 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProMotion: Prototypes As Motion Learners
Jun 07, 2024

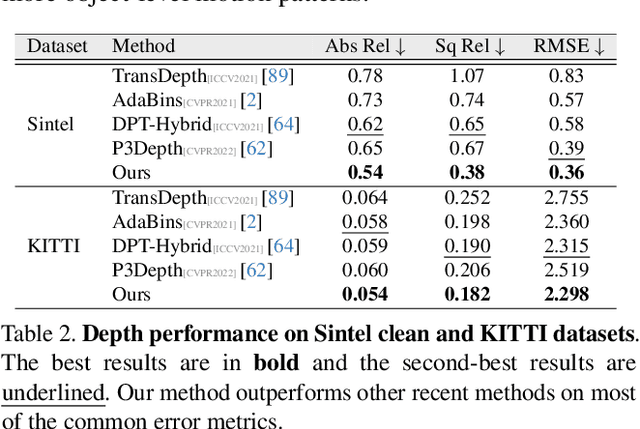

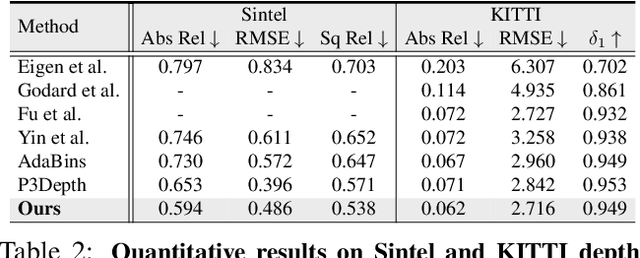
In this work, we introduce ProMotion, a unified prototypical framework engineered to model fundamental motion tasks. ProMotion offers a range of compelling attributes that set it apart from current task-specific paradigms. We adopt a prototypical perspective, establishing a unified paradigm that harmonizes disparate motion learning approaches. This novel paradigm streamlines the architectural design, enabling the simultaneous assimilation of diverse motion information. We capitalize on a dual mechanism involving the feature denoiser and the prototypical learner to decipher the intricacies of motion. This approach effectively circumvents the pitfalls of ambiguity in pixel-wise feature matching, significantly bolstering the robustness of motion representation. We demonstrate a profound degree of transferability across distinct motion patterns. This inherent versatility reverberates robustly across a comprehensive spectrum of both 2D and 3D downstream tasks. Empirical results demonstrate that ProMotion outperforms various well-known specialized architectures, achieving 0.54 and 0.054 Abs Rel error on the Sintel and KITTI depth datasets, 1.04 and 2.01 average endpoint error on the clean and final pass of Sintel flow benchmark, and 4.30 F1-all error on the KITTI flow benchmark. For its efficacy, we hope our work can catalyze a paradigm shift in universal models in computer vision.
Prototypical Transformer as Unified Motion Learners
Jun 03, 2024
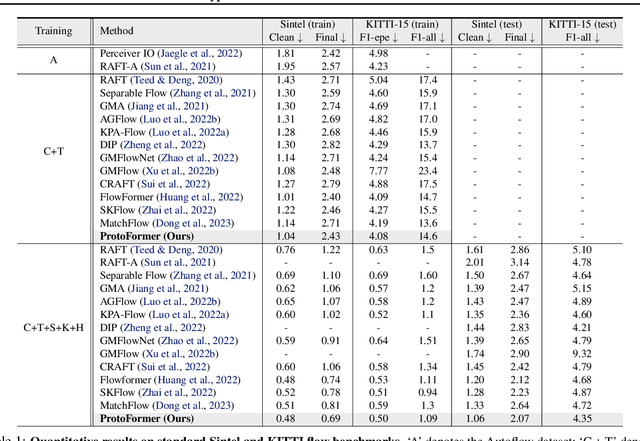
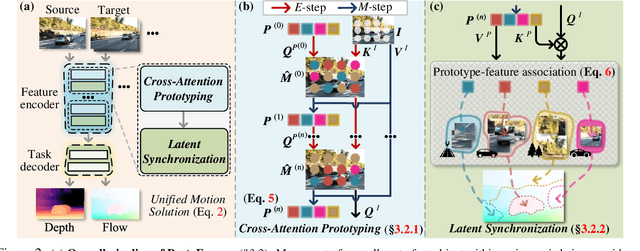
In this work, we introduce the Prototypical Transformer (ProtoFormer), a general and unified framework that approaches various motion tasks from a prototype perspective. ProtoFormer seamlessly integrates prototype learning with Transformer by thoughtfully considering motion dynamics, introducing two innovative designs. First, Cross-Attention Prototyping discovers prototypes based on signature motion patterns, providing transparency in understanding motion scenes. Second, Latent Synchronization guides feature representation learning via prototypes, effectively mitigating the problem of motion uncertainty. Empirical results demonstrate that our approach achieves competitive performance on popular motion tasks such as optical flow and scene depth. Furthermore, it exhibits generality across various downstream tasks, including object tracking and video stabilization.
Force-EvT: A Closer Look at Robotic Gripper Force Measurement with Event-based Vision Transformer
Apr 01, 2024
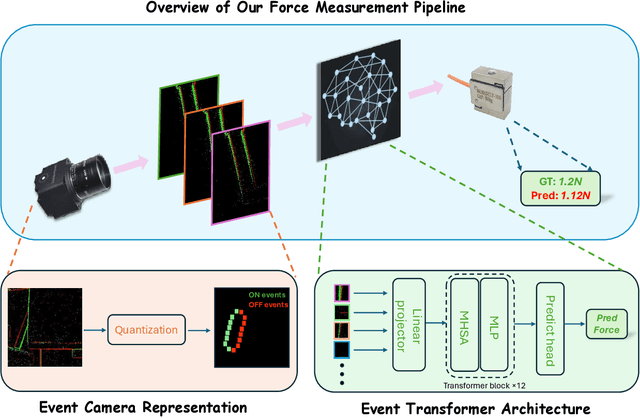
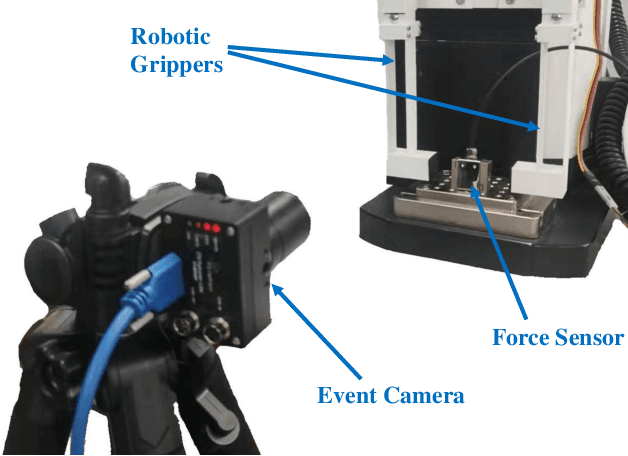

Robotic grippers are receiving increasing attention in various industries as essential components of robots for interacting and manipulating objects. While significant progress has been made in the past, conventional rigid grippers still have limitations in handling irregular objects and can damage fragile objects. We have shown that soft grippers offer deformability to adapt to a variety of object shapes and maximize object protection. At the same time, dynamic vision sensors (e.g., event-based cameras) are capable of capturing small changes in brightness and streaming them asynchronously as events, unlike RGB cameras, which do not perform well in low-light and fast-moving environments. In this paper, a dynamic-vision-based algorithm is proposed to measure the force applied to the gripper. In particular, we first set up a DVXplorer Lite series event camera to capture twenty-five sets of event data. Second, motivated by the impressive performance of the Vision Transformer (ViT) algorithm in dense image prediction tasks, we propose a new approach that demonstrates the potential for real-time force estimation and meets the requirements of real-world scenarios. We extensively evaluate the proposed algorithm on a wide range of scenarios and settings, and show that it consistently outperforms recent approaches.
Diffusion Attack: Leveraging Stable Diffusion for Naturalistic Image Attacking
Mar 21, 2024In Virtual Reality (VR), adversarial attack remains a significant security threat. Most deep learning-based methods for physical and digital adversarial attacks focus on enhancing attack performance by crafting adversarial examples that contain large printable distortions that are easy for human observers to identify. However, attackers rarely impose limitations on the naturalness and comfort of the appearance of the generated attack image, resulting in a noticeable and unnatural attack. To address this challenge, we propose a framework to incorporate style transfer to craft adversarial inputs of natural styles that exhibit minimal detectability and maximum natural appearance, while maintaining superior attack capabilities.
LiDAR-Forest Dataset: LiDAR Point Cloud Simulation Dataset for Forestry Application
Feb 15, 2024


The popularity of LiDAR devices and sensor technology has gradually empowered users from autonomous driving to forest monitoring, and research on 3D LiDAR has made remarkable progress over the years. Unlike 2D images, whose focused area is visible and rich in texture information, understanding the point distribution can help companies and researchers find better ways to develop point-based 3D applications. In this work, we contribute an unreal-based LiDAR simulation tool and a 3D simulation dataset named LiDAR-Forest, which can be used by various studies to evaluate forest reconstruction, tree DBH estimation, and point cloud compression for easy visualization. The simulation is customizable in tree species, LiDAR types and scene generation, with low cost and high efficiency.
DL3DV-10K: A Large-Scale Scene Dataset for Deep Learning-based 3D Vision
Dec 29, 2023



We have witnessed significant progress in deep learning-based 3D vision, ranging from neural radiance field (NeRF) based 3D representation learning to applications in novel view synthesis (NVS). However, existing scene-level datasets for deep learning-based 3D vision, limited to either synthetic environments or a narrow selection of real-world scenes, are quite insufficient. This insufficiency not only hinders a comprehensive benchmark of existing methods but also caps what could be explored in deep learning-based 3D analysis. To address this critical gap, we present DL3DV-10K, a large-scale scene dataset, featuring 51.2 million frames from 10,510 videos captured from 65 types of point-of-interest (POI) locations, covering both bounded and unbounded scenes, with different levels of reflection, transparency, and lighting. We conducted a comprehensive benchmark of recent NVS methods on DL3DV-10K, which revealed valuable insights for future research in NVS. In addition, we have obtained encouraging results in a pilot study to learn generalizable NeRF from DL3DV-10K, which manifests the necessity of a large-scale scene-level dataset to forge a path toward a foundation model for learning 3D representation. Our DL3DV-10K dataset, benchmark results, and models will be publicly accessible at https://dl3dv-10k.github.io/DL3DV-10K/.
TransFlow: Transformer as Flow Learner
Apr 23, 2023Optical flow is an indispensable building block for various important computer vision tasks, including motion estimation, object tracking, and disparity measurement. In this work, we propose TransFlow, a pure transformer architecture for optical flow estimation. Compared to dominant CNN-based methods, TransFlow demonstrates three advantages. First, it provides more accurate correlation and trustworthy matching in flow estimation by utilizing spatial self-attention and cross-attention mechanisms between adjacent frames to effectively capture global dependencies; Second, it recovers more compromised information (e.g., occlusion and motion blur) in flow estimation through long-range temporal association in dynamic scenes; Third, it enables a concise self-learning paradigm and effectively eliminate the complex and laborious multi-stage pre-training procedures. We achieve the state-of-the-art results on the Sintel, KITTI-15, as well as several downstream tasks, including video object detection, interpolation and stabilization. For its efficacy, we hope TransFlow could serve as a flexible baseline for optical flow estimation.