 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuffle PatchMix Augmentation with Confidence-Margin Weighted Pseudo-Labels for Enhanced Source-Free Domain Adaptation
May 30, 2025This work investigates Source-Free Domain Adaptation (SFDA), where a model adapts to a target domain without access to source data. A new augmentation technique, Shuffle PatchMix (SPM), and a novel reweighting strategy are introduced to enhance performance. SPM shuffles and blends image patches to generate diverse and challenging augmentations, while the reweighting strategy prioritizes reliable pseudo-labels to mitigate label noise. These techniques are particularly effective on smaller datasets like PACS, where overfitting and pseudo-label noise pose greater risks. State-of-the-art results are achieved on three major benchmarks: PACS, VisDA-C, and DomainNet-126. Notably, on PACS, improvements of 7.3% (79.4% to 86.7%) and 7.2% are observed in single-target and multi-target settings, respectively, while gains of 2.8% and 0.7% are attained on DomainNet-126 and VisDA-C. This combination of advanced augmentation and robust pseudo-label reweighting establishes a new benchmark for SFDA. The code is available at: https://github.com/PrasannaPulakurthi/SPM
Effective Dual-Region Augmentation for Reduced Reliance on Large Amounts of Labeled Data
Apr 17, 2025This paper introduces a novel dual-region augmentation approach designed to reduce reliance on large-scale labeled datasets while improving model robustness and adaptability across diverse computer vision tasks, including source-free domain adaptation (SFDA) and person re-identification (ReID). Our method performs targeted data transformations by applying random noise perturbations to foreground objects and spatially shuffling background patches. This effectively increases the diversity of the training data, improving model robustness and generalization. Evaluations on the PACS dataset for SFDA demonstrate that our augmentation strategy consistently outperforms existing methods, achieving significant accuracy improvements in both single-target and multi-target adaptation settings. By augmenting training data through structured transformations, our method enables model generalization across domains, providing a scalable solution for reducing reliance on manually annotated datasets. Furthermore, experiments on Market-1501 and DukeMTMC-reID datasets validate the effectiveness of our approach for person ReID, surpassing traditional augmentation techniques.
AMD: Automatic Multi-step Distillation of Large-scale Vision Models
Jul 05, 2024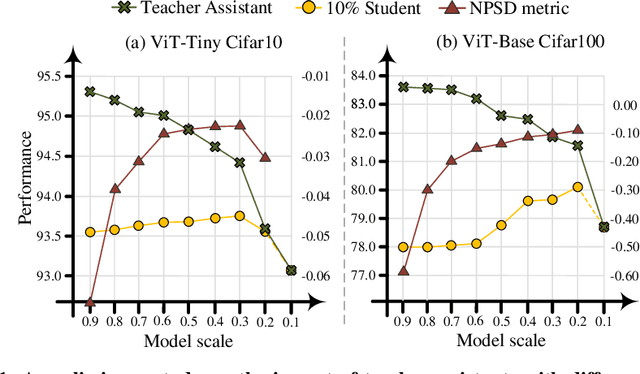

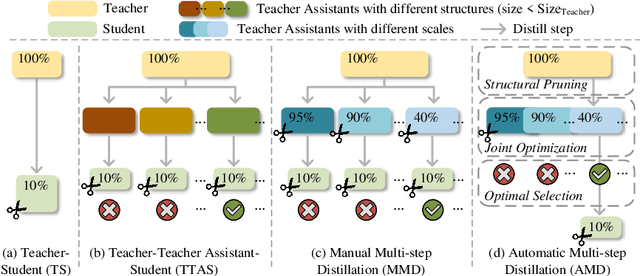

Transformer-based architectures have become the de-facto standard models for diverse vision tasks owing to their superior performance. As the size of the models continues to scale up, model distillation becomes extremely important in various real applications, particularly on devices limited by computational resources. However, prevailing knowledge distillation methods exhibit diminished efficacy when confronted with a large capacity gap between the teacher and the student, e.g, 10x compression rate. In this paper, we present a novel approach named Automatic Multi-step Distillation (AMD) for large-scale vision model compression. In particular, our distillation process unfolds across multiple steps. Initially, the teacher undergoes distillation to form an intermediate teacher-assistant model, which is subsequently distilled further to the student. An efficient and effective optimization framework is introduced to automatically identify the optimal teacher-assistant that leads to the maximal student performance. We conduct extensive experiments on multiple image classification datasets, including CIFAR-10, CIFAR-100, and ImageNet. The findings consistently reveal that our approach outperforms several established baselines, paving a path for future knowledge distillation methods on large-scale vision models.
Text Is MASS: Modeling as Stochastic Embedding for Text-Video Retrieval
Mar 26, 2024The increasing prevalence of video clips has sparked growing interest in text-video retrieval. Recent advances focus on establishing a joint embedding space for text and video, relying on consistent embedding representations to compute similarity. However, the text content in existing datasets is generally short and concise, making it hard to fully describe the redundant semantics of a video. Correspondingly, a single text embedding may be less expressive to capture the video embedding and empower the retrieval. In this study, we propose a new stochastic text modeling method T-MASS, i.e., text is modeled as a stochastic embedding, to enrich text embedding with a flexible and resilient semantic range, yielding a text mass. To be specific, we introduce a similarity-aware radius module to adapt the scale of the text mass upon the given text-video pairs. Plus, we design and develop a support text regularization to further control the text mass during the training. The inference pipeline is also tailored to fully exploit the text mass for accurate retrieval. Empirical evidence suggests that T-MASS not only effectively attracts relevant text-video pairs while distancing irrelevant ones, but also enables the determination of precise text embeddings for relevant pairs. Our experimental results show a substantial improvement of T-MASS over baseline (3% to 6.3% by R@1). Also, T-MASS achieves state-of-the-art performance on five benchmark datasets, including MSRVTT, LSMDC, DiDeMo, VATEX, and Charades.
Image Translation as Diffusion Visual Programmers
Jan 30, 2024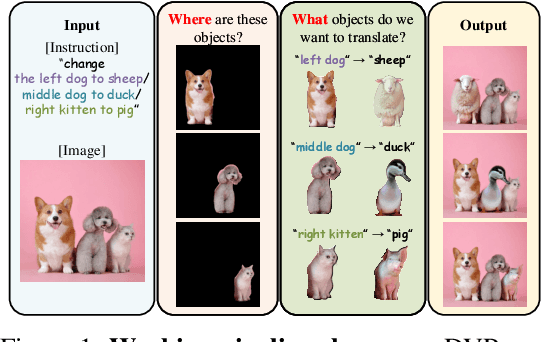



We introduce the novel Diffusion Visual Programmer (DVP), a neuro-symbolic image translation framework. Our proposed DVP seamlessly embeds a condition-flexible diffusion model within the GPT architecture, orchestrating a coherent sequence of visual programs (i.e., computer vision models) for various pro-symbolic steps, which span RoI identification, style transfer, and position manipulation, facilitating transparent and controllable image translation processes. Extensive experiments demonstrate DVP's remarkable performance, surpassing concurrent arts. This success can be attributed to several key features of DVP: First, DVP achieves condition-flexible translation via instance normalization, enabling the model to eliminate sensitivity caused by the manual guidance and optimally focus on textual descriptions for high-quality content generation. Second, the framework enhances in-context reasoning by deciphering intricate high-dimensional concepts in feature spaces into more accessible low-dimensional symbols (e.g., [Prompt], [RoI object]), allowing for localized, context-free editing while maintaining overall coherence. Last but not least, DVP improves systemic controllability and explainability by offering explicit symbolic representations at each programming stage, empowering users to intuitively interpret and modify results. Our research marks a substantial step towards harmonizing artificial image translation processes with cognitive intelligence, promising broader applications.