 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSGA-Net: Stepwise Spatial Global-local Aggregation Networks for for Autonomous Driving
Paper and Code
May 29, 2024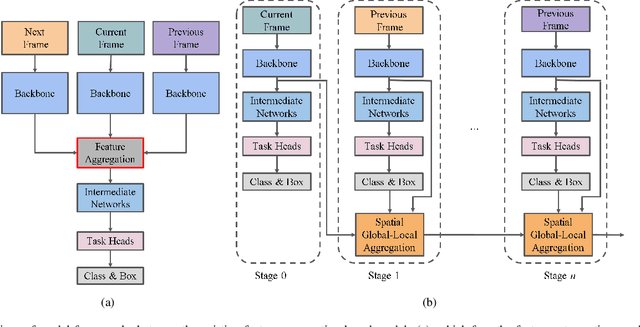
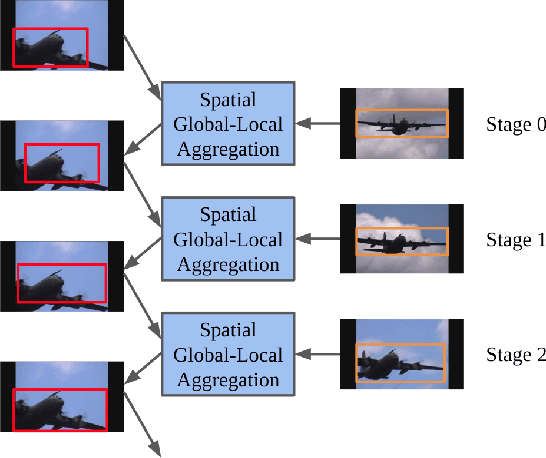
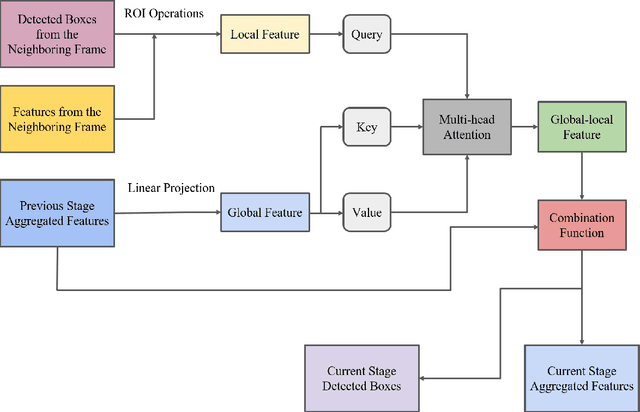

Visual-based perception is the key module for autonomous driving. Among those visual perception tasks, video object detection is a primary yet challenging one because of feature degradation caused by fast motion or multiple poses. Current models usually aggregate features from the neighboring frames to enhance the object representations for the task heads to generate more accurate predictions. Though getting better performance, these methods rely on the information from the future frames and suffer from high computational complexity. Meanwhile, the aggregation process is not reconfigurable during the inference time. These issues make most of the existing models infeasible for online applications. To solve these problems, we introduce a stepwise spatial global-local aggregation network. Our proposed models mainly contain three parts: 1). Multi-stage stepwise network gradually refines the predictions and object representations from the previous stage; 2). Spatial global-local aggregation fuses the local information from the neighboring frames and global semantics from the current frame to eliminate the feature degradation; 3). Dynamic aggregation strategy stops the aggregation process early based on the refinement results to remove redundancy and improve efficiency. Extensive experiments on the ImageNet VID benchmark validate the effectiveness and efficiency of our proposed models.