 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePISCES: Annotation-free Text-to-Video Post-Training via Optimal Transport-Aligned Rewards
Feb 02, 2026Text-to-video (T2V) generation aims to synthesize videos with high visual quality and temporal consistency that are semantically aligned with input text. Reward-based post-training has emerged as a promising direction to improve the quality and semantic alignment of generated videos. However, recent methods either rely on large-scale human preference annotations or operate on misaligned embeddings from pre-trained vision-language models, leading to limited scalability or suboptimal supervision. We present $\texttt{PISCES}$, an annotation-free post-training algorithm that addresses these limitations via a novel Dual Optimal Transport (OT)-aligned Rewards module. To align reward signals with human judgment, $\texttt{PISCES}$ uses OT to bridge text and video embeddings at both distributional and discrete token levels, enabling reward supervision to fulfill two objectives: (i) a Distributional OT-aligned Quality Reward that captures overall visual quality and temporal coherence; and (ii) a Discrete Token-level OT-aligned Semantic Reward that enforces semantic, spatio-temporal correspondence between text and video tokens. To our knowledge, $\texttt{PISCES}$ is the first to improve annotation-free reward supervision in generative post-training through the lens of OT. Experiments on both short- and long-video generation show that $\texttt{PISCES}$ outperforms both annotation-based and annotation-free methods on VBench across Quality and Semantic scores, with human preference studies further validating its effectiveness. We show that the Dual OT-aligned Rewards module is compatible with multiple optimization paradigms, including direct backpropagation and reinforcement learning fine-tuning.
DeCafNet: Delegate and Conquer for Efficient Temporal Grounding in Long Videos
May 22, 2025Long Video Temporal Grounding (LVTG) aims at identifying specific moments within lengthy videos based on user-provided text queries for effective content retrieval. The approach taken by existing methods of dividing video into clips and processing each clip via a full-scale expert encoder is challenging to scale due to prohibitive computational costs of processing a large number of clips in long videos. To address this issue, we introduce DeCafNet, an approach employing ``delegate-and-conquer'' strategy to achieve computation efficiency without sacrificing grounding performance. DeCafNet introduces a sidekick encoder that performs dense feature extraction over all video clips in a resource-efficient manner, while generating a saliency map to identify the most relevant clips for full processing by the expert encoder. To effectively leverage features from sidekick and expert encoders that exist at different temporal resolutions, we introduce DeCaf-Grounder, which unifies and refines them via query-aware temporal aggregation and multi-scale temporal refinement for accurate grounding. Experiments on two LTVG benchmark datasets demonstrate that DeCafNet reduces computation by up to 47\% while still outperforming existing methods, establishing a new state-of-the-art for LTVG in terms of both efficiency and performance. Our code is available at https://github.com/ZijiaLewisLu/CVPR2025-DeCafNet.
SplatFlow: Self-Supervised Dynamic Gaussian Splatting in Neural Motion Flow Field for Autonomous Driving
Nov 23, 2024



Most existing Dynamic Gaussian Splatting methods for complex dynamic urban scenarios rely on accurate object-level supervision from expensive manual labeling, limiting their scalability in real-world applications. In this paper, we introduce SplatFlow, a Self-Supervised Dynamic Gaussian Splatting within Neural Motion Flow Fields (NMFF) to learn 4D space-time representations without requiring tracked 3D bounding boxes, enabling accurate dynamic scene reconstruction and novel view RGB, depth and flow synthesis. SplatFlow designs a unified framework to seamlessly integrate time-dependent 4D Gaussian representation within NMFF, where NMFF is a set of implicit functions to model temporal motions of both LiDAR points and Gaussians as continuous motion flow fields. Leveraging NMFF, SplatFlow effectively decomposes static background and dynamic objects, representing them with 3D and 4D Gaussian primitives, respectively. NMFF also models the status correspondences of each 4D Gaussian across time, which aggregates temporal features to enhance cross-view consistency of dynamic components. SplatFlow further improves dynamic scene identification by distilling features from 2D foundational models into 4D space-time representation. Comprehensive evaluations conducted on the Waymo Open Dataset and KITTI Dataset validate SplatFlow's state-of-the-art (SOTA) performance for both image reconstruction and novel view synthesis in dynamic urban scenarios.
AdaOcc: Adaptive-Resolution Occupancy Prediction
Aug 24, 2024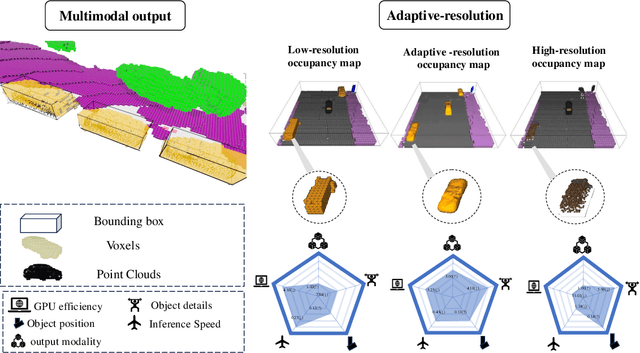
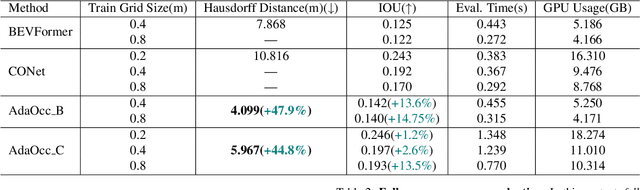
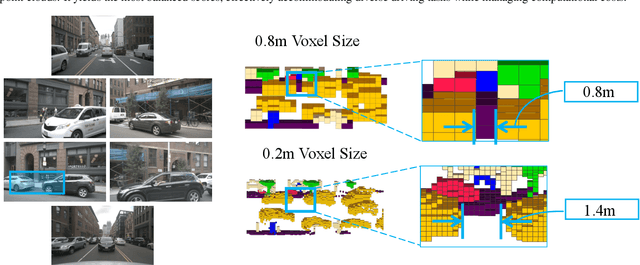
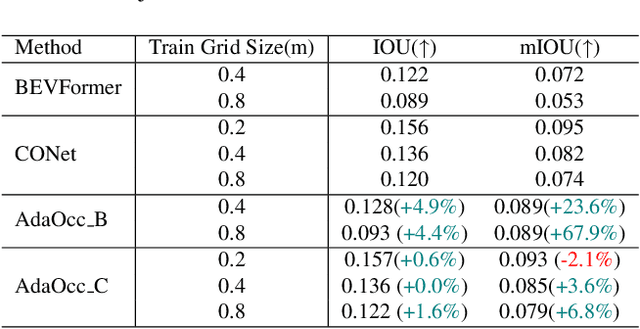
Autonomous driving in complex urban scenarios requires 3D perception to be both comprehensive and precise. Traditional 3D perception methods focus on object detection, resulting in sparse representations that lack environmental detail. Recent approaches estimate 3D occupancy around vehicles for a more comprehensive scene representation. However, dense 3D occupancy prediction increases computational demands, challenging the balance between efficiency and resolution. High-resolution occupancy grids offer accuracy but demand substantial computational resources, while low-resolution grids are efficient but lack detail. To address this dilemma, we introduce AdaOcc, a novel adaptive-resolution, multi-modal prediction approach. Our method integrates object-centric 3D reconstruction and holistic occupancy prediction within a single framework, performing highly detailed and precise 3D reconstruction only in regions of interest (ROIs). These high-detailed 3D surfaces are represented in point clouds, thus their precision is not constrained by the predefined grid resolution of the occupancy map. We conducted comprehensive experiments on the nuScenes dataset, demonstrating significant improvements over existing methods. In close-range scenarios, we surpass previous baselines by over 13% in IOU, and over 40% in Hausdorff distance. In summary, AdaOcc offers a more versatile and effective framework for delivering accurate 3D semantic occupancy prediction across diverse driving scenarios.
TCLC-GS: Tightly Coupled LiDAR-Camera Gaussian Splatting for Surrounding Autonomous Driving Scenes
Apr 03, 2024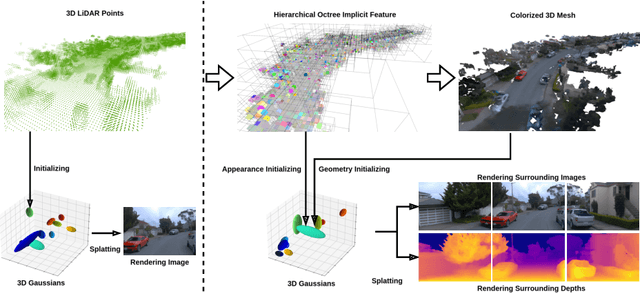
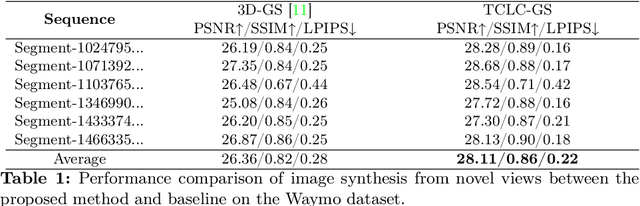
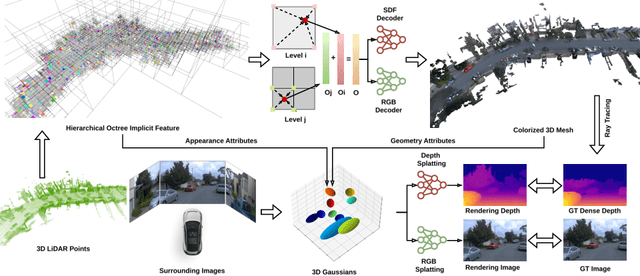
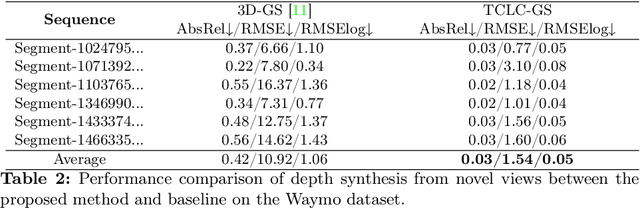
Most 3D Gaussian Splatting (3D-GS) based methods for urban scenes initialize 3D Gaussians directly with 3D LiDAR points, which not only underutilizes LiDAR data capabilities but also overlooks the potential advantages of fusing LiDAR with camera data. In this paper, we design a novel tightly coupled LiDAR-Camera Gaussian Splatting (TCLC-GS) to fully leverage the combined strengths of both LiDAR and camera sensors, enabling rapid, high-quality 3D reconstruction and novel view RGB/depth synthesis. TCLC-GS designs a hybrid explicit (colorized 3D mesh) and implicit (hierarchical octree feature) 3D representation derived from LiDAR-camera data, to enrich the properties of 3D Gaussians for splatting. 3D Gaussian's properties are not only initialized in alignment with the 3D mesh which provides more completed 3D shape and color information, but are also endowed with broader contextual information through retrieved octree implicit features. During the Gaussian Splatting optimization process, the 3D mesh offers dense depth information as supervision, which enhances the training process by learning of a robust geometry. Comprehensive evaluations conducted on the Waymo Open Dataset and nuScenes Dataset validate our method's state-of-the-art (SOTA) performance. Utilizing a single NVIDIA RTX 3090 Ti, our method demonstrates fast training and achieves real-time RGB and depth rendering at 90 FPS in resolution of 1920x1280 (Waymo), and 120 FPS in resolution of 1600x900 (nuScenes) in urban scenarios.
Behind the Veil: Enhanced Indoor 3D Scene Reconstruction with Occluded Surfaces Completion
Apr 03, 2024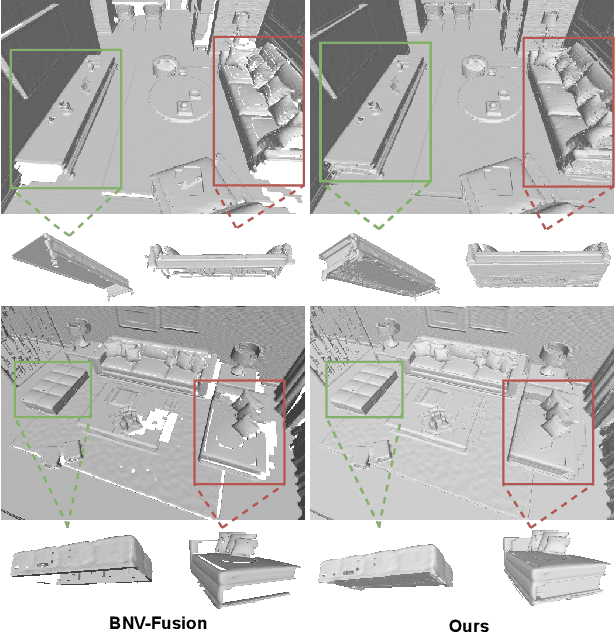
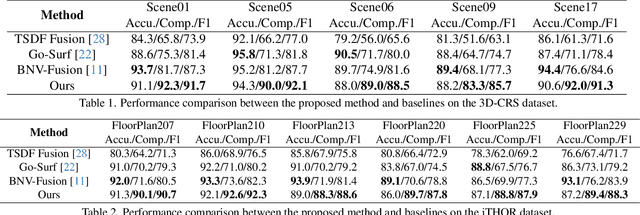
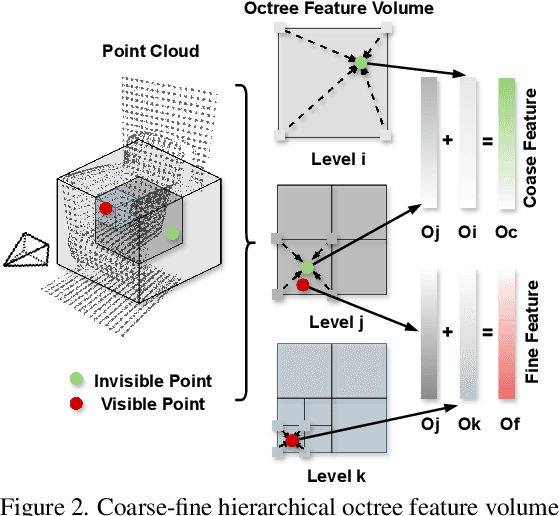
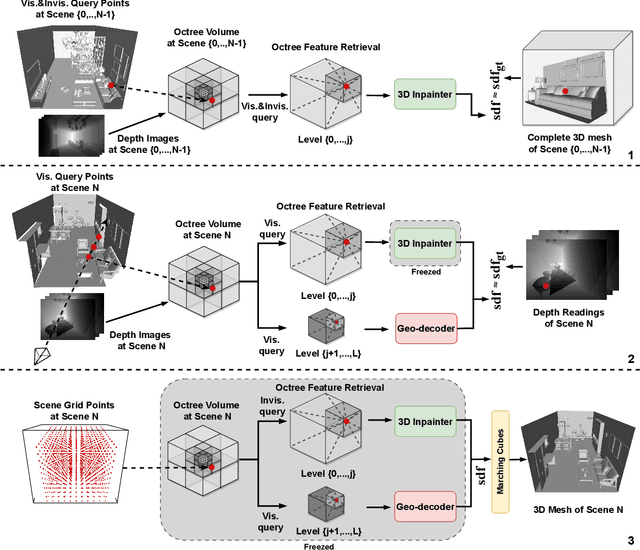
In this paper, we present a novel indoor 3D reconstruction method with occluded surface completion, given a sequence of depth readings. Prior state-of-the-art (SOTA) methods only focus on the reconstruction of the visible areas in a scene, neglecting the invisible areas due to the occlusions, e.g., the contact surface between furniture, occluded wall and floor. Our method tackles the task of completing the occluded scene surfaces, resulting in a complete 3D scene mesh. The core idea of our method is learning 3D geometry prior from various complete scenes to infer the occluded geometry of an unseen scene from solely depth measurements. We design a coarse-fine hierarchical octree representation coupled with a dual-decoder architecture, i.e., Geo-decoder and 3D Inpainter, which jointly reconstructs the complete 3D scene geometry. The Geo-decoder with detailed representation at fine levels is optimized online for each scene to reconstruct visible surfaces. The 3D Inpainter with abstract representation at coarse levels is trained offline using various scenes to complete occluded surfaces. As a result, while the Geo-decoder is specialized for an individual scene, the 3D Inpainter can be generally applied across different scenes. We evaluate the proposed method on the 3D Completed Room Scene (3D-CRS) and iTHOR datasets, significantly outperforming the SOTA methods by a gain of 16.8% and 24.2% in terms of the completeness of 3D reconstruction. 3D-CRS dataset including a complete 3D mesh of each scene is provided at project webpage.
UPNeRF: A Unified Framework for Monocular 3D Object Reconstruction and Pose Estimation
Mar 23, 2024
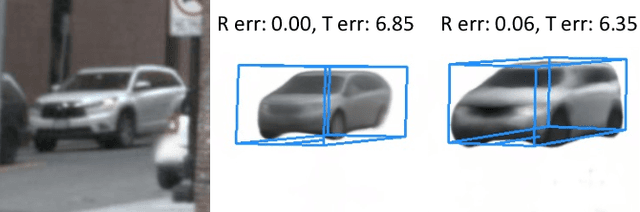
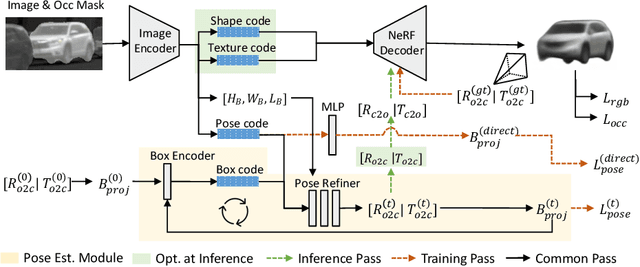
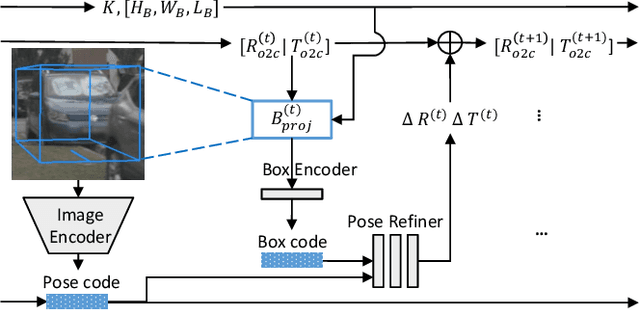
Monocular 3D reconstruction for categorical objects heavily relies on accurately perceiving each object's pose. While gradient-based optimization within a NeRF framework updates initially given poses, this paper highlights that such a scheme fails when the initial pose even moderately deviates from the true pose. Consequently, existing methods often depend on a third-party 3D object to provide an initial object pose, leading to increased complexity and generalization issues. To address these challenges, we present UPNeRF, a Unified framework integrating Pose estimation and NeRF-based reconstruction, bringing us closer to real-time monocular 3D object reconstruction. UPNeRF decouples the object's dimension estimation and pose refinement to resolve the scale-depth ambiguity, and introduces an effective projected-box representation that generalizes well cross different domains. While using a dedicated pose estimator that smoothly integrates into an object-centric NeRF, UPNeRF is free from external 3D detectors. UPNeRF achieves state-of-the-art results in both reconstruction and pose estimation tasks on the nuScenes dataset. Furthermore, UPNeRF exhibits exceptional Cross-dataset generalization on the KITTI and Waymo datasets, surpassing prior methods with up to 50% reduction in rotation and translation error.
3D Copy-Paste: Physically Plausible Object Insertion for Monocular 3D Detection
Dec 08, 2023

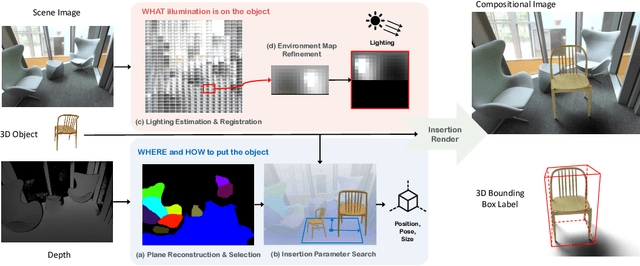

A major challenge in monocular 3D object detection is the limited diversity and quantity of objects in real datasets. While augmenting real scenes with virtual objects holds promise to improve both the diversity and quantity of the objects, it remains elusive due to the lack of an effective 3D object insertion method in complex real captured scenes. In this work, we study augmenting complex real indoor scenes with virtual objects for monocular 3D object detection. The main challenge is to automatically identify plausible physical properties for virtual assets (e.g., locations, appearances, sizes, etc.) in cluttered real scenes. To address this challenge, we propose a physically plausible indoor 3D object insertion approach to automatically copy virtual objects and paste them into real scenes. The resulting objects in scenes have 3D bounding boxes with plausible physical locations and appearances. In particular, our method first identifies physically feasible locations and poses for the inserted objects to prevent collisions with the existing room layout. Subsequently, it estimates spatially-varying illumination for the insertion location, enabling the immersive blending of the virtual objects into the original scene with plausible appearances and cast shadows. We show that our augmentation method significantly improves existing monocular 3D object models and achieves state-of-the-art performance. For the first time, we demonstrate that a physically plausible 3D object insertion, serving as a generative data augmentation technique, can lead to significant improvements for discriminative downstream tasks such as monocular 3D object detection. Project website: https://gyhandy.github.io/3D-Copy-Paste/
3D ToF LiDAR in Mobile Robotics: A Review
Feb 22, 2022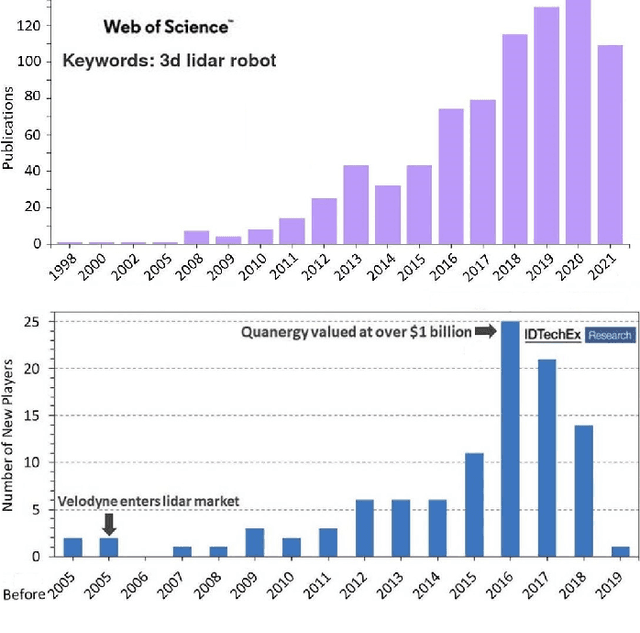
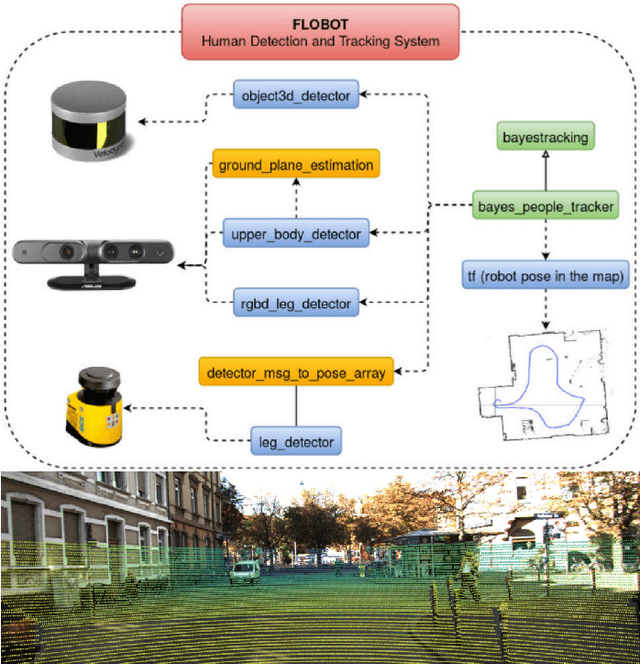

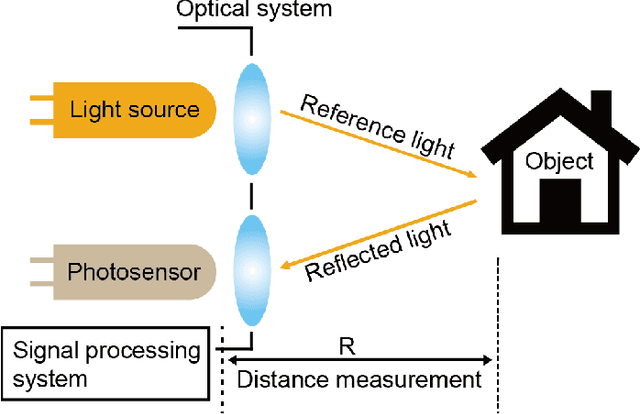
In the past ten years, the use of 3D Time-of-Flight (ToF) LiDARs in mobile robotics has grown rapidly. Based on our accumulation of relevant research, this article systematically reviews and analyzes the use 3D ToF LiDARs in research and industrial applications. The former includes object detection, robot localization, long-term autonomy, LiDAR data processing under adverse weather conditions, and sensor fusion. The latter encompasses service robots, assisted and autonomous driving, and recent applications performed in response to public health crises. We hope that our efforts can effectively provide readers with relevant references and promote the deployment of existing mature technologies in real-world systems.
NDT-Transformer: Large-Scale 3D Point Cloud Localisation using the Normal Distribution Transform Representation
Mar 23, 2021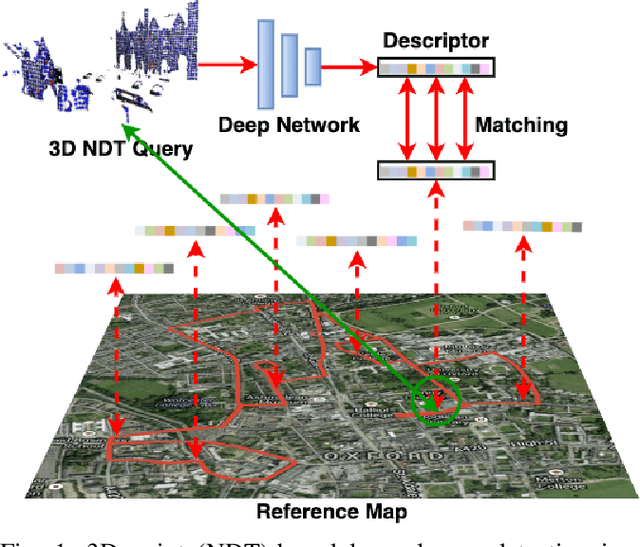

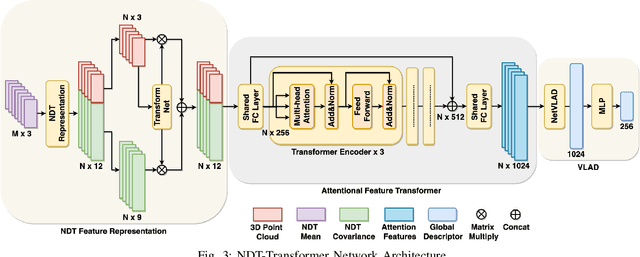
3D point cloud-based place recognition is highly demanded by autonomous driving in GPS-challenged environments and serves as an essential component (i.e. loop-closure detection) in lidar-based SLAM systems. This paper proposes a novel approach, named NDT-Transformer, for realtime and large-scale place recognition using 3D point clouds. Specifically, a 3D Normal Distribution Transform (NDT) representation is employed to condense the raw, dense 3D point cloud as probabilistic distributions (NDT cells) to provide the geometrical shape description. Then a novel NDT-Transformer network learns a global descriptor from a set of 3D NDT cell representations. Benefiting from the NDT representation and NDT-Transformer network, the learned global descriptors are enriched with both geometrical and contextual information. Finally, descriptor retrieval is achieved using a query-database for place recognition. Compared to the state-of-the-art methods, the proposed approach achieves an improvement of 7.52% on average top 1 recall and 2.73% on average top 1% recall on the Oxford Robotcar benchmark.