 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartphone-based Circular Plot Sampling for Forest Inventory
May 19, 2026Circular sample plots are a cornerstone of forest inventory, yet accurate measurement of tree diameter at breast height (DBH) and spatial location within such plots remains challenging. Conventional approaches rely either on costly terrestrial LiDAR systems or labor-intensive manual methods involving calipers and compass bearings, limiting their scalability and accessibility in large scale environments. We present a lightweight, smartphone-based pipeline that enables complete plot sampling based tree measurement from a single walkthrough video, requiring no specialized hardware beyond a consumer smartphone mounted on a portable stand. The proposed method integrates pretrained monocular depth estimation and tree instance segmentation with a simultaneous localization and mapping (SLAM) framework to jointly refine camera trajectories and depth across the video sequence. Tree positions and DBH estimates are recovered by fusing SLAM-derived camera poses with segmented depth maps, with absolute real-world scale anchored via a calibrated reference length. The system was evaluated in both managed forest plots and natural forest plot, achieving a mean absolute error of 1.51 cm (MARE 3.98%) and 2.30 cm (MARE 5.69%) respectively, with consistent performance across varying starting directions and positions. Cross-video consistency analysis further demonstrated stable and reproducible tree localization across measurements initiated from different starting positions. The proposed approach achieves accuracy comparable to established field methods while substantially reducing equipment cost and operational complexity, making it accessible to both professional researchers and non-expert forest managers in diverse operational settings.
MIRAGE: A Micro-Interaction Relational Architecture for Grounded Exploration in Multi-Figure Artworks
Apr 26, 2026Appreciating multi-figure paintings requires understanding how characters relate through subtle cues like gaze alignment, gesture, and spatial arrangement. We present MIRAGE, an evidence-centric framework designed to scaffold the exploration of these "micro-interactions" in multi-figure artworks. While such cues are essential for deep narrative appreciation, they are often distributed across complex scenes and difficult for viewers to systematically identify. Existing vision-language models (VLMs) frequently fail to provide reliable assistance, offering ungrounded interpretations that lack traceable visual evidence. MIRAGE addresses this by constructing a structured intermediate representation capturing identities, pose cues, and gaze hypotheses. However, the challenge extends beyond extracting these cues to coordinating them during interpretation. Without an explicit mechanism to organize and reconcile relational evidence, models often collapse multiple interaction hypotheses into a single unstable or weakly grounded narrative, even when low-level signals are available. This representation allows users to verify how high-level interpretations are anchored in low-level visual facts. By separating spatial grounding from narrative generation, MIRAGE enables users to inspect and reason about figure-to-figure relationships through a verifiable evidence layer. We evaluate MIRAGE against painting-only VLM baselines using a blind assessment protocol. Results show that MIRAGE significantly improves identity consistency, reduces relational hallucinations, and increases the coverage of subtle interactions. These findings suggest that structured grounding can serve as a critical interaction control layer, providing the necessary scaffolding for a more reliable, transparent, and human-led understanding of complex visual narratives.
SplatFlow: Self-Supervised Dynamic Gaussian Splatting in Neural Motion Flow Field for Autonomous Driving
Nov 23, 2024



Most existing Dynamic Gaussian Splatting methods for complex dynamic urban scenarios rely on accurate object-level supervision from expensive manual labeling, limiting their scalability in real-world applications. In this paper, we introduce SplatFlow, a Self-Supervised Dynamic Gaussian Splatting within Neural Motion Flow Fields (NMFF) to learn 4D space-time representations without requiring tracked 3D bounding boxes, enabling accurate dynamic scene reconstruction and novel view RGB, depth and flow synthesis. SplatFlow designs a unified framework to seamlessly integrate time-dependent 4D Gaussian representation within NMFF, where NMFF is a set of implicit functions to model temporal motions of both LiDAR points and Gaussians as continuous motion flow fields. Leveraging NMFF, SplatFlow effectively decomposes static background and dynamic objects, representing them with 3D and 4D Gaussian primitives, respectively. NMFF also models the status correspondences of each 4D Gaussian across time, which aggregates temporal features to enhance cross-view consistency of dynamic components. SplatFlow further improves dynamic scene identification by distilling features from 2D foundational models into 4D space-time representation. Comprehensive evaluations conducted on the Waymo Open Dataset and KITTI Dataset validate SplatFlow's state-of-the-art (SOTA) performance for both image reconstruction and novel view synthesis in dynamic urban scenarios.
ProMotion: Prototypes As Motion Learners
Jun 07, 2024

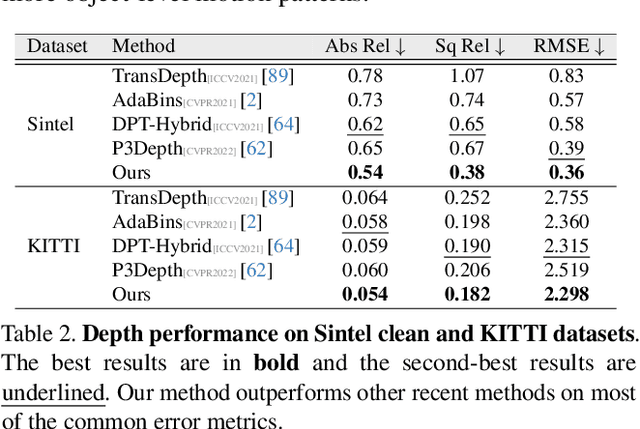

In this work, we introduce ProMotion, a unified prototypical framework engineered to model fundamental motion tasks. ProMotion offers a range of compelling attributes that set it apart from current task-specific paradigms. We adopt a prototypical perspective, establishing a unified paradigm that harmonizes disparate motion learning approaches. This novel paradigm streamlines the architectural design, enabling the simultaneous assimilation of diverse motion information. We capitalize on a dual mechanism involving the feature denoiser and the prototypical learner to decipher the intricacies of motion. This approach effectively circumvents the pitfalls of ambiguity in pixel-wise feature matching, significantly bolstering the robustness of motion representation. We demonstrate a profound degree of transferability across distinct motion patterns. This inherent versatility reverberates robustly across a comprehensive spectrum of both 2D and 3D downstream tasks. Empirical results demonstrate that ProMotion outperforms various well-known specialized architectures, achieving 0.54 and 0.054 Abs Rel error on the Sintel and KITTI depth datasets, 1.04 and 2.01 average endpoint error on the clean and final pass of Sintel flow benchmark, and 4.30 F1-all error on the KITTI flow benchmark. For its efficacy, we hope our work can catalyze a paradigm shift in universal models in computer vision.
Behind the Veil: Enhanced Indoor 3D Scene Reconstruction with Occluded Surfaces Completion
Apr 03, 2024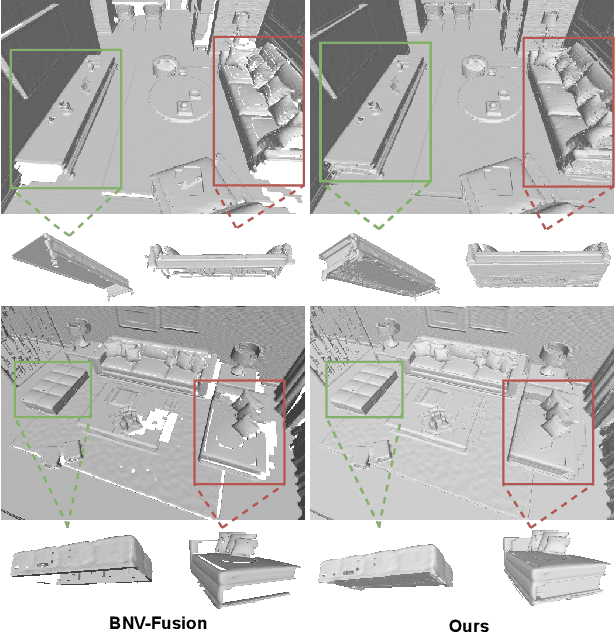
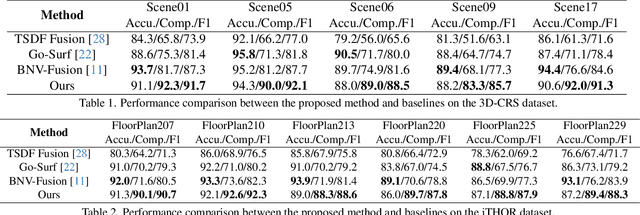
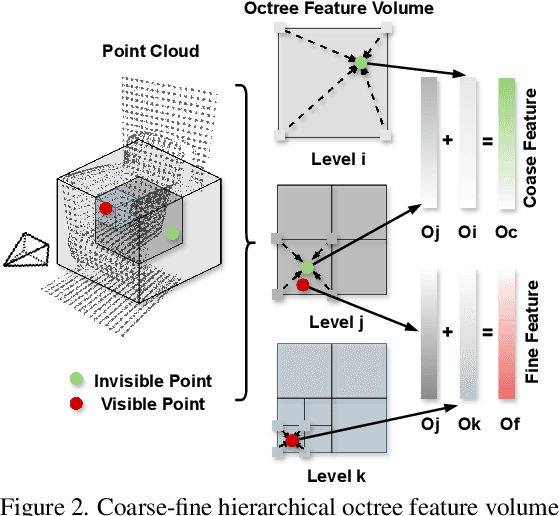
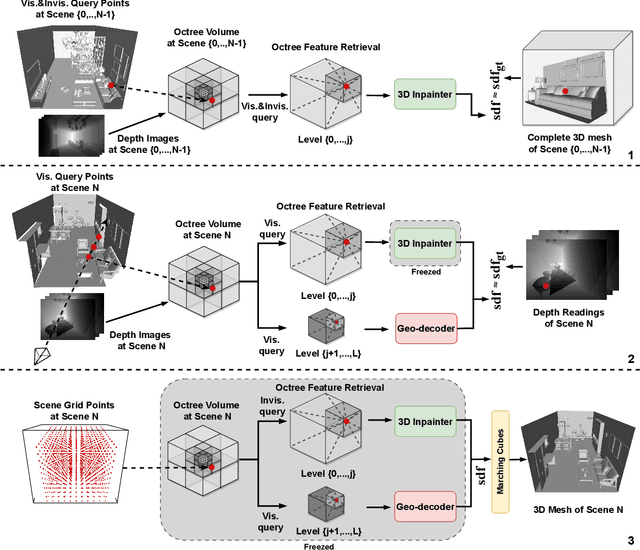
In this paper, we present a novel indoor 3D reconstruction method with occluded surface completion, given a sequence of depth readings. Prior state-of-the-art (SOTA) methods only focus on the reconstruction of the visible areas in a scene, neglecting the invisible areas due to the occlusions, e.g., the contact surface between furniture, occluded wall and floor. Our method tackles the task of completing the occluded scene surfaces, resulting in a complete 3D scene mesh. The core idea of our method is learning 3D geometry prior from various complete scenes to infer the occluded geometry of an unseen scene from solely depth measurements. We design a coarse-fine hierarchical octree representation coupled with a dual-decoder architecture, i.e., Geo-decoder and 3D Inpainter, which jointly reconstructs the complete 3D scene geometry. The Geo-decoder with detailed representation at fine levels is optimized online for each scene to reconstruct visible surfaces. The 3D Inpainter with abstract representation at coarse levels is trained offline using various scenes to complete occluded surfaces. As a result, while the Geo-decoder is specialized for an individual scene, the 3D Inpainter can be generally applied across different scenes. We evaluate the proposed method on the 3D Completed Room Scene (3D-CRS) and iTHOR datasets, significantly outperforming the SOTA methods by a gain of 16.8% and 24.2% in terms of the completeness of 3D reconstruction. 3D-CRS dataset including a complete 3D mesh of each scene is provided at project webpage.
TCLC-GS: Tightly Coupled LiDAR-Camera Gaussian Splatting for Surrounding Autonomous Driving Scenes
Apr 03, 2024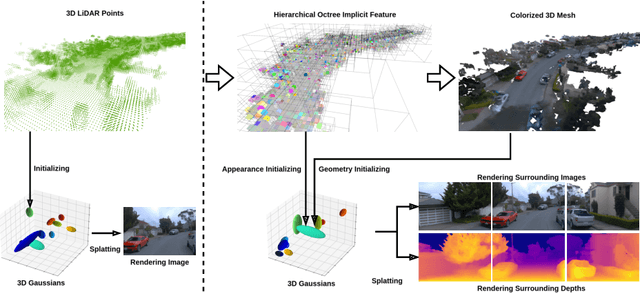
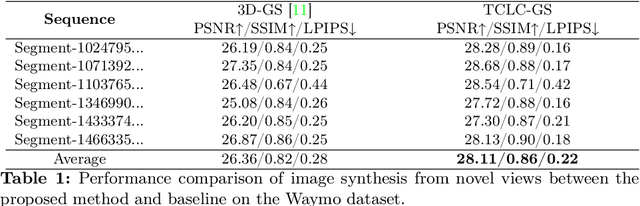
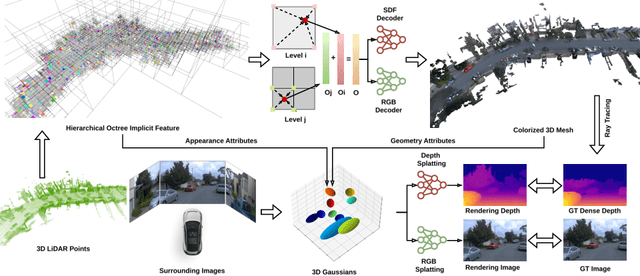
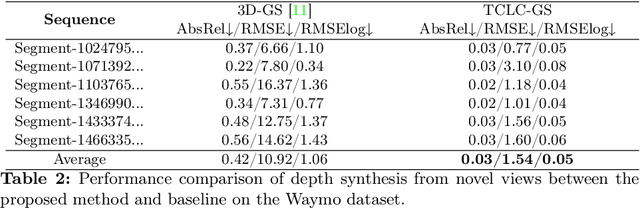
Most 3D Gaussian Splatting (3D-GS) based methods for urban scenes initialize 3D Gaussians directly with 3D LiDAR points, which not only underutilizes LiDAR data capabilities but also overlooks the potential advantages of fusing LiDAR with camera data. In this paper, we design a novel tightly coupled LiDAR-Camera Gaussian Splatting (TCLC-GS) to fully leverage the combined strengths of both LiDAR and camera sensors, enabling rapid, high-quality 3D reconstruction and novel view RGB/depth synthesis. TCLC-GS designs a hybrid explicit (colorized 3D mesh) and implicit (hierarchical octree feature) 3D representation derived from LiDAR-camera data, to enrich the properties of 3D Gaussians for splatting. 3D Gaussian's properties are not only initialized in alignment with the 3D mesh which provides more completed 3D shape and color information, but are also endowed with broader contextual information through retrieved octree implicit features. During the Gaussian Splatting optimization process, the 3D mesh offers dense depth information as supervision, which enhances the training process by learning of a robust geometry. Comprehensive evaluations conducted on the Waymo Open Dataset and nuScenes Dataset validate our method's state-of-the-art (SOTA) performance. Utilizing a single NVIDIA RTX 3090 Ti, our method demonstrates fast training and achieves real-time RGB and depth rendering at 90 FPS in resolution of 1920x1280 (Waymo), and 120 FPS in resolution of 1600x900 (nuScenes) in urban scenarios.
TransFlow: Transformer as Flow Learner
Apr 23, 2023



Optical flow is an indispensable building block for various important computer vision tasks, including motion estimation, object tracking, and disparity measurement. In this work, we propose TransFlow, a pure transformer architecture for optical flow estimation. Compared to dominant CNN-based methods, TransFlow demonstrates three advantages. First, it provides more accurate correlation and trustworthy matching in flow estimation by utilizing spatial self-attention and cross-attention mechanisms between adjacent frames to effectively capture global dependencies; Second, it recovers more compromised information (e.g., occlusion and motion blur) in flow estimation through long-range temporal association in dynamic scenes; Third, it enables a concise self-learning paradigm and effectively eliminate the complex and laborious multi-stage pre-training procedures. We achieve the state-of-the-art results on the Sintel, KITTI-15, as well as several downstream tasks, including video object detection, interpolation and stabilization. For its efficacy, we hope TransFlow could serve as a flexible baseline for optical flow estimation.