 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios
Jul 27, 2025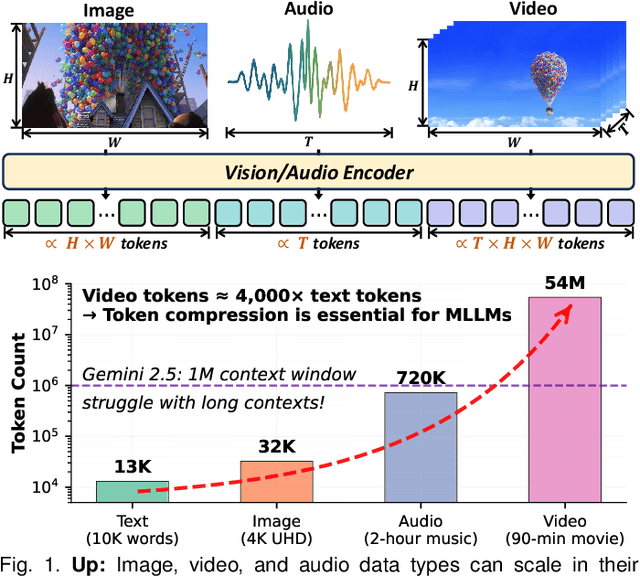
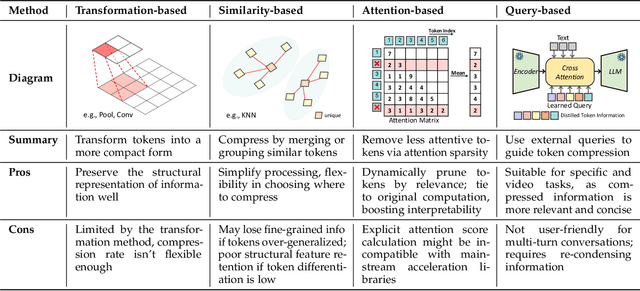
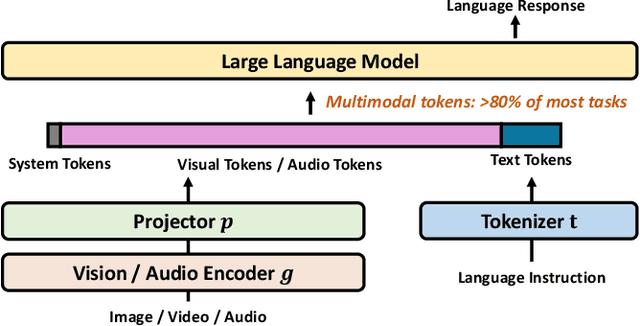
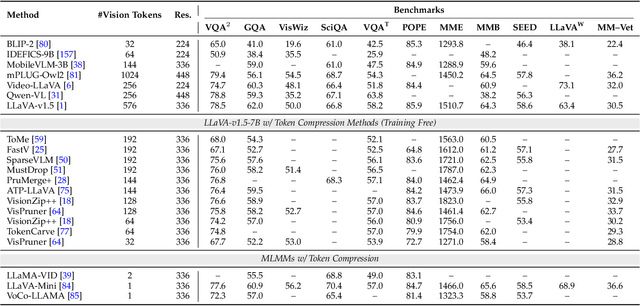
Multimodal large language models (MLLMs) have made remarkable strides, largely driven by their ability to process increasingly long and complex contexts, such as high-resolution images, extended video sequences, and lengthy audio input. While this ability significantly enhances MLLM capabilities, it introduces substantial computational challenges, primarily due to the quadratic complexity of self-attention mechanisms with numerous input tokens. To mitigate these bottlenecks, token compression has emerged as an auspicious and critical approach, efficiently reducing the number of tokens during both training and inference. In this paper, we present the first systematic survey and synthesis of the burgeoning field of multimodal long context token compression. Recognizing that effective compression strategies are deeply tied to the unique characteristics and redundancies of each modality, we categorize existing approaches by their primary data focus, enabling researchers to quickly access and learn methods tailored to their specific area of interest: (1) image-centric compression, which addresses spatial redundancy in visual data; (2) video-centric compression, which tackles spatio-temporal redundancy in dynamic sequences; and (3) audio-centric compression, which handles temporal and spectral redundancy in acoustic signals. Beyond this modality-driven categorization, we further dissect methods based on their underlying mechanisms, including transformation-based, similarity-based, attention-based, and query-based approaches. By providing a comprehensive and structured overview, this survey aims to consolidate current progress, identify key challenges, and inspire future research directions in this rapidly evolving domain. We also maintain a public repository to continuously track and update the latest advances in this promising area.
HoliTom: Holistic Token Merging for Fast Video Large Language Models
May 28, 2025Video large language models (video LLMs) excel at video comprehension but face significant computational inefficiency due to redundant video tokens. Existing token pruning methods offer solutions. However, approaches operating within the LLM (inner-LLM pruning), such as FastV, incur intrinsic computational overhead in shallow layers. In contrast, methods performing token pruning before the LLM (outer-LLM pruning) primarily address spatial redundancy within individual frames or limited temporal windows, neglecting the crucial global temporal dynamics and correlations across longer video sequences. This leads to sub-optimal spatio-temporal reduction and does not leverage video compressibility fully. Crucially, the synergistic potential and mutual influence of combining these strategies remain unexplored. To further reduce redundancy, we introduce HoliTom, a novel training-free holistic token merging framework. HoliTom employs outer-LLM pruning through global redundancy-aware temporal segmentation, followed by spatial-temporal merging to reduce visual tokens by over 90%, significantly alleviating the LLM's computational burden. Complementing this, we introduce a robust inner-LLM token similarity-based merging approach, designed for superior performance and compatibility with outer-LLM pruning. Evaluations demonstrate our method's promising efficiency-performance trade-off on LLaVA-OneVision-7B, reducing computational costs to 6.9% of FLOPs while maintaining 99.1% of the original performance. Furthermore, we achieve a 2.28x reduction in Time-To-First-Token (TTFT) and a 1.32x acceleration in decoding throughput, highlighting the practical benefits of our integrated pruning approach for efficient video LLMs inference.
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
May 14, 2025Unifying image understanding and generation has gained growing attention in recent research on multimodal models. Although design choices for image understanding have been extensively studied, the optimal model architecture and training recipe for a unified framework with image generation remain underexplored. Motivated by the strong potential of autoregressive and diffusion models for high-quality generation and scalability, we conduct a comprehensive study of their use in unified multimodal settings, with emphasis on image representations, modeling objectives, and training strategies. Grounded in these investigations, we introduce a novel approach that employs a diffusion transformer to generate semantically rich CLIP image features, in contrast to conventional VAE-based representations. This design yields both higher training efficiency and improved generative quality. Furthermore, we demonstrate that a sequential pretraining strategy for unified models-first training on image understanding and subsequently on image generation-offers practical advantages by preserving image understanding capability while developing strong image generation ability. Finally, we carefully curate a high-quality instruction-tuning dataset BLIP3o-60k for image generation by prompting GPT-4o with a diverse set of captions covering various scenes, objects, human gestures, and more. Building on our innovative model design, training recipe, and datasets, we develop BLIP3-o, a suite of state-of-the-art unified multimodal models. BLIP3-o achieves superior performance across most of the popular benchmarks spanning both image understanding and generation tasks. To facilitate future research, we fully open-source our models, including code, model weights, training scripts, and pretraining and instruction tuning datasets.
Could AI Trace and Explain the Origins of AI-Generated Images and Text?
Apr 05, 2025AI-generated content is becoming increasingly prevalent in the real world, leading to serious ethical and societal concerns. For instance, adversaries might exploit large multimodal models (LMMs) to create images that violate ethical or legal standards, while paper reviewers may misuse large language models (LLMs) to generate reviews without genuine intellectual effort. While prior work has explored detecting AI-generated images and texts, and occasionally tracing their source models, there is a lack of a systematic and fine-grained comparative study. Important dimensions--such as AI-generated images vs. text, fully vs. partially AI-generated images, and general vs. malicious use cases--remain underexplored. Furthermore, whether AI systems like GPT-4o can explain why certain forged content is attributed to specific generative models is still an open question, with no existing benchmark addressing this. To fill this gap, we introduce AI-FAKER, a comprehensive multimodal dataset with over 280,000 samples spanning multiple LLMs and LMMs, covering both general and malicious use cases for AI-generated images and texts. Our experiments reveal two key findings: (i) AI authorship detection depends not only on the generated output but also on the model's original training intent; and (ii) GPT-4o provides highly consistent but less specific explanations when analyzing content produced by OpenAI's own models, such as DALL-E and GPT-4o itself.
Plug-and-Play 1.x-Bit KV Cache Quantization for Video Large Language Models
Mar 20, 2025



Video large language models (VideoLLMs) have demonstrated the capability to process longer video inputs and enable complex reasoning and analysis. However, due to the thousands of visual tokens from the video frames, key-value (KV) cache can significantly increase memory requirements, becoming a bottleneck for inference speed and memory usage. KV cache quantization is a widely used approach to address this problem. In this paper, we find that 2-bit KV quantization of VideoLLMs can hardly hurt the model performance, while the limit of KV cache quantization in even lower bits has not been investigated. To bridge this gap, we introduce VidKV, a plug-and-play KV cache quantization method to compress the KV cache to lower than 2 bits. Specifically, (1) for key, we propose a mixed-precision quantization strategy in the channel dimension, where we perform 2-bit quantization for anomalous channels and 1-bit quantization combined with FFT for normal channels; (2) for value, we implement 1.58-bit quantization while selectively filtering semantically salient visual tokens for targeted preservation, for a better trade-off between precision and model performance. Importantly, our findings suggest that the value cache of VideoLLMs should be quantized in a per-channel fashion instead of the per-token fashion proposed by prior KV cache quantization works for LLMs. Empirically, extensive results with LLaVA-OV-7B and Qwen2.5-VL-7B on six benchmarks show that VidKV effectively compresses the KV cache to 1.5-bit and 1.58-bit precision with almost no performance drop compared to the FP16 counterparts.
Why Vision Language Models Struggle with Visual Arithmetic? Towards Enhanced Chart and Geometry Understanding
Feb 17, 2025Vision Language Models (VLMs) have achieved remarkable progress in multimodal tasks, yet they often struggle with visual arithmetic, seemingly simple capabilities like object counting or length comparison, which are essential for relevant complex tasks like chart understanding and geometric reasoning. In this work, we first investigate the root causes of this deficiency through a suite of probing tasks focusing on basic visual arithmetic. Our analysis reveals that while pre-trained vision encoders typically capture sufficient information, the text decoder often fails to decode it correctly for arithmetic reasoning. To address this, we propose CogAlign, a novel post-training strategy inspired by Piaget's theory of cognitive development. CogAlign trains VLMs to recognize invariant properties under visual transformations. We demonstrate that this approach significantly improves the performance of three diverse VLMs on our proposed probing tasks. Furthermore, CogAlign enhances performance by an average of 4.6% on CHOCOLATE and 2.9% on MATH-VISION, outperforming or matching supervised fine-tuning methods while requiring only 60% less training data. These results highlight the effectiveness and generalizability of CogAlign in improving fundamental visual arithmetic capabilities and their transfer to downstream tasks.
DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models
Nov 22, 2024
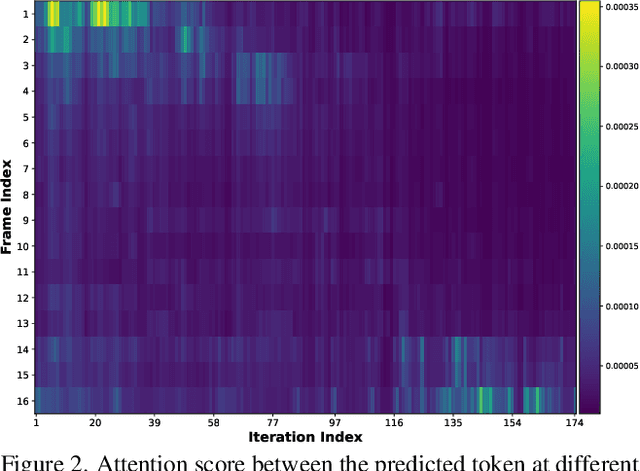


Video large language models (VLLMs) have significantly advanced recently in processing complex video content, yet their inference efficiency remains constrained because of the high computational cost stemming from the thousands of visual tokens generated from the video inputs. We empirically observe that, unlike single image inputs, VLLMs typically attend visual tokens from different frames at different decoding iterations, making a one-shot pruning strategy prone to removing important tokens by mistake. Motivated by this, we present DyCoke, a training-free token compression method to optimize token representation and accelerate VLLMs. DyCoke incorporates a plug-and-play temporal compression module to minimize temporal redundancy by merging redundant tokens across frames, and applies dynamic KV cache reduction to prune spatially redundant tokens selectively. It ensures high-quality inference by dynamically retaining the critical tokens at each decoding step. Extensive experimental results demonstrate that DyCoke can outperform the prior SoTA counterparts, achieving 1.5X inference speedup, 1.4X memory reduction against the baseline VLLM, while still improving the performance, with no training.
xGen-MM-Vid (BLIP-3-Video): You Only Need 32 Tokens to Represent a Video Even in VLMs
Oct 21, 2024



We present xGen-MM-Vid (BLIP-3-Video): a multimodal language model for videos, particularly designed to efficiently capture temporal information over multiple frames. BLIP-3-Video takes advantage of the 'temporal encoder' in addition to the conventional visual tokenizer, which maps a sequence of tokens over multiple frames into a compact set of visual tokens. This enables BLIP3-Video to use much fewer visual tokens than its competing models (e.g., 32 vs. 4608 tokens). We explore different types of temporal encoders, including learnable spatio-temporal pooling as well as sequential models like Token Turing Machines. We experimentally confirm that BLIP-3-Video obtains video question-answering accuracies comparable to much larger state-of-the-art models (e.g., 34B), while being much smaller (i.e., 4B) and more efficient by using fewer visual tokens. The project website is at https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
Triple Point Masking
Sep 26, 2024Existing 3D mask learning methods encounter performance bottlenecks under limited data, and our objective is to overcome this limitation. In this paper, we introduce a triple point masking scheme, named TPM, which serves as a scalable framework for pre-training of masked autoencoders to achieve multi-mask learning for 3D point clouds. Specifically, we augment the baselines with two additional mask choices (i.e., medium mask and low mask) as our core insight is that the recovery process of an object can manifest in diverse ways. Previous high-masking schemes focus on capturing the global representation but lack the fine-grained recovery capability, so that the generated pre-trained weights tend to play a limited role in the fine-tuning process. With the support of the proposed TPM, available methods can exhibit more flexible and accurate completion capabilities, enabling the potential autoencoder in the pre-training stage to consider multiple representations of a single 3D object. In addition, an SVM-guided weight selection module is proposed to fill the encoder parameters for downstream networks with the optimal weight during the fine-tuning stage, maximizing linear accuracy and facilitating the acquisition of intricate representations for new objects. Extensive experiments show that the four baselines equipped with the proposed TPM achieve comprehensive performance improvements on various downstream tasks.
xGen-VideoSyn-1: High-fidelity Text-to-Video Synthesis with Compressed Representations
Aug 22, 2024



We present xGen-VideoSyn-1, a text-to-video (T2V) generation model capable of producing realistic scenes from textual descriptions. Building on recent advancements, such as OpenAI's Sora, we explore the latent diffusion model (LDM) architecture and introduce a video variational autoencoder (VidVAE). VidVAE compresses video data both spatially and temporally, significantly reducing the length of visual tokens and the computational demands associated with generating long-sequence videos. To further address the computational costs, we propose a divide-and-merge strategy that maintains temporal consistency across video segments. Our Diffusion Transformer (DiT) model incorporates spatial and temporal self-attention layers, enabling robust generalization across different timeframes and aspect ratios. We have devised a data processing pipeline from the very beginning and collected over 13M high-quality video-text pairs. The pipeline includes multiple steps such as clipping, text detection, motion estimation, aesthetics scoring, and dense captioning based on our in-house video-LLM model. Training the VidVAE and DiT models required approximately 40 and 642 H100 days, respectively. Our model supports over 14-second 720p video generation in an end-to-end way and demonstrates competitive performance against state-of-the-art T2V models.