 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Dual-Region Augmentation for Reduced Reliance on Large Amounts of Labeled Data
Apr 17, 2025This paper introduces a novel dual-region augmentation approach designed to reduce reliance on large-scale labeled datasets while improving model robustness and adaptability across diverse computer vision tasks, including source-free domain adaptation (SFDA) and person re-identification (ReID). Our method performs targeted data transformations by applying random noise perturbations to foreground objects and spatially shuffling background patches. This effectively increases the diversity of the training data, improving model robustness and generalization. Evaluations on the PACS dataset for SFDA demonstrate that our augmentation strategy consistently outperforms existing methods, achieving significant accuracy improvements in both single-target and multi-target adaptation settings. By augmenting training data through structured transformations, our method enables model generalization across domains, providing a scalable solution for reducing reliance on manually annotated datasets. Furthermore, experiments on Market-1501 and DukeMTMC-reID datasets validate the effectiveness of our approach for person ReID, surpassing traditional augmentation techniques.
AMD: Automatic Multi-step Distillation of Large-scale Vision Models
Jul 05, 2024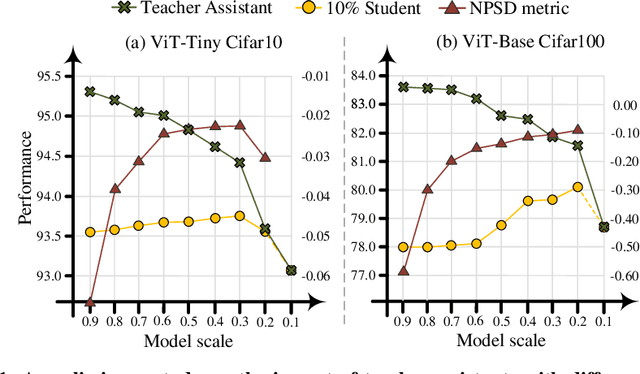

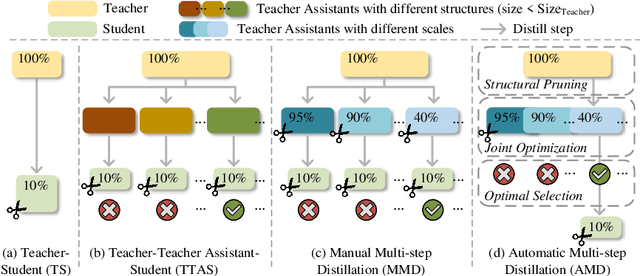

Transformer-based architectures have become the de-facto standard models for diverse vision tasks owing to their superior performance. As the size of the models continues to scale up, model distillation becomes extremely important in various real applications, particularly on devices limited by computational resources. However, prevailing knowledge distillation methods exhibit diminished efficacy when confronted with a large capacity gap between the teacher and the student, e.g, 10x compression rate. In this paper, we present a novel approach named Automatic Multi-step Distillation (AMD) for large-scale vision model compression. In particular, our distillation process unfolds across multiple steps. Initially, the teacher undergoes distillation to form an intermediate teacher-assistant model, which is subsequently distilled further to the student. An efficient and effective optimization framework is introduced to automatically identify the optimal teacher-assistant that leads to the maximal student performance. We conduct extensive experiments on multiple image classification datasets, including CIFAR-10, CIFAR-100, and ImageNet. The findings consistently reveal that our approach outperforms several established baselines, paving a path for future knowledge distillation methods on large-scale vision models.
Prototypical Transformer as Unified Motion Learners
Jun 03, 2024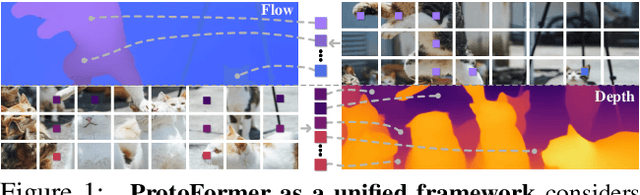
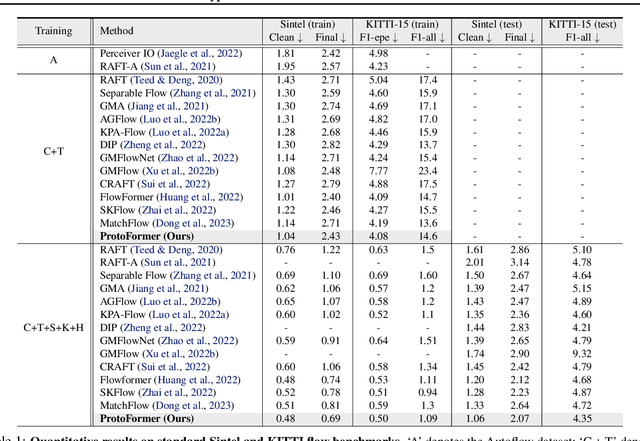
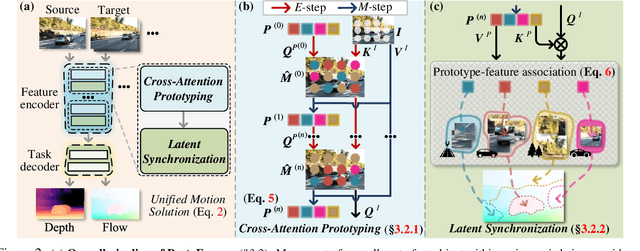
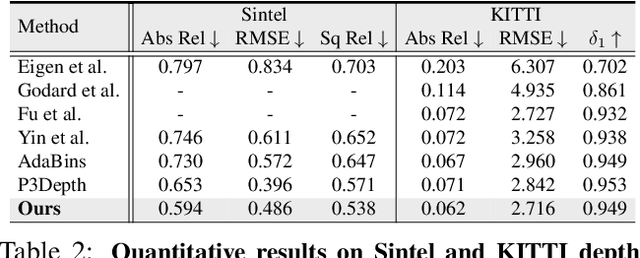
In this work, we introduce the Prototypical Transformer (ProtoFormer), a general and unified framework that approaches various motion tasks from a prototype perspective. ProtoFormer seamlessly integrates prototype learning with Transformer by thoughtfully considering motion dynamics, introducing two innovative designs. First, Cross-Attention Prototyping discovers prototypes based on signature motion patterns, providing transparency in understanding motion scenes. Second, Latent Synchronization guides feature representation learning via prototypes, effectively mitigating the problem of motion uncertainty. Empirical results demonstrate that our approach achieves competitive performance on popular motion tasks such as optical flow and scene depth. Furthermore, it exhibits generality across various downstream tasks, including object tracking and video stabilization.