 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Specific Prompt Fusion Discovery via Differentiable Search in Vision Foundation Models
Jun 24, 2026Visual prompt tuning has emerged as a parameter-efficient fine-tuning approach for adapting large-scale Vision Transformers (ViTs) to downstream tasks. As its learnable prompts are applied in input and feature spaces, prior to jointly going through attention in transformer layers, the most commonly used scheme for fusing image and prompt tokens is concatenation or addition. In this paper, we aim to study a fundamental yet essential problem in visual prompt tuning: whether a single fusion scheme tends to yield better results, and whether that would be beneficial to develop a hybrid fusion scheme. To this end, we formulate the task as a bi-level optimization problem, and solve it leveraging differentiable architecture search. In this context, the learnable prompts and their fusion schemes are jointly optimized. To enrich the search space in the architecture search, we propose two additional fusion schemes, namely, affine transformation and cross-attention, in addition to concatenation and addition. Extensive experiments on 34 datasets spanning VTAB-1k, FGVC, and HTA show consistent gains over prompt-tuning baselines. With a frozen ViT backbone, our method delivers a favorable accuracy--latency--parameter trade-off compared with VPT-Deep and recent variants. Our findings reveal that how prompts fuse with image tokens plays a significant role in visual prompt tuning, and a hybrid fusion fashion can more effectively leverage layer semantics of ViTs, contributing a novel perspective for visual prompt-tuning research.
A-SelecT: Automatic Timestep Selection for Diffusion Transformer Representation Learning
Mar 25, 2026Diffusion models have significantly reshaped the field of generative artificial intelligence and are now increasingly explored for their capacity in discriminative representation learning. Diffusion Transformer (DiT) has recently gained attention as a promising alternative to conventional U-Net-based diffusion models, demonstrating a promising avenue for downstream discriminative tasks via generative pre-training. However, its current training efficiency and representational capacity remain largely constrained due to the inadequate timestep searching and insufficient exploitation of DiT-specific feature representations. In light of this view, we introduce Automatically Selected Timestep (A-SelecT) that dynamically pinpoints DiT's most information-rich timestep from the selected transformer feature in a single run, eliminating the need for both computationally intensive exhaustive timestep searching and suboptimal discriminative feature selection. Extensive experiments on classification and segmentation benchmarks demonstrate that DiT, empowered by A-SelecT, surpasses all prior diffusion-based attempts efficiently and effectively.
Towards Long-Form Spatio-Temporal Video Grounding
Feb 26, 2026In real scenarios, videos can span several minutes or even hours. However, existing research on spatio-temporal video grounding (STVG), given a textual query, mainly focuses on localizing targets in short videos of tens of seconds, typically less than one minute, which limits real-world applications. In this paper, we explore Long-Form STVG (LF-STVG), which aims to locate targets in long-term videos. Compared with short videos, long-term videos contain much longer temporal spans and more irrelevant information, making it difficult for existing STVG methods that process all frames at once. To address this challenge, we propose an AutoRegressive Transformer architecture for LF-STVG, termed ART-STVG. Unlike conventional STVG methods that require the entire video sequence to make predictions at once, ART-STVG treats the video as streaming input and processes frames sequentially, enabling efficient handling of long videos. To model spatio-temporal context, we design spatial and temporal memory banks and apply them to the decoders. Since memories from different moments are not always relevant to the current frame, we introduce simple yet effective memory selection strategies to provide more relevant information to the decoders, significantly improving performance. Furthermore, instead of parallel spatial and temporal localization, we propose a cascaded spatio-temporal design that connects the spatial decoder to the temporal decoder, allowing fine-grained spatial cues to assist complex temporal localization in long videos. Experiments on newly extended LF-STVG datasets show that ART-STVG significantly outperforms state-of-the-art methods, while achieving competitive performance on conventional short-form STVG.
TokenSeek: Memory Efficient Fine Tuning via Instance-Aware Token Ditching
Jan 27, 2026Fine tuning has been regarded as a de facto approach for adapting large language models (LLMs) to downstream tasks, but the high training memory consumption inherited from LLMs makes this process inefficient. Among existing memory efficient approaches, activation-related optimization has proven particularly effective, as activations consistently dominate overall memory consumption. Although prior arts offer various activation optimization strategies, their data-agnostic nature ultimately results in ineffective and unstable fine tuning. In this paper, we propose TokenSeek, a universal plugin solution for various transformer-based models through instance-aware token seeking and ditching, achieving significant fine-tuning memory savings (e.g., requiring only 14.8% of the memory on Llama3.2 1B) with on-par or even better performance. Furthermore, our interpretable token seeking process reveals the underlying reasons for its effectiveness, offering valuable insights for future research on token efficiency. Homepage: https://runjia.tech/iclr_tokenseek/
On-the-Fly VLA Adaptation via Test-Time Reinforcement Learning
Jan 13, 2026Vision-Language-Action models have recently emerged as a powerful paradigm for general-purpose robot learning, enabling agents to map visual observations and natural-language instructions into executable robotic actions. Though popular, they are primarily trained via supervised fine-tuning or training-time reinforcement learning, requiring explicit fine-tuning phases, human interventions, or controlled data collection. Consequently, existing methods remain unsuitable for challenging simulated- or physical-world deployments, where robots must respond autonomously and flexibly to evolving environments. To address this limitation, we introduce a Test-Time Reinforcement Learning for VLAs (TT-VLA), a framework that enables on-the-fly policy adaptation during inference. TT-VLA formulates a dense reward mechanism that leverages step-by-step task-progress signals to refine action policies during test time while preserving the SFT/RL-trained priors, making it an effective supplement to current VLA models. Empirical results show that our approach enhances overall adaptability, stability, and task success in dynamic, previously unseen scenarios under simulated and real-world settings. We believe TT-VLA offers a principled step toward self-improving, deployment-ready VLAs.
Resolving the Ambiguity of Complete-to-Partial Point Cloud Registration for Image-Guided Liver Surgery with Patches-to-Partial Matching
Dec 26, 2024In image-guided liver surgery, the initial rigid alignment between preoperative and intraoperative data, often represented as point clouds, is crucial for providing sub-surface information from preoperative CT/MRI images to the surgeon during the procedure. Currently, this alignment is typically performed using semi-automatic methods, which, while effective to some extent, are prone to errors that demand manual correction. Point cloud correspondence-based registration methods are promising to serve as a fully automatic solution. However, they may struggle in scenarios with limited intraoperative surface visibility, a common challenge in liver surgery, particularly in laparoscopic procedures, which we refer to as complete-to-partial ambiguity. We first illustrate this ambiguity by evaluating the performance of state-of-the-art learning-based point cloud registration methods on our carefully constructed in silico and in vitro datasets. Then, we propose a patches-to-partial matching strategy as a plug-and-play module to resolve the ambiguity, which can be seamlessly integrated into learning-based registration methods without disrupting their end-to-end structure. It has proven effective and efficient in improving registration performance for cases with limited intraoperative visibility. The constructed benchmark and the proposed module establish a solid foundation for advancing applications of point cloud correspondence-based registration methods in image-guided liver surgery.
Exploring the Adversarial Vulnerabilities of Vision-Language-Action Models in Robotics
Nov 22, 2024



Recently in robotics, Vision-Language-Action (VLA) models have emerged as a transformative approach, enabling robots to execute complex tasks by integrating visual and linguistic inputs within an end-to-end learning framework. While VLA models offer significant capabilities, they also introduce new attack surfaces, making them vulnerable to adversarial attacks. With these vulnerabilities largely unexplored, this paper systematically quantifies the robustness of VLA-based robotic systems. Recognizing the unique demands of robotic execution, our attack objectives target the inherent spatial and functional characteristics of robotic systems. In particular, we introduce an untargeted position-aware attack objective that leverages spatial foundations to destabilize robotic actions, and a targeted attack objective that manipulates the robotic trajectory. Additionally, we design an adversarial patch generation approach that places a small, colorful patch within the camera's view, effectively executing the attack in both digital and physical environments. Our evaluation reveals a marked degradation in task success rates, with up to a 100\% reduction across a suite of simulated robotic tasks, highlighting critical security gaps in current VLA architectures. By unveiling these vulnerabilities and proposing actionable evaluation metrics, this work advances both the understanding and enhancement of safety for VLA-based robotic systems, underscoring the necessity for developing robust defense strategies prior to physical-world deployments.
Visual Fourier Prompt Tuning
Nov 02, 2024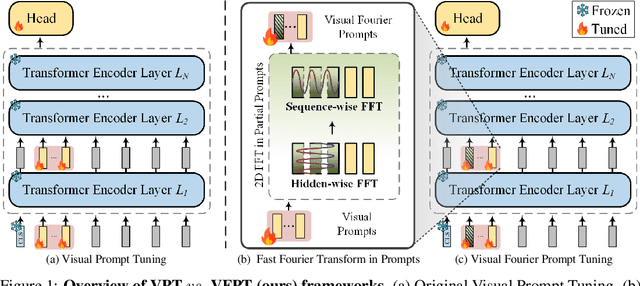
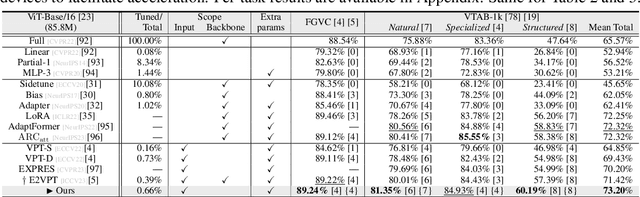
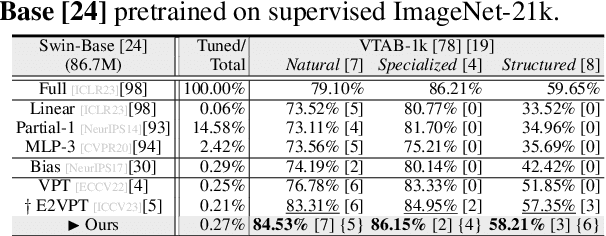
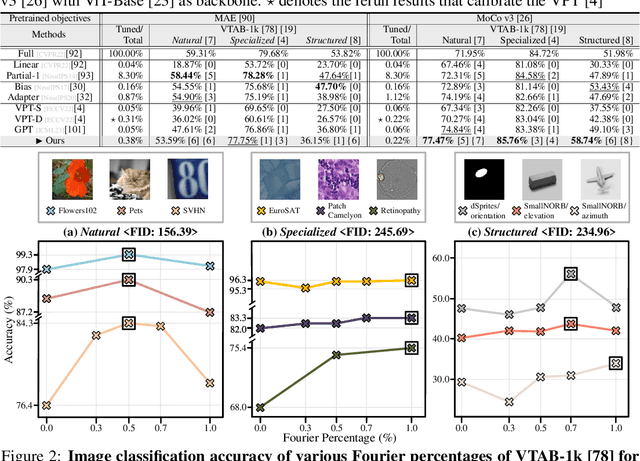
With the scale of vision Transformer-based models continuing to grow, finetuning these large-scale pretrained models for new tasks has become increasingly parameter-intensive. Visual prompt tuning is introduced as a parameter-efficient finetuning (PEFT) method to this trend. Despite its successes, a notable research challenge persists within almost all PEFT approaches: significant performance degradation is observed when there is a substantial disparity between the datasets applied in pretraining and finetuning phases. To address this challenge, we draw inspiration from human visual cognition, and propose the Visual Fourier Prompt Tuning (VFPT) method as a general and effective solution for adapting large-scale transformer-based models. Our approach innovatively incorporates the Fast Fourier Transform into prompt embeddings and harmoniously considers both spatial and frequency domain information. Apart from its inherent simplicity and intuitiveness, VFPT exhibits superior performance across all datasets, offering a general solution to dataset challenges, irrespective of data disparities. Empirical results demonstrate that our approach outperforms current state-of-the-art baselines on two benchmarks, with low parameter usage (e.g., 0.57% of model parameters on VTAB-1k) and notable performance enhancements (e.g., 73.20% of mean accuracy on VTAB-1k). Our code is avaliable at https://github.com/runtsang/VFPT.
AMD: Automatic Multi-step Distillation of Large-scale Vision Models
Jul 05, 2024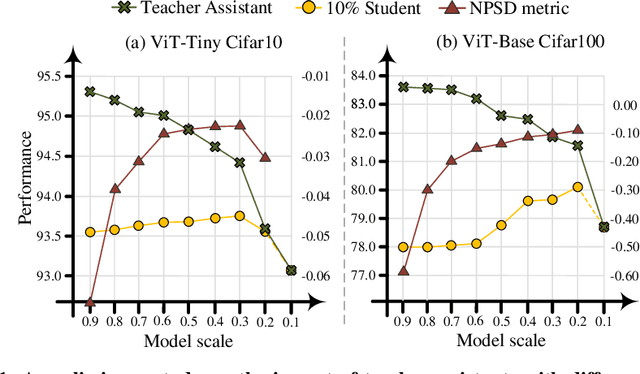

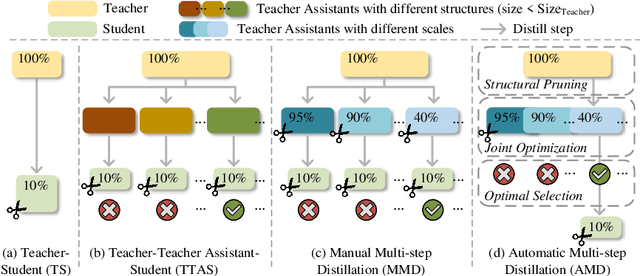

Transformer-based architectures have become the de-facto standard models for diverse vision tasks owing to their superior performance. As the size of the models continues to scale up, model distillation becomes extremely important in various real applications, particularly on devices limited by computational resources. However, prevailing knowledge distillation methods exhibit diminished efficacy when confronted with a large capacity gap between the teacher and the student, e.g, 10x compression rate. In this paper, we present a novel approach named Automatic Multi-step Distillation (AMD) for large-scale vision model compression. In particular, our distillation process unfolds across multiple steps. Initially, the teacher undergoes distillation to form an intermediate teacher-assistant model, which is subsequently distilled further to the student. An efficient and effective optimization framework is introduced to automatically identify the optimal teacher-assistant that leads to the maximal student performance. We conduct extensive experiments on multiple image classification datasets, including CIFAR-10, CIFAR-100, and ImageNet. The findings consistently reveal that our approach outperforms several established baselines, paving a path for future knowledge distillation methods on large-scale vision models.
Self-supervised Adversarial Training of Monocular Depth Estimation against Physical-World Attacks
Jun 09, 2024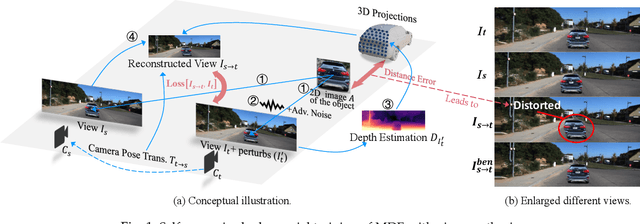

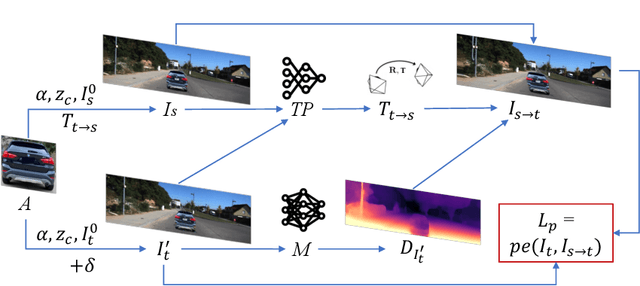
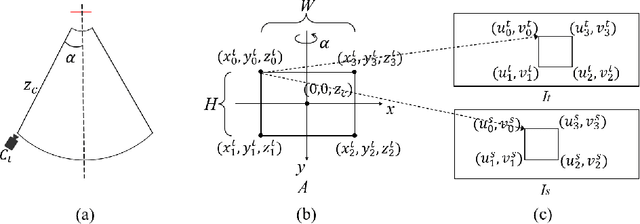
Monocular Depth Estimation (MDE) plays a vital role in applications such as autonomous driving. However, various attacks target MDE models, with physical attacks posing significant threats to system security. Traditional adversarial training methods, which require ground-truth labels, are not directly applicable to MDE models that lack ground-truth depth. Some self-supervised model hardening techniques (e.g., contrastive learning) overlook the domain knowledge of MDE, resulting in suboptimal performance. In this work, we introduce a novel self-supervised adversarial training approach for MDE models, leveraging view synthesis without the need for ground-truth depth. We enhance adversarial robustness against real-world attacks by incorporating L_0-norm-bounded perturbation during training. We evaluate our method against supervised learning-based and contrastive learning-based approaches specifically designed for MDE. Our experiments with two representative MDE networks demonstrate improved robustness against various adversarial attacks, with minimal impact on benign performance.