 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChainRank-DPO: Chain Rank Direct Preference Optimization for LLM Rankers
Dec 18, 2024
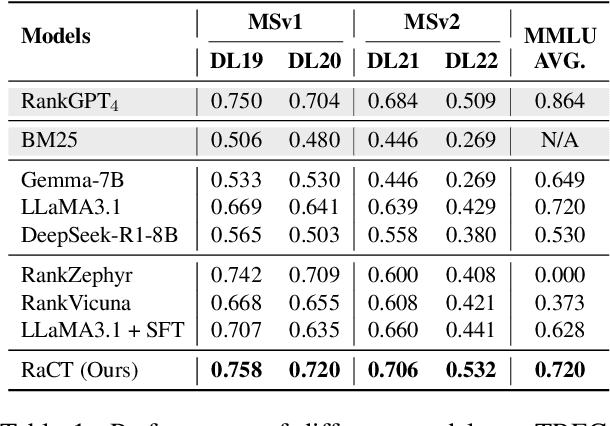

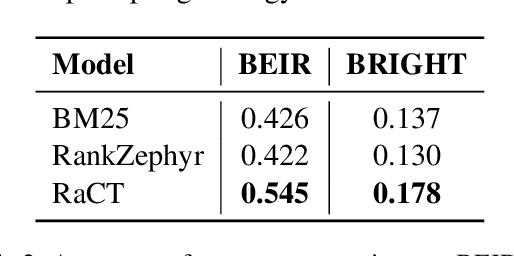
Large language models (LLMs) have demonstrated remarkable effectiveness in text reranking through works like RankGPT, leveraging their human-like reasoning about relevance. However, supervised fine-tuning for ranking often diminishes these models' general-purpose capabilities, including the crucial reasoning abilities that make them valuable for ranking. We introduce a novel approach integrating Chain-of-Thought prompting with an SFT-DPO (Supervised Fine-Tuning followed by Direct Preference Optimization) pipeline to preserve these capabilities while improving ranking performance. Our experiments on TREC 2019 and 2020 Deep Learning datasets show that our approach outperforms the state-of-the-art RankZephyr while maintaining strong performance on the Massive Multitask Language Understanding (MMLU) benchmark, demonstrating effective preservation of general-purpose capabilities through thoughtful fine-tuning strategies. Our code and data will be publicly released upon the acceptance of the paper.
STLLaVA-Med: Self-Training Large Language and Vision Assistant for Medical
Jun 28, 2024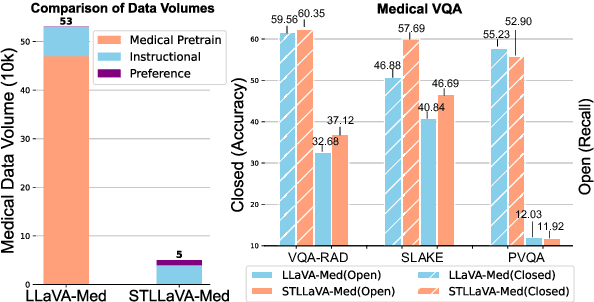

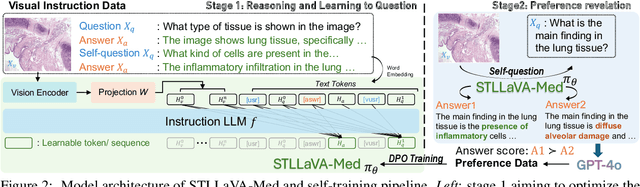
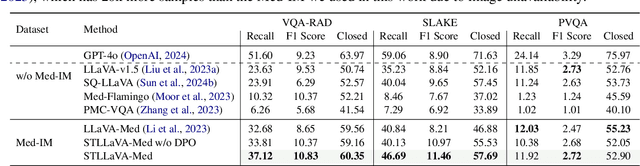
Large Vision-Language Models (LVLMs) have shown significant potential in assisting medical diagnosis by leveraging extensive biomedical datasets. However, the advancement of medical image understanding and reasoning critically depends on building high-quality visual instruction data, which is costly and labor-intensive to obtain, particularly in the medical domain. To mitigate this data-starving issue, we introduce Self-Training Large Language and Vision Assistant for Medical (STLLaVA-Med). The proposed method is designed to train a policy model (an LVLM) capable of auto-generating medical visual instruction data to improve data efficiency, guided through Direct Preference Optimization (DPO). Specifically, a more powerful and larger LVLM (e.g., GPT-4o) is involved as a biomedical expert to oversee the DPO fine-tuning process on the auto-generated data, encouraging the policy model to align efficiently with human preferences. We validate the efficacy and data efficiency of STLLaVA-Med across three major medical Visual Question Answering (VQA) benchmarks, demonstrating competitive zero-shot performance with the utilization of only 9% of the medical data.
DELRec: Distilling Sequential Pattern to Enhance LLM-based Recommendation
Jun 18, 2024



Sequential recommendation (SR) tasks enhance recommendation accuracy by capturing the connection between users' past interactions and their changing preferences. Conventional models often focus solely on capturing sequential patterns within the training data, neglecting the broader context and semantic information embedded in item titles from external sources. This limits their predictive power and adaptability. Recently, large language models (LLMs) have shown promise in SR tasks due to their advanced understanding capabilities and strong generalization abilities. Researchers have attempted to enhance LLMs' recommendation performance by incorporating information from SR models. However, previous approaches have encountered problems such as 1) only influencing LLMs at the result level; 2) increased complexity of LLMs recommendation methods leading to reduced interpretability; 3) incomplete understanding and utilization of SR models information by LLMs. To address these problems, we proposes a novel framework, DELRec, which aims to extract knowledge from SR models and enable LLMs to easily comprehend and utilize this supplementary information for more effective sequential recommendations. DELRec consists of two main stages: 1) SR Models Pattern Distilling, focusing on extracting behavioral patterns exhibited by SR models using soft prompts through two well-designed strategies; 2) LLMs-based Sequential Recommendation, aiming to fine-tune LLMs to effectively use the distilled auxiliary information to perform SR tasks. Extensive experimental results conducted on three real datasets validate the effectiveness of the DELRec framework.
Prototypical Transformer as Unified Motion Learners
Jun 03, 2024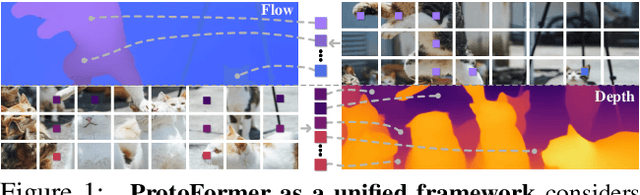
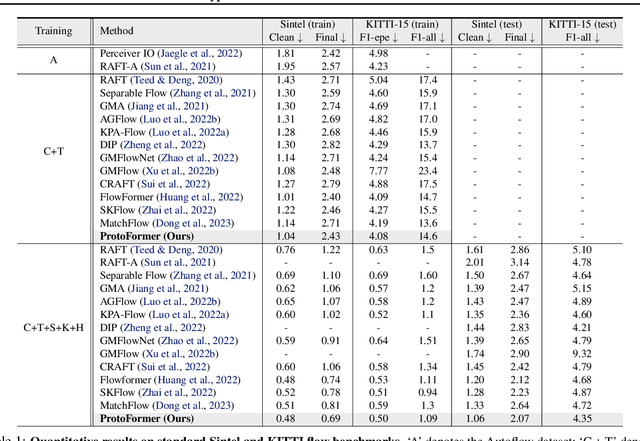
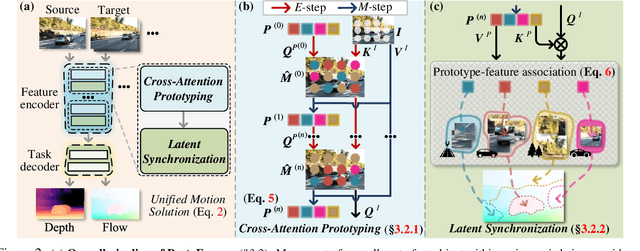
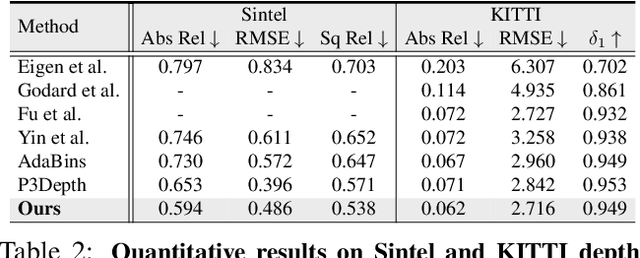
In this work, we introduce the Prototypical Transformer (ProtoFormer), a general and unified framework that approaches various motion tasks from a prototype perspective. ProtoFormer seamlessly integrates prototype learning with Transformer by thoughtfully considering motion dynamics, introducing two innovative designs. First, Cross-Attention Prototyping discovers prototypes based on signature motion patterns, providing transparency in understanding motion scenes. Second, Latent Synchronization guides feature representation learning via prototypes, effectively mitigating the problem of motion uncertainty. Empirical results demonstrate that our approach achieves competitive performance on popular motion tasks such as optical flow and scene depth. Furthermore, it exhibits generality across various downstream tasks, including object tracking and video stabilization.
Text Is MASS: Modeling as Stochastic Embedding for Text-Video Retrieval
Mar 26, 2024The increasing prevalence of video clips has sparked growing interest in text-video retrieval. Recent advances focus on establishing a joint embedding space for text and video, relying on consistent embedding representations to compute similarity. However, the text content in existing datasets is generally short and concise, making it hard to fully describe the redundant semantics of a video. Correspondingly, a single text embedding may be less expressive to capture the video embedding and empower the retrieval. In this study, we propose a new stochastic text modeling method T-MASS, i.e., text is modeled as a stochastic embedding, to enrich text embedding with a flexible and resilient semantic range, yielding a text mass. To be specific, we introduce a similarity-aware radius module to adapt the scale of the text mass upon the given text-video pairs. Plus, we design and develop a support text regularization to further control the text mass during the training. The inference pipeline is also tailored to fully exploit the text mass for accurate retrieval. Empirical evidence suggests that T-MASS not only effectively attracts relevant text-video pairs while distancing irrelevant ones, but also enables the determination of precise text embeddings for relevant pairs. Our experimental results show a substantial improvement of T-MASS over baseline (3% to 6.3% by R@1). Also, T-MASS achieves state-of-the-art performance on five benchmark datasets, including MSRVTT, LSMDC, DiDeMo, VATEX, and Charades.
SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant
Mar 17, 2024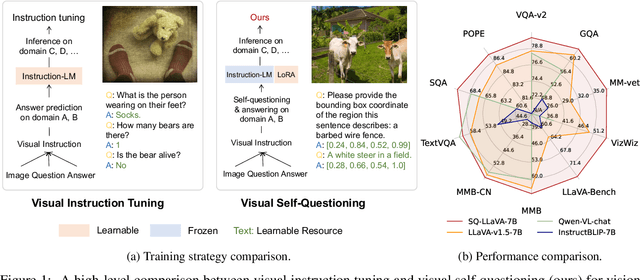
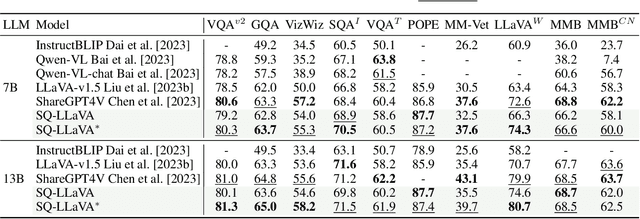
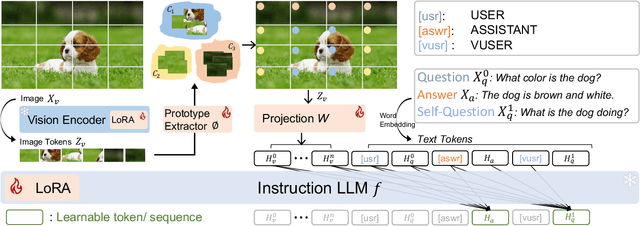
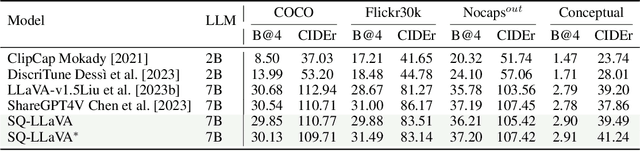
Recent advancements in the vision-language model have shown notable generalization in vision-language tasks after visual instruction tuning. However, bridging the gap between the pre-trained vision encoder and the large language models becomes the whole network's bottleneck. To improve cross-modality alignment, existing works usually consider more visual instruction data covering a broader range of vision tasks to fine-tune the model for question-answering, which are costly to obtain. However, the image contains rich contextual information that has been largely under-explored. This paper first attempts to harness this overlooked context within visual instruction data, training the model to self-supervised `learning' how to ask high-quality questions. In this way, we introduce a novel framework named SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant. SQ-LLaVA exhibits proficiency in generating flexible and meaningful image-related questions while analyzing the visual clue and prior language knowledge, signifying an advanced level of generalized visual understanding. Moreover, fine-tuning SQ-LLaVA on higher-quality instruction data shows a consistent performance improvement compared with traditional visual-instruction tuning methods. This improvement highlights the efficacy of self-questioning techniques in achieving a deeper and more nuanced comprehension of visual content across various contexts.