complementing this, we introduce a robust inner-LLM token similarity-based merging approach, designed for superior performance and compatibility with outer-LLM pruning. Evaluations demonstrate our method's promising efficiency-performance trade-off on LLaVA-OneVision-7B, reducing computational costs to 6.9% of FLOPs while maintaining 99.1% of the original performance. Furthermore, we achieve a 2.28x reduction in Time-To-First-Token (TTFT) and a 1.32x acceleration in decoding throughput, highlighting the practical benefits of our integrated pruning approach for efficient video LLMs inference.
Plug-and-Play 1.x-Bit KV Cache Quantization for Video Large Language Models
Mar 20, 2025



Video large language models (VideoLLMs) have demonstrated the capability to process longer video inputs and enable complex reasoning and analysis. However, due to the thousands of visual tokens from the video frames, key-value (KV) cache can significantly increase memory requirements, becoming a bottleneck for inference speed and memory usage. KV cache quantization is a widely used approach to address this problem. In this paper, we find that 2-bit KV quantization of VideoLLMs can hardly hurt the model performance, while the limit of KV cache quantization in even lower bits has not been investigated. To bridge this gap, we introduce VidKV, a plug-and-play KV cache quantization method to compress the KV cache to lower than 2 bits. Specifically, (1) for key, we propose a mixed-precision quantization strategy in the channel dimension, where we perform 2-bit quantization for anomalous channels and 1-bit quantization combined with FFT for normal channels; (2) for value, we implement 1.58-bit quantization while selectively filtering semantically salient visual tokens for targeted preservation, for a better trade-off between precision and model performance. Importantly, our findings suggest that the value cache of VideoLLMs should be quantized in a per-channel fashion instead of the per-token fashion proposed by prior KV cache quantization works for LLMs. Empirically, extensive results with LLaVA-OV-7B and Qwen2.5-VL-7B on six benchmarks show that VidKV effectively compresses the KV cache to 1.5-bit and 1.58-bit precision with almost no performance drop compared to the FP16 counterparts.
Poison as Cure: Visual Noise for Mitigating Object Hallucinations in LVMs
Jan 31, 2025



Large vision-language models (LVMs) extend large language models (LLMs) with visual perception capabilities, enabling them to process and interpret visual information. A major challenge compromising their reliability is object hallucination that LVMs may generate plausible but factually inaccurate information. We propose a novel visual adversarial perturbation (VAP) method to mitigate this hallucination issue. VAP alleviates LVM hallucination by applying strategically optimized visual noise without altering the base model. Our approach formulates hallucination suppression as an optimization problem, leveraging adversarial strategies to generate beneficial visual perturbations that enhance the model's factual grounding and reduce parametric knowledge bias. Extensive experimental results demonstrate that our method consistently reduces object hallucinations across 8 state-of-the-art LVMs, validating its efficacy across diverse evaluations.
Is Oracle Pruning the True Oracle?
Nov 28, 2024Oracle pruning, which selects unimportant weights by minimizing the pruned train loss, has been taken as the foundation for most neural network pruning methods for over 35 years, while few (if not none) have thought about how much the foundation really holds. This paper, for the first time, attempts to examine its validity on modern deep models through empirical correlation analyses and provide reflections on the field of neural network pruning. Specifically, for a typical pruning algorithm with three stages (pertaining, pruning, and retraining), we analyze the model performance correlation before and after retraining. Extensive experiments (37K models are trained) across a wide spectrum of models (LeNet5, VGG, ResNets, ViT, MLLM) and datasets (MNIST and its variants, CIFAR10/CIFAR100, ImageNet-1K, MLLM data) are conducted. The results lead to a surprising conclusion: on modern deep learning models, the performance before retraining is barely correlated with the performance after retraining. Namely, the weights selected by oracle pruning can hardly guarantee a good performance after retraining. This further implies that existing works using oracle pruning to derive pruning criteria may be groundless from the beginning. Further studies suggest the rising task complexity is one factor that makes oracle pruning invalid nowadays. Finally, given the evidence, we argue that the retraining stage in a pruning algorithm should be accounted for when developing any pruning criterion.
DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models
Nov 22, 2024
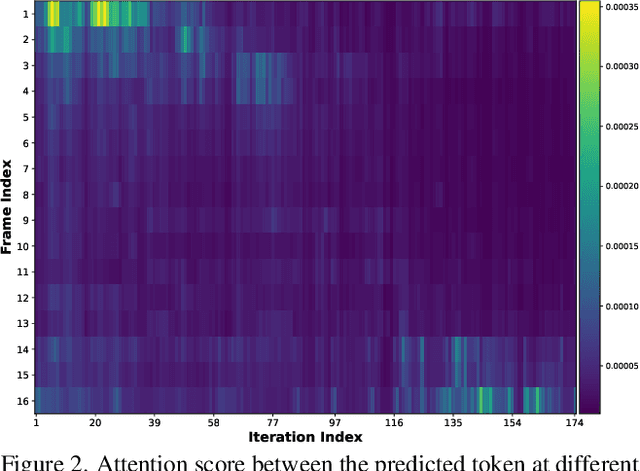


Video large language models (VLLMs) have significantly advanced recently in processing complex video content, yet their inference efficiency remains constrained because of the high computational cost stemming from the thousands of visual tokens generated from the video inputs. We empirically observe that, unlike single image inputs, VLLMs typically attend visual tokens from different frames at different decoding iterations, making a one-shot pruning strategy prone to removing important tokens by mistake. Motivated by this, we present DyCoke, a training-free token compression method to optimize token representation and accelerate VLLMs. DyCoke incorporates a plug-and-play temporal compression module to minimize temporal redundancy by merging redundant tokens across frames, and applies dynamic KV cache reduction to prune spatially redundant tokens selectively. It ensures high-quality inference by dynamically retaining the critical tokens at each decoding step. Extensive experimental results demonstrate that DyCoke can outperform the prior SoTA counterparts, achieving 1.5X inference speedup, 1.4X memory reduction against the baseline VLLM, while still improving the performance, with no training.