 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenSeek: Memory Efficient Fine Tuning via Instance-Aware Token Ditching
Jan 27, 2026Fine tuning has been regarded as a de facto approach for adapting large language models (LLMs) to downstream tasks, but the high training memory consumption inherited from LLMs makes this process inefficient. Among existing memory efficient approaches, activation-related optimization has proven particularly effective, as activations consistently dominate overall memory consumption. Although prior arts offer various activation optimization strategies, their data-agnostic nature ultimately results in ineffective and unstable fine tuning. In this paper, we propose TokenSeek, a universal plugin solution for various transformer-based models through instance-aware token seeking and ditching, achieving significant fine-tuning memory savings (e.g., requiring only 14.8% of the memory on Llama3.2 1B) with on-par or even better performance. Furthermore, our interpretable token seeking process reveals the underlying reasons for its effectiveness, offering valuable insights for future research on token efficiency. Homepage: https://runjia.tech/iclr_tokenseek/
Towards Explainable Quantum AI: Informing the Encoder Selection of Quantum Neural Networks via Visualization
Dec 16, 2025
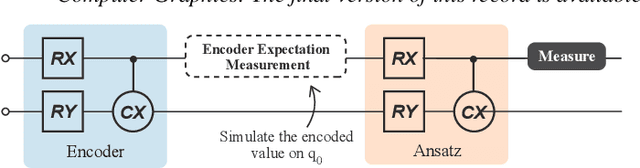
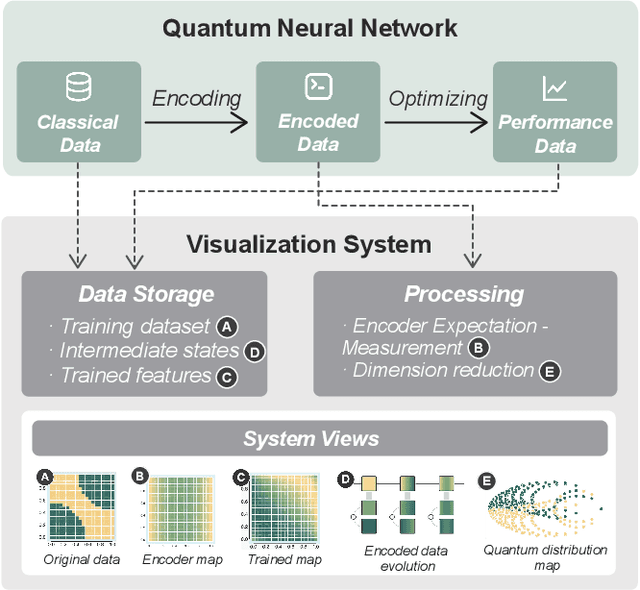
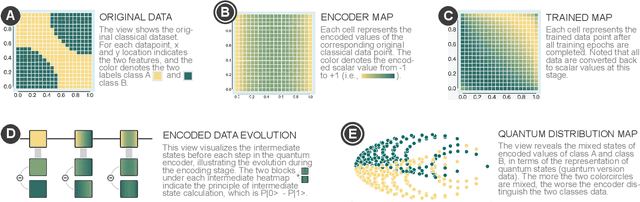
Quantum Neural Networks (QNNs) represent a promising fusion of quantum computing and neural network architectures, offering speed-ups and efficient processing of high-dimensional, entangled data. A crucial component of QNNs is the encoder, which maps classical input data into quantum states. However, choosing suitable encoders remains a significant challenge, largely due to the lack of systematic guidance and the trial-and-error nature of current approaches. This process is further impeded by two key challenges: (1) the difficulty in evaluating encoded quantum states prior to training, and (2) the lack of intuitive methods for analyzing an encoder's ability to effectively distinguish data features. To address these issues, we introduce a novel visualization tool, XQAI-Eyes, which enables QNN developers to compare classical data features with their corresponding encoded quantum states and to examine the mixed quantum states across different classes. By bridging classical and quantum perspectives, XQAI-Eyes facilitates a deeper understanding of how encoders influence QNN performance. Evaluations across diverse datasets and encoder designs demonstrate XQAI-Eyes's potential to support the exploration of the relationship between encoder design and QNN effectiveness, offering a holistic and transparent approach to optimizing quantum encoders. Moreover, domain experts used XQAI-Eyes to derive two key practices for quantum encoder selection, grounded in the principles of pattern preservation and feature mapping.
Can Large Language Models Understand Intermediate Representations?
Feb 07, 2025Intermediate Representations (IRs) are essential in compiler design and program analysis, yet their comprehension by Large Language Models (LLMs) remains underexplored. This paper presents a pioneering empirical study to investigate the capabilities of LLMs, including GPT-4, GPT-3, Gemma 2, LLaMA 3.1, and Code Llama, in understanding IRs. We analyze their performance across four tasks: Control Flow Graph (CFG) reconstruction, decompilation, code summarization, and execution reasoning. Our results indicate that while LLMs demonstrate competence in parsing IR syntax and recognizing high-level structures, they struggle with control flow reasoning, execution semantics, and loop handling. Specifically, they often misinterpret branching instructions, omit critical IR operations, and rely on heuristic-based reasoning, leading to errors in CFG reconstruction, IR decompilation, and execution reasoning. The study underscores the necessity for IR-specific enhancements in LLMs, recommending fine-tuning on structured IR datasets and integration of explicit control flow models to augment their comprehension and handling of IR-related tasks.
Adopting Trustworthy AI for Sleep Disorder Prediction: Deep Time Series Analysis with Temporal Attention Mechanism and Counterfactual Explanations
Dec 25, 2024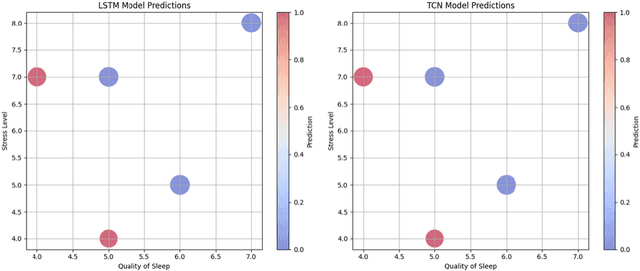
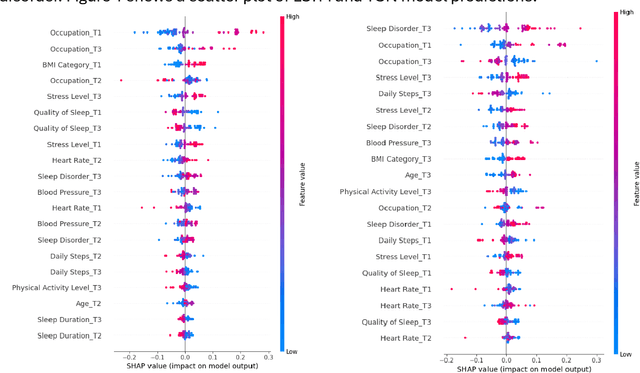

Sleep disorders have a major impact on both lifestyle and health. Effective sleep disorder prediction from lifestyle and physiological data can provide essential details for early intervention. This research utilizes three deep time series models and facilitates them with explainability approaches for sleep disorder prediction. Specifically, our approach adopts Temporal Convolutional Networks (TCN), Long Short-Term Memory (LSTM) for time series data analysis, and Temporal Fusion Transformer model (TFT). Meanwhile, the temporal attention mechanism and counterfactual explanation with SHapley Additive exPlanations (SHAP) approach are employed to ensure dependable, accurate, and interpretable predictions. Finally, using a large dataset of sleep health measures, our evaluation demonstrates the effect of our method in predicting sleep disorders.
MNIST-Fraction: Enhancing Math Education with AI-Driven Fraction Detection and Analysis
Dec 11, 2024Mathematics education, a crucial and basic field, significantly influences students' learning in related subjects and their future careers. Utilizing artificial intelligence to interpret and comprehend math problems in education is not yet fully explored. This is due to the scarcity of quality datasets and the intricacies of processing handwritten information. In this paper, we present a novel contribution to the field of mathematics education through the development of MNIST-Fraction, a dataset inspired by the renowned MNIST, specifically tailored for the recognition and understanding of handwritten math fractions. Our approach is the utilization of deep learning, specifically Convolutional Neural Networks (CNNs), for the recognition and understanding of handwritten math fractions to effectively detect and analyze fractions, along with their numerators and denominators. This capability is pivotal in calculating the value of fractions, a fundamental aspect of math learning. The MNIST-Fraction dataset is designed to closely mimic real-world scenarios, providing a reliable and relevant resource for AI-driven educational tools. Furthermore, we conduct a comprehensive comparison of our dataset with the original MNIST dataset using various classifiers, demonstrating the effectiveness and versatility of MNIST-Fraction in both detection and classification tasks. This comparative analysis not only validates the practical utility of our dataset but also offers insights into its potential applications in math education. To foster collaboration and further research within the computational and educational communities. Our work aims to bridge the gap in high-quality educational resources for math learning, offering a valuable tool for both educators and researchers in the field.
Radiance Field Learners As UAV First-Person Viewers
Aug 10, 2024
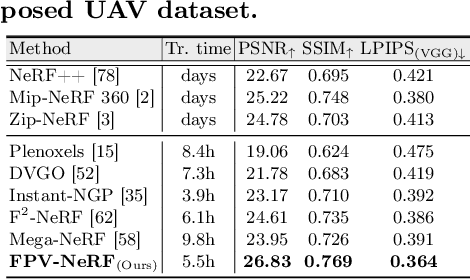
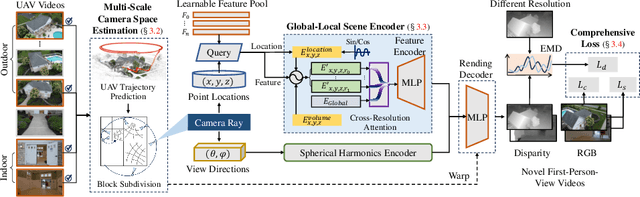
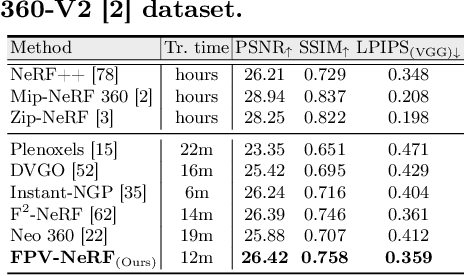
First-Person-View (FPV) holds immense potential for revolutionizing the trajectory of Unmanned Aerial Vehicles (UAVs), offering an exhilarating avenue for navigating complex building structures. Yet, traditional Neural Radiance Field (NeRF) methods face challenges such as sampling single points per iteration and requiring an extensive array of views for supervision. UAV videos exacerbate these issues with limited viewpoints and significant spatial scale variations, resulting in inadequate detail rendering across diverse scales. In response, we introduce FPV-NeRF, addressing these challenges through three key facets: (1) Temporal consistency. Leveraging spatio-temporal continuity ensures seamless coherence between frames; (2) Global structure. Incorporating various global features during point sampling preserves space integrity; (3) Local granularity. Employing a comprehensive framework and multi-resolution supervision for multi-scale scene feature representation tackles the intricacies of UAV video spatial scales. Additionally, due to the scarcity of publicly available FPV videos, we introduce an innovative view synthesis method using NeRF to generate FPV perspectives from UAV footage, enhancing spatial perception for drones. Our novel dataset spans diverse trajectories, from outdoor to indoor environments, in the UAV domain, differing significantly from traditional NeRF scenarios. Through extensive experiments encompassing both interior and exterior building structures, FPV-NeRF demonstrates a superior understanding of the UAV flying space, outperforming state-of-the-art methods in our curated UAV dataset. Explore our project page for further insights: https://fpv-nerf.github.io/.
* Accepted to ECCV 2024
AMD: Automatic Multi-step Distillation of Large-scale Vision Models
Jul 05, 2024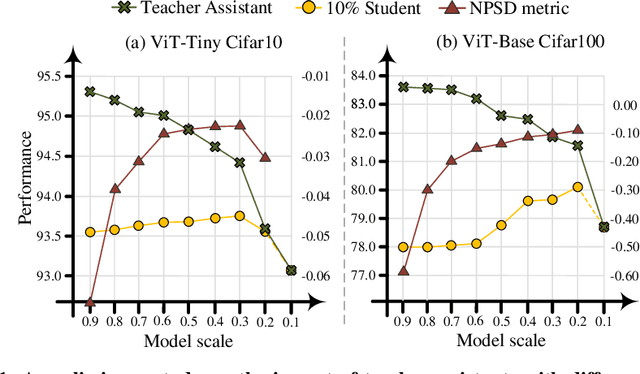

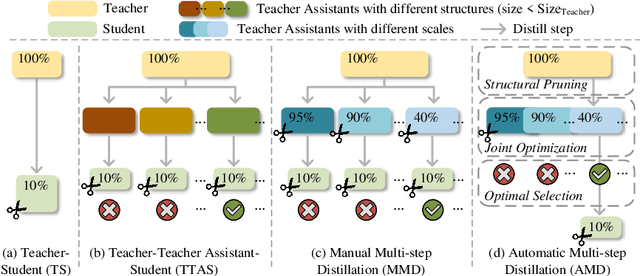

Transformer-based architectures have become the de-facto standard models for diverse vision tasks owing to their superior performance. As the size of the models continues to scale up, model distillation becomes extremely important in various real applications, particularly on devices limited by computational resources. However, prevailing knowledge distillation methods exhibit diminished efficacy when confronted with a large capacity gap between the teacher and the student, e.g, 10x compression rate. In this paper, we present a novel approach named Automatic Multi-step Distillation (AMD) for large-scale vision model compression. In particular, our distillation process unfolds across multiple steps. Initially, the teacher undergoes distillation to form an intermediate teacher-assistant model, which is subsequently distilled further to the student. An efficient and effective optimization framework is introduced to automatically identify the optimal teacher-assistant that leads to the maximal student performance. We conduct extensive experiments on multiple image classification datasets, including CIFAR-10, CIFAR-100, and ImageNet. The findings consistently reveal that our approach outperforms several established baselines, paving a path for future knowledge distillation methods on large-scale vision models.
Prototypical Transformer as Unified Motion Learners
Jun 03, 2024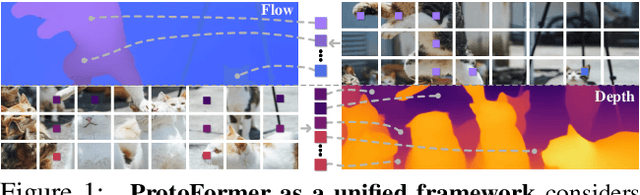
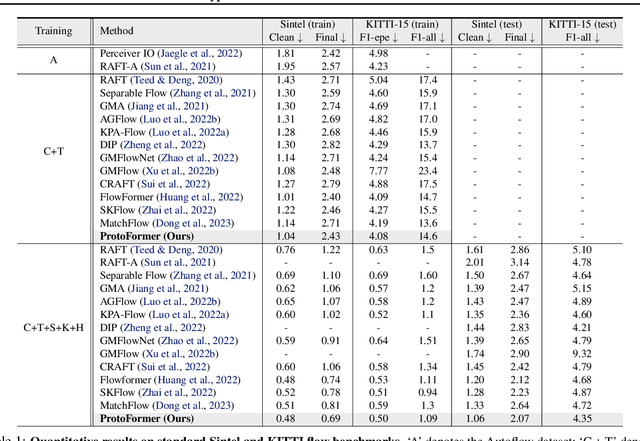
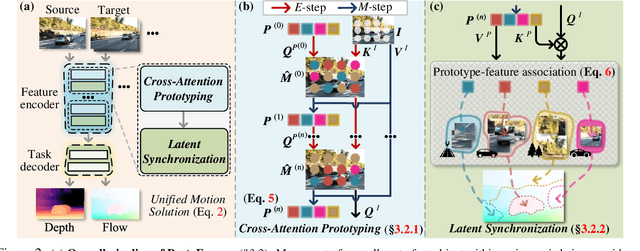
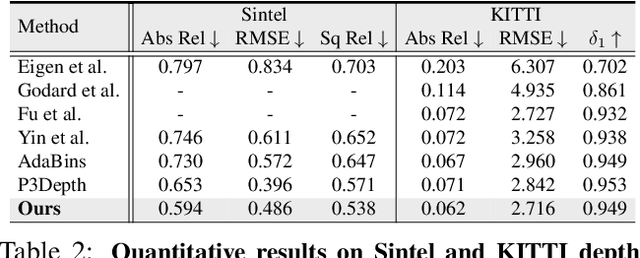
In this work, we introduce the Prototypical Transformer (ProtoFormer), a general and unified framework that approaches various motion tasks from a prototype perspective. ProtoFormer seamlessly integrates prototype learning with Transformer by thoughtfully considering motion dynamics, introducing two innovative designs. First, Cross-Attention Prototyping discovers prototypes based on signature motion patterns, providing transparency in understanding motion scenes. Second, Latent Synchronization guides feature representation learning via prototypes, effectively mitigating the problem of motion uncertainty. Empirical results demonstrate that our approach achieves competitive performance on popular motion tasks such as optical flow and scene depth. Furthermore, it exhibits generality across various downstream tasks, including object tracking and video stabilization.
Improving CNN-base Stock Trading By Considering Data Heterogeneity and Burst
Mar 14, 2023
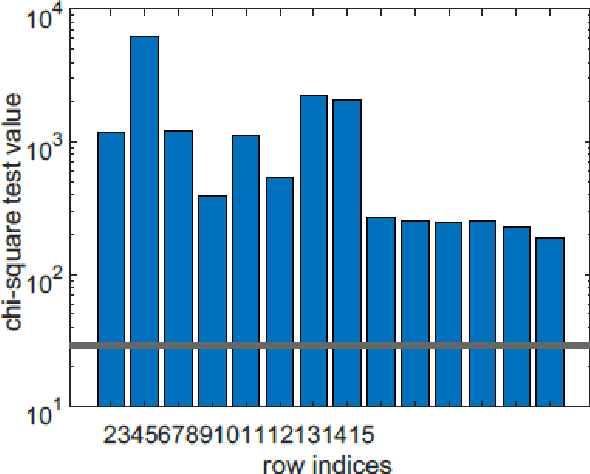
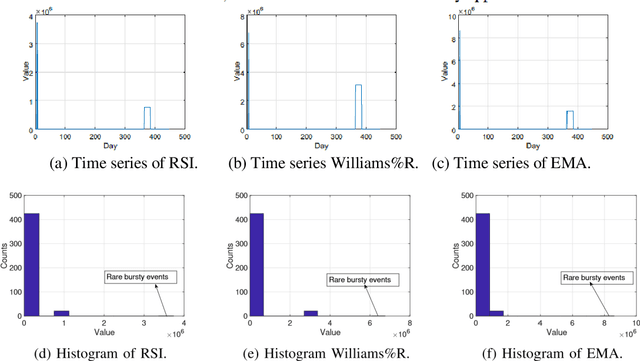

In recent years, there have been quite a few attempts to apply intelligent techniques to financial trading, i.e., constructing automatic and intelligent trading framework based on historical stock price. Due to the unpredictable, uncertainty and volatile nature of financial market, researchers have also resorted to deep learning to construct the intelligent trading framework. In this paper, we propose to use CNN as the core functionality of such framework, because it is able to learn the spatial dependency (i.e., between rows and columns) of the input data. However, different with existing deep learning-based trading frameworks, we develop novel normalization process to prepare the stock data. In particular, we first empirically observe that the stock data is intrinsically heterogeneous and bursty, and then validate the heterogeneity and burst nature of stock data from a statistical perspective. Next, we design the data normalization method in a way such that the data heterogeneity is preserved and bursty events are suppressed. We verify out developed CNN-based trading framework plus our new normalization method on 29 stocks. Experiment results show that our approach can outperform other comparing approaches.
Making Invisible Visible: Data-Driven Seismic Inversion with Physics-Informed Data Augmentation
Jun 23, 2021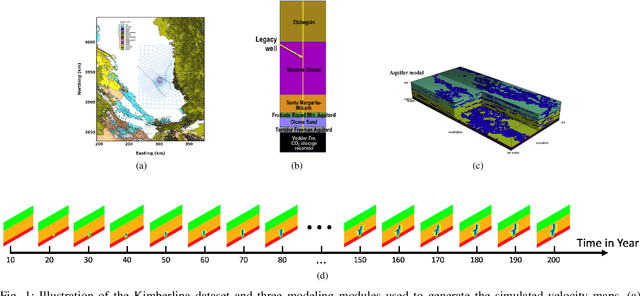



Deep learning and data-driven approaches have shown great potential in scientific domains. The promise of data-driven techniques relies on the availability of a large volume of high-quality training datasets. Due to the high cost of obtaining data through expensive physical experiments, instruments, and simulations, data augmentation techniques for scientific applications have emerged as a new direction for obtaining scientific data recently. However, existing data augmentation techniques originating from computer vision, yield physically unacceptable data samples that are not helpful for the domain problems that we are interested in. In this paper, we develop new physics-informed data augmentation techniques based on convolutional neural networks. Specifically, our generative models leverage different physics knowledge (such as governing equations, observable perception, and physics phenomena) to improve the quality of the synthetic data. To validate the effectiveness of our data augmentation techniques, we apply them to solve a subsurface seismic full-waveform inversion using simulated CO$_2$ leakage data. Our interest is to invert for subsurface velocity models associated with very small CO$_2$ leakage. We validate the performance of our methods using comprehensive numerical tests. Via comparison and analysis, we show that data-driven seismic imaging can be significantly enhanced by using our physics-informed data augmentation techniques. Particularly, the imaging quality has been improved by 15% in test scenarios of general-sized leakage and 17% in small-sized leakage when using an augmented training set obtained with our techniques.