 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for High-Fidelity Generation of CAR-T/NK Immunological Synapse Images
Feb 03, 2026Chimeric antigen receptor (CAR)-T and NK cell immunotherapies have transformed cancer treatment, and recent studies suggest that the quality of the CAR-T/NK cell immunological synapse (IS) may serve as a functional biomarker for predicting therapeutic efficacy. Accurate detection and segmentation of CAR-T/NK IS structures using artificial neural networks (ANNs) can greatly increase the speed and reliability of IS quantification. However, a persistent challenge is the limited size of annotated microscopy datasets, which restricts the ability of ANNs to generalize. To address this challenge, we integrate two complementary data-augmentation frameworks. First, we employ Instance Aware Automatic Augmentation (IAAA), an automated, instance-preserving augmentation method that generates synthetic CAR-T/NK IS images and corresponding segmentation masks by applying optimized augmentation policies to original IS data. IAAA supports multiple imaging modalities (e.g., fluorescence and brightfield) and can be applied directly to CAR-T/NK IS images derived from patient samples. In parallel, we introduce a Semantic-Aware AI Augmentation (SAAA) pipeline that combines a diffusion-based mask generator with a Pix2Pix conditional image synthesizer. This second method enables the creation of diverse, anatomically realistic segmentation masks and produces high-fidelity CAR-T/NK IS images aligned with those masks, further expanding the training corpus beyond what IAAA alone can provide. Together, these augmentation strategies generate synthetic images whose visual and structural properties closely match real IS data, significantly improving CAR-T/NK IS detection and segmentation performance. By enhancing the robustness and accuracy of IS quantification, this work supports the development of more reliable imaging-based biomarkers for predicting patient response to CAR-T/NK immunotherapy.
TokenSeek: Memory Efficient Fine Tuning via Instance-Aware Token Ditching
Jan 27, 2026Fine tuning has been regarded as a de facto approach for adapting large language models (LLMs) to downstream tasks, but the high training memory consumption inherited from LLMs makes this process inefficient. Among existing memory efficient approaches, activation-related optimization has proven particularly effective, as activations consistently dominate overall memory consumption. Although prior arts offer various activation optimization strategies, their data-agnostic nature ultimately results in ineffective and unstable fine tuning. In this paper, we propose TokenSeek, a universal plugin solution for various transformer-based models through instance-aware token seeking and ditching, achieving significant fine-tuning memory savings (e.g., requiring only 14.8% of the memory on Llama3.2 1B) with on-par or even better performance. Furthermore, our interpretable token seeking process reveals the underlying reasons for its effectiveness, offering valuable insights for future research on token efficiency. Homepage: https://runjia.tech/iclr_tokenseek/
On-the-Fly VLA Adaptation via Test-Time Reinforcement Learning
Jan 13, 2026Vision-Language-Action models have recently emerged as a powerful paradigm for general-purpose robot learning, enabling agents to map visual observations and natural-language instructions into executable robotic actions. Though popular, they are primarily trained via supervised fine-tuning or training-time reinforcement learning, requiring explicit fine-tuning phases, human interventions, or controlled data collection. Consequently, existing methods remain unsuitable for challenging simulated- or physical-world deployments, where robots must respond autonomously and flexibly to evolving environments. To address this limitation, we introduce a Test-Time Reinforcement Learning for VLAs (TT-VLA), a framework that enables on-the-fly policy adaptation during inference. TT-VLA formulates a dense reward mechanism that leverages step-by-step task-progress signals to refine action policies during test time while preserving the SFT/RL-trained priors, making it an effective supplement to current VLA models. Empirical results show that our approach enhances overall adaptability, stability, and task success in dynamic, previously unseen scenarios under simulated and real-world settings. We believe TT-VLA offers a principled step toward self-improving, deployment-ready VLAs.
KGIF: Optimizing Relation-Aware Recommendations with Knowledge Graph Information Fusion
Jan 07, 2025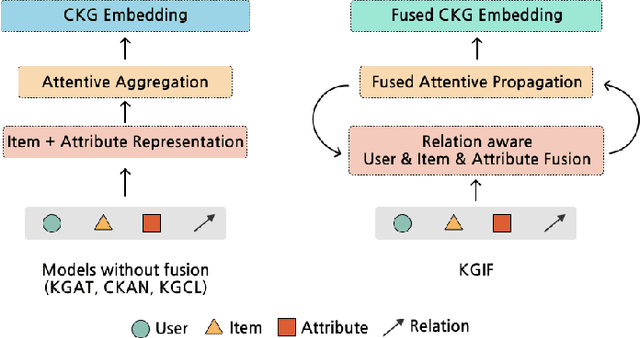
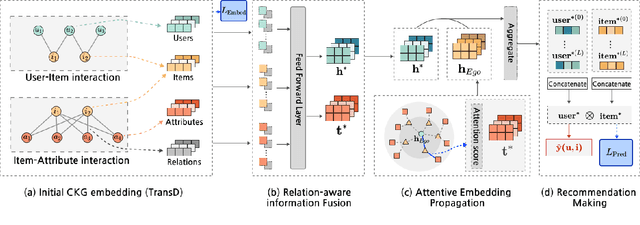
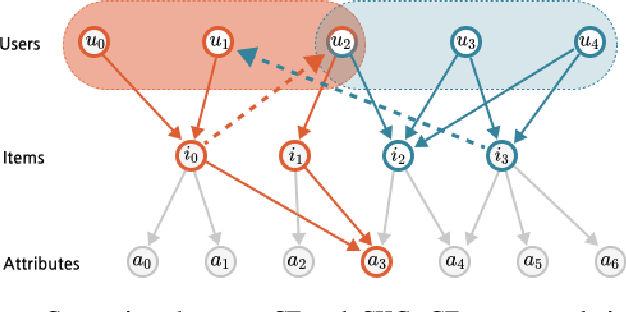
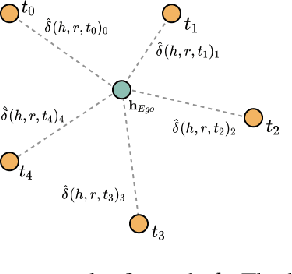
While deep-learning-enabled recommender systems demonstrate strong performance benchmarks, many struggle to adapt effectively in real-world environments due to limited use of user-item relationship data and insufficient transparency in recommendation generation. Traditional collaborative filtering approaches fail to integrate multifaceted item attributes, and although Factorization Machines account for item-specific details, they overlook broader relational patterns. Collaborative knowledge graph-based models have progressed by embedding user-item interactions with item-attribute relationships, offering a holistic perspective on interconnected entities. However, these models frequently aggregate attribute and interaction data in an implicit manner, leaving valuable relational nuances underutilized. This study introduces the Knowledge Graph Attention Network with Information Fusion (KGIF), a specialized framework designed to merge entity and relation embeddings explicitly through a tailored self-attention mechanism. The KGIF framework integrates reparameterization via dynamic projection vectors, enabling embeddings to adaptively represent intricate relationships within knowledge graphs. This explicit fusion enhances the interplay between user-item interactions and item-attribute relationships, providing a nuanced balance between user-centric and item-centric representations. An attentive propagation mechanism further optimizes knowledge graph embeddings, capturing multi-layered interaction patterns. The contributions of this work include an innovative method for explicit information fusion, improved robustness for sparse knowledge graphs, and the ability to generate explainable recommendations through interpretable path visualization.
Exploring the Adversarial Vulnerabilities of Vision-Language-Action Models in Robotics
Nov 22, 2024



Recently in robotics, Vision-Language-Action (VLA) models have emerged as a transformative approach, enabling robots to execute complex tasks by integrating visual and linguistic inputs within an end-to-end learning framework. While VLA models offer significant capabilities, they also introduce new attack surfaces, making them vulnerable to adversarial attacks. With these vulnerabilities largely unexplored, this paper systematically quantifies the robustness of VLA-based robotic systems. Recognizing the unique demands of robotic execution, our attack objectives target the inherent spatial and functional characteristics of robotic systems. In particular, we introduce an untargeted position-aware attack objective that leverages spatial foundations to destabilize robotic actions, and a targeted attack objective that manipulates the robotic trajectory. Additionally, we design an adversarial patch generation approach that places a small, colorful patch within the camera's view, effectively executing the attack in both digital and physical environments. Our evaluation reveals a marked degradation in task success rates, with up to a 100\% reduction across a suite of simulated robotic tasks, highlighting critical security gaps in current VLA architectures. By unveiling these vulnerabilities and proposing actionable evaluation metrics, this work advances both the understanding and enhancement of safety for VLA-based robotic systems, underscoring the necessity for developing robust defense strategies prior to physical-world deployments.
Target-driven Attack for Large Language Models
Nov 13, 2024



Current large language models (LLM) provide a strong foundation for large-scale user-oriented natural language tasks. Many users can easily inject adversarial text or instructions through the user interface, thus causing LLM model security challenges like the language model not giving the correct answer. Although there is currently a large amount of research on black-box attacks, most of these black-box attacks use random and heuristic strategies. It is unclear how these strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we propose our target-driven black-box attack method to maximize the KL divergence between the conditional probabilities of the clean text and the attack text to redefine the attack's goal. We transform the distance maximization problem into two convex optimization problems based on the attack goal to solve the attack text and estimate the covariance. Furthermore, the projected gradient descent algorithm solves the vector corresponding to the attack text. Our target-driven black-box attack approach includes two attack strategies: token manipulation and misinformation attack. Experimental results on multiple Large Language Models and datasets demonstrate the effectiveness of our attack method.
Visual Fourier Prompt Tuning
Nov 02, 2024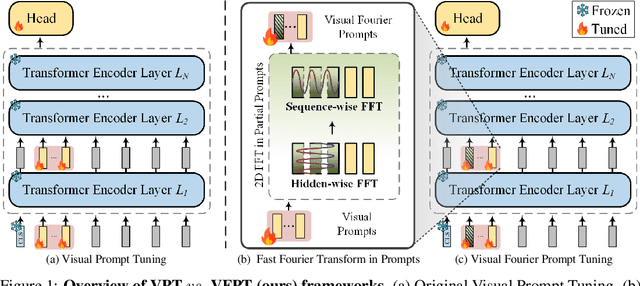
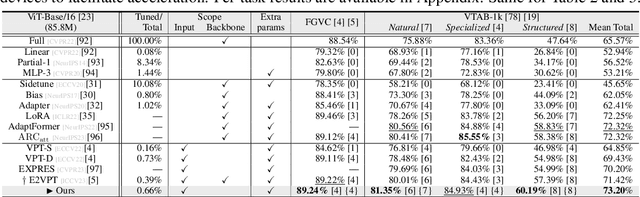
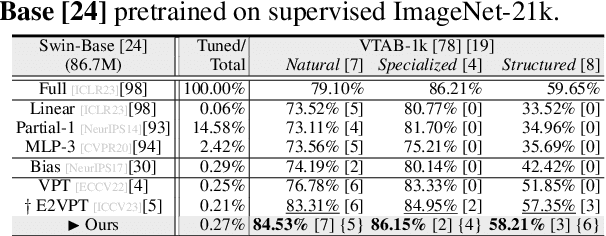
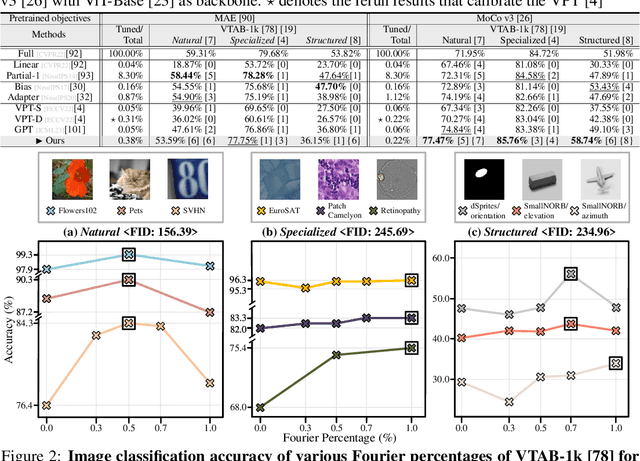
With the scale of vision Transformer-based models continuing to grow, finetuning these large-scale pretrained models for new tasks has become increasingly parameter-intensive. Visual prompt tuning is introduced as a parameter-efficient finetuning (PEFT) method to this trend. Despite its successes, a notable research challenge persists within almost all PEFT approaches: significant performance degradation is observed when there is a substantial disparity between the datasets applied in pretraining and finetuning phases. To address this challenge, we draw inspiration from human visual cognition, and propose the Visual Fourier Prompt Tuning (VFPT) method as a general and effective solution for adapting large-scale transformer-based models. Our approach innovatively incorporates the Fast Fourier Transform into prompt embeddings and harmoniously considers both spatial and frequency domain information. Apart from its inherent simplicity and intuitiveness, VFPT exhibits superior performance across all datasets, offering a general solution to dataset challenges, irrespective of data disparities. Empirical results demonstrate that our approach outperforms current state-of-the-art baselines on two benchmarks, with low parameter usage (e.g., 0.57% of model parameters on VTAB-1k) and notable performance enhancements (e.g., 73.20% of mean accuracy on VTAB-1k). Our code is avaliable at https://github.com/runtsang/VFPT.
Visual Agents as Fast and Slow Thinkers
Aug 16, 2024



Achieving human-level intelligence requires refining cognitive distinctions between System 1 and System 2 thinking. While contemporary AI, driven by large language models, demonstrates human-like traits, it falls short of genuine cognition. Transitioning from structured benchmarks to real-world scenarios presents challenges for visual agents, often leading to inaccurate and overly confident responses. To address the challenge, we introduce FaST, which incorporates the Fast and Slow Thinking mechanism into visual agents. FaST employs a switch adapter to dynamically select between System 1/2 modes, tailoring the problem-solving approach to different task complexity. It tackles uncertain and unseen objects by adjusting model confidence and integrating new contextual data. With this novel design, we advocate a flexible system, hierarchical reasoning capabilities, and a transparent decision-making pipeline, all of which contribute to its ability to emulate human-like cognitive processes in visual intelligence. Empirical results demonstrate that FaST outperforms various well-known baselines, achieving 80.8% accuracy over VQA^{v2} for visual question answering and 48.7% GIoU score over ReasonSeg for reasoning segmentation, demonstrate FaST's superior performance. Extensive testing validates the efficacy and robustness of FaST's core components, showcasing its potential to advance the development of cognitive visual agents in AI systems.
Radiance Field Learners As UAV First-Person Viewers
Aug 10, 2024
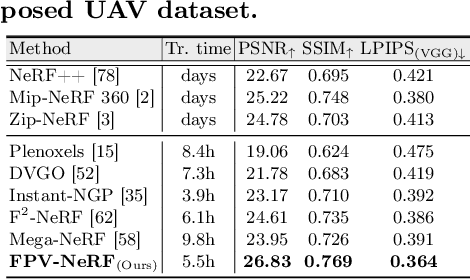
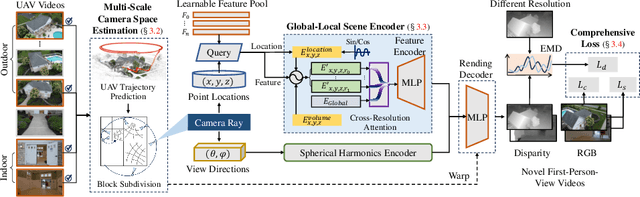
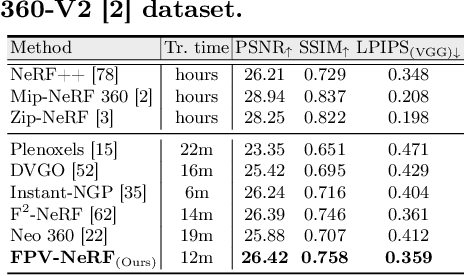
First-Person-View (FPV) holds immense potential for revolutionizing the trajectory of Unmanned Aerial Vehicles (UAVs), offering an exhilarating avenue for navigating complex building structures. Yet, traditional Neural Radiance Field (NeRF) methods face challenges such as sampling single points per iteration and requiring an extensive array of views for supervision. UAV videos exacerbate these issues with limited viewpoints and significant spatial scale variations, resulting in inadequate detail rendering across diverse scales. In response, we introduce FPV-NeRF, addressing these challenges through three key facets: (1) Temporal consistency. Leveraging spatio-temporal continuity ensures seamless coherence between frames; (2) Global structure. Incorporating various global features during point sampling preserves space integrity; (3) Local granularity. Employing a comprehensive framework and multi-resolution supervision for multi-scale scene feature representation tackles the intricacies of UAV video spatial scales. Additionally, due to the scarcity of publicly available FPV videos, we introduce an innovative view synthesis method using NeRF to generate FPV perspectives from UAV footage, enhancing spatial perception for drones. Our novel dataset spans diverse trajectories, from outdoor to indoor environments, in the UAV domain, differing significantly from traditional NeRF scenarios. Through extensive experiments encompassing both interior and exterior building structures, FPV-NeRF demonstrates a superior understanding of the UAV flying space, outperforming state-of-the-art methods in our curated UAV dataset. Explore our project page for further insights: https://fpv-nerf.github.io/.
* Accepted to ECCV 2024
Diff-PIC: Revolutionizing Particle-In-Cell Simulation for Advancing Nuclear Fusion with Diffusion Models
Aug 03, 2024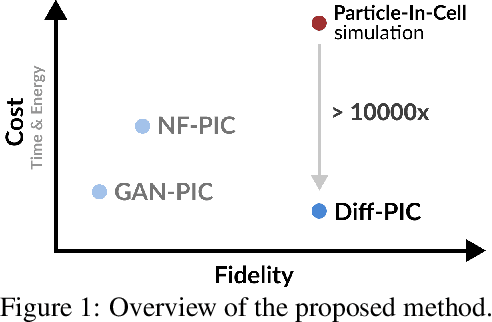
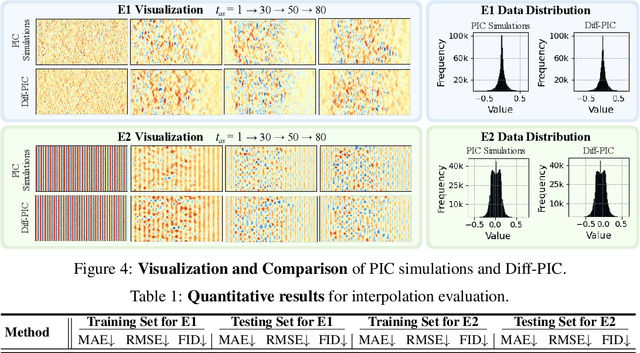
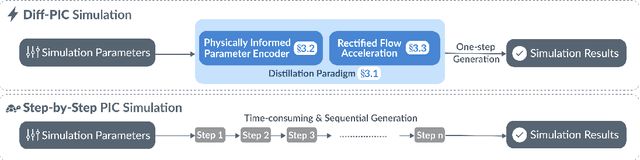
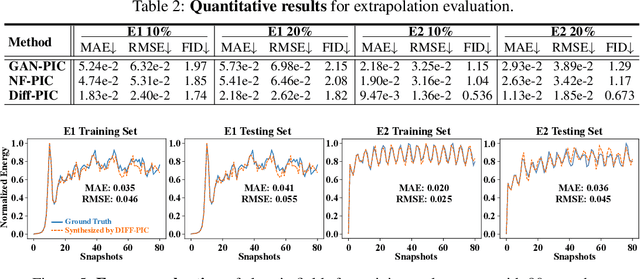
Sustainable energy is a crucial global challenge, and recent breakthroughs in nuclear fusion ignition underscore the potential of harnessing energy extracted from nuclear fusion in everyday life, thereby drawing significant attention to fusion ignition research, especially Laser-Plasma Interaction (LPI). Unfortunately, the complexity of LPI at ignition scale renders theory-based analysis nearly impossible -- instead, it has to rely heavily on Particle-in-Cell (PIC) simulations, which is extremely computationally intensive, making it a major bottleneck in advancing fusion ignition. In response, this work introduces Diff-PIC, a novel paradigm that leverages conditional diffusion models as a computationally efficient alternative to PIC simulations for generating high-fidelity scientific data. Specifically, we design a distillation paradigm to distill the physical patterns captured by PIC simulations into diffusion models, demonstrating both theoretical and practical feasibility. Moreover, to ensure practical effectiveness, we provide solutions for two critical challenges: (1) We develop a physically-informed conditional diffusion model that can learn and generate meaningful embeddings for mathematically continuous physical conditions. This model offers algorithmic generalization and adaptable transferability, effectively capturing the complex relationships between physical conditions and simulation outcomes; and (2) We employ the rectified flow technique to make our model a one-step conditional diffusion model, enhancing its efficiency further while maintaining high fidelity and physical validity. Diff-PIC establishes a new paradigm for using diffusion models to overcome the computational barriers in nuclear fusion research, setting a benchmark for future innovations and advancements in this field.