 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePantheon360: Taming Digital Twin Generation via 3D-Aware 360° Video Diffusion
May 25, 2026Generating complete digital twins from videos requires precise camera control, global scene coverage, and strict spatial-temporal consistency constraints that remain challenging for perspective video generators due to their limited field of view (FoV). Their narrow FoV forces long or multi-view trajectories, amplifying cross-view inconsistency and temporal drift. We argue that 360° video generation offers a natural solution: panoramic coverage simplifies trajectory design and provides a strong global context for maintaining coherence. We introduce Pantheon360: Taming Digital Twin Generation via 3D-Aware 360° Video Diffusion, a controllable 360° video generation framework that synthesizes high-fidelity videos from sparse 360° inputs. The key idea is an explicit 3D Cache, reconstructed from the input, which serves as a geometric scaffold for any user-defined camera path. This allows the diffusion model to focus on photorealistic texture refinement while the 3D Cache enforces global geometric consistency. Experiments show that Pantheon360 achieves superior visual quality and unmatched geometric coherence, enabling reliable and flexible 360° scene generation for downstream simulation and digital-twin applications.
UniDAC: Universal Metric Depth Estimation for Any Camera
Mar 28, 2026Monocular metric depth estimation (MMDE) is a core challenge in computer vision, playing a pivotal role in real-world applications that demand accurate spatial understanding. Although prior works have shown promising zero-shot performance in MMDE, they often struggle with generalization across diverse camera types, such as fisheye and $360^\circ$ cameras. Recent advances have addressed this through unified camera representations or canonical representation spaces, but they require either including large-FoV camera data during training or separately trained models for different domains. We propose UniDAC, an MMDE framework that presents universal robustness in all domains and generalizes across diverse cameras using a single model. We achieve this by decoupling metric depth estimation into relative depth prediction and spatially varying scale estimation, enabling robust performance across different domains. We propose a lightweight Depth-Guided Scale Estimation module that upsamples a coarse scale map to high resolution using the relative depth map as guidance to account for local scale variations. Furthermore, we introduce RoPE-$φ$, a distortion-aware positional embedding that respects the spatial warping in Equi-Rectangular Projections (ERP) via latitude-aware weighting. UniDAC achieves state of the art (SoTA) in cross-camera generalization by consistently outperforming prior methods across all datasets.
3DGEER: Exact and Efficient Volumetric Rendering with 3D Gaussians
May 29, 20253D Gaussian Splatting (3DGS) marks a significant milestone in balancing the quality and efficiency of differentiable rendering. However, its high efficiency stems from an approximation of projecting 3D Gaussians onto the image plane as 2D Gaussians, which inherently limits rendering quality--particularly under large Field-of-View (FoV) camera inputs. While several recent works have extended 3DGS to mitigate these approximation errors, none have successfully achieved both exactness and high efficiency simultaneously. In this work, we introduce 3DGEER, an Exact and Efficient Volumetric Gaussian Rendering method. Starting from first principles, we derive a closed-form expression for the density integral along a ray traversing a 3D Gaussian distribution. This formulation enables precise forward rendering with arbitrary camera models and supports gradient-based optimization of 3D Gaussian parameters. To ensure both exactness and real-time performance, we propose an efficient method for computing a tight Particle Bounding Frustum (PBF) for each 3D Gaussian, enabling accurate and efficient ray-Gaussian association. We also introduce a novel Bipolar Equiangular Projection (BEAP) representation to accelerate ray association under generic camera models. BEAP further provides a more uniform ray sampling strategy to apply supervision, which empirically improves reconstruction quality. Experiments on multiple pinhole and fisheye datasets show that our method consistently outperforms prior methods, establishing a new state-of-the-art in real-time neural rendering.
Online Language Splatting
Mar 12, 2025To enable AI agents to interact seamlessly with both humans and 3D environments, they must not only perceive the 3D world accurately but also align human language with 3D spatial representations. While prior work has made significant progress by integrating language features into geometrically detailed 3D scene representations using 3D Gaussian Splatting (GS), these approaches rely on computationally intensive offline preprocessing of language features for each input image, limiting adaptability to new environments. In this work, we introduce Online Language Splatting, the first framework to achieve online, near real-time, open-vocabulary language mapping within a 3DGS-SLAM system without requiring pre-generated language features. The key challenge lies in efficiently fusing high-dimensional language features into 3D representations while balancing the computation speed, memory usage, rendering quality and open-vocabulary capability. To this end, we innovatively design: (1) a high-resolution CLIP embedding module capable of generating detailed language feature maps in 18ms per frame, (2) a two-stage online auto-encoder that compresses 768-dimensional CLIP features to 15 dimensions while preserving open-vocabulary capabilities, and (3) a color-language disentangled optimization approach to improve rendering quality. Experimental results show that our online method not only surpasses the state-of-the-art offline methods in accuracy but also achieves more than 40x efficiency boost, demonstrating the potential for dynamic and interactive AI applications.
SMART: Advancing Scalable Map Priors for Driving Topology Reasoning
Feb 06, 2025Topology reasoning is crucial for autonomous driving as it enables comprehensive understanding of connectivity and relationships between lanes and traffic elements. While recent approaches have shown success in perceiving driving topology using vehicle-mounted sensors, their scalability is hindered by the reliance on training data captured by consistent sensor configurations. We identify that the key factor in scalable lane perception and topology reasoning is the elimination of this sensor-dependent feature. To address this, we propose SMART, a scalable solution that leverages easily available standard-definition (SD) and satellite maps to learn a map prior model, supervised by large-scale geo-referenced high-definition (HD) maps independent of sensor settings. Attributed to scaled training, SMART alone achieves superior offline lane topology understanding using only SD and satellite inputs. Extensive experiments further demonstrate that SMART can be seamlessly integrated into any online topology reasoning methods, yielding significant improvements of up to 28% on the OpenLane-V2 benchmark.
MapGS: Generalizable Pretraining and Data Augmentation for Online Mapping via Novel View Synthesis
Jan 11, 2025Online mapping reduces the reliance of autonomous vehicles on high-definition (HD) maps, significantly enhancing scalability. However, recent advancements often overlook cross-sensor configuration generalization, leading to performance degradation when models are deployed on vehicles with different camera intrinsics and extrinsics. With the rapid evolution of novel view synthesis methods, we investigate the extent to which these techniques can be leveraged to address the sensor configuration generalization challenge. We propose a novel framework leveraging Gaussian splatting to reconstruct scenes and render camera images in target sensor configurations. The target config sensor data, along with labels mapped to the target config, are used to train online mapping models. Our proposed framework on the nuScenes and Argoverse 2 datasets demonstrates a performance improvement of 18% through effective dataset augmentation, achieves faster convergence and efficient training, and exceeds state-of-the-art performance when using only 25% of the original training data. This enables data reuse and reduces the need for laborious data labeling. Project page at https://henryzhangzhy.github.io/mapgs.
Depth Any Camera: Zero-Shot Metric Depth Estimation from Any Camera
Jan 05, 2025



While recent depth estimation methods exhibit strong zero-shot generalization, achieving accurate metric depth across diverse camera types-particularly those with large fields of view (FoV) such as fisheye and 360-degree cameras-remains a significant challenge. This paper presents Depth Any Camera (DAC), a powerful zero-shot metric depth estimation framework that extends a perspective-trained model to effectively handle cameras with varying FoVs. The framework is designed to ensure that all existing 3D data can be leveraged, regardless of the specific camera types used in new applications. Remarkably, DAC is trained exclusively on perspective images but generalizes seamlessly to fisheye and 360-degree cameras without the need for specialized training data. DAC employs Equi-Rectangular Projection (ERP) as a unified image representation, enabling consistent processing of images with diverse FoVs. Its key components include a pitch-aware Image-to-ERP conversion for efficient online augmentation in ERP space, a FoV alignment operation to support effective training across a wide range of FoVs, and multi-resolution data augmentation to address resolution disparities between training and testing. DAC achieves state-of-the-art zero-shot metric depth estimation, improving delta-1 ($\delta_1$) accuracy by up to 50% on multiple fisheye and 360-degree datasets compared to prior metric depth foundation models, demonstrating robust generalization across camera types.
AdaOcc: Adaptive-Resolution Occupancy Prediction
Aug 24, 2024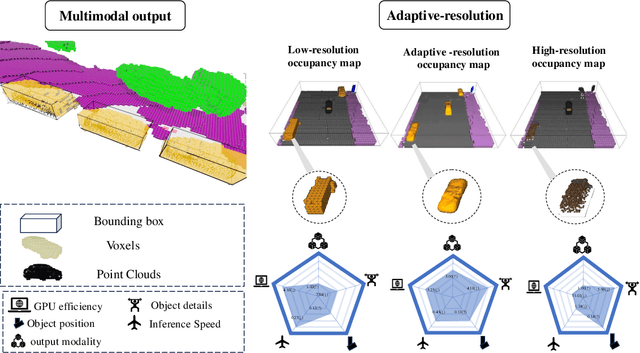
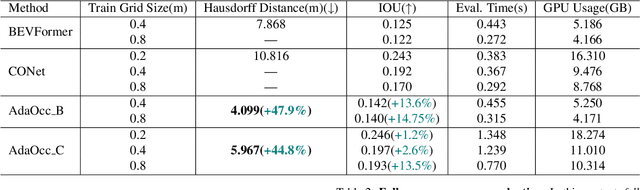
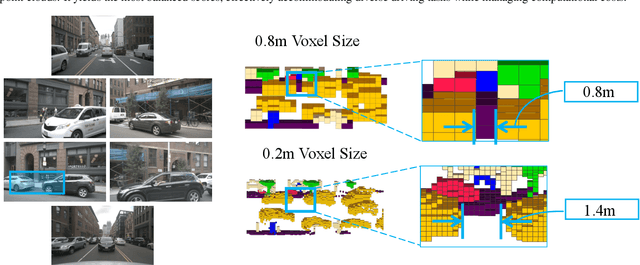
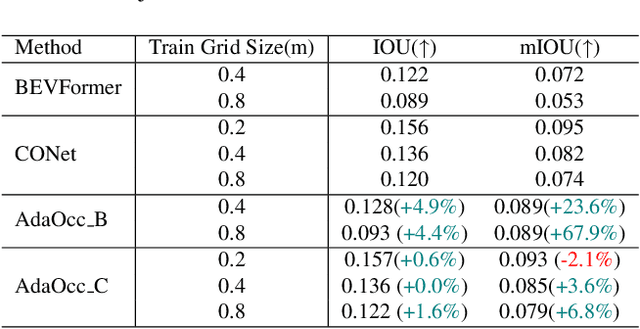
Autonomous driving in complex urban scenarios requires 3D perception to be both comprehensive and precise. Traditional 3D perception methods focus on object detection, resulting in sparse representations that lack environmental detail. Recent approaches estimate 3D occupancy around vehicles for a more comprehensive scene representation. However, dense 3D occupancy prediction increases computational demands, challenging the balance between efficiency and resolution. High-resolution occupancy grids offer accuracy but demand substantial computational resources, while low-resolution grids are efficient but lack detail. To address this dilemma, we introduce AdaOcc, a novel adaptive-resolution, multi-modal prediction approach. Our method integrates object-centric 3D reconstruction and holistic occupancy prediction within a single framework, performing highly detailed and precise 3D reconstruction only in regions of interest (ROIs). These high-detailed 3D surfaces are represented in point clouds, thus their precision is not constrained by the predefined grid resolution of the occupancy map. We conducted comprehensive experiments on the nuScenes dataset, demonstrating significant improvements over existing methods. In close-range scenarios, we surpass previous baselines by over 13% in IOU, and over 40% in Hausdorff distance. In summary, AdaOcc offers a more versatile and effective framework for delivering accurate 3D semantic occupancy prediction across diverse driving scenarios.
Enhancing Online Road Network Perception and Reasoning with Standard Definition Maps
Aug 01, 2024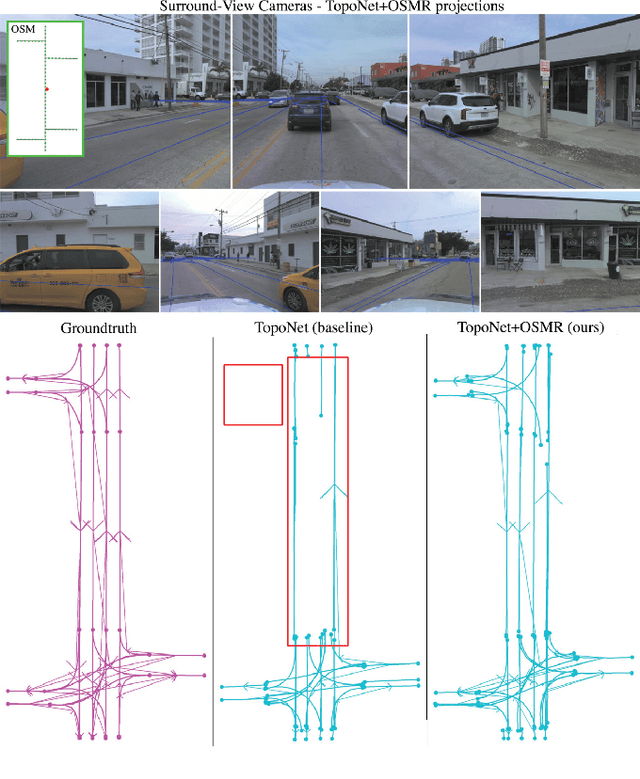
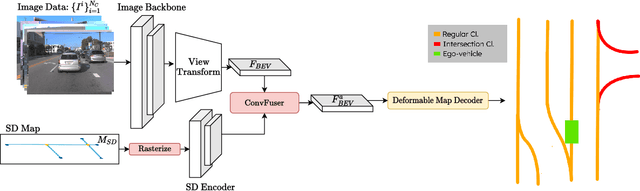
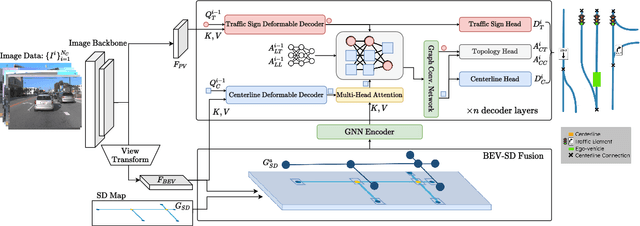
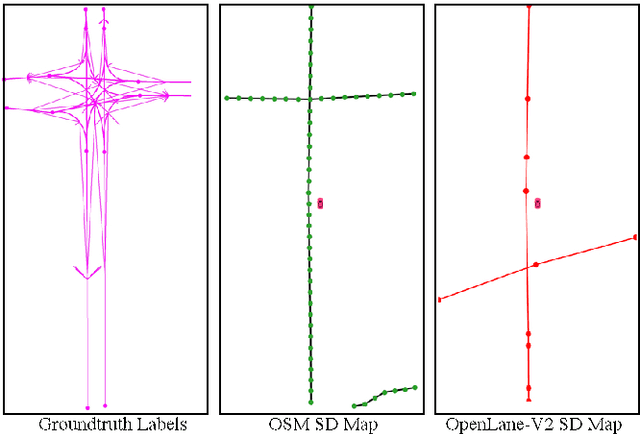
Autonomous driving for urban and highway driving applications often requires High Definition (HD) maps to generate a navigation plan. Nevertheless, various challenges arise when generating and maintaining HD maps at scale. While recent online mapping methods have started to emerge, their performance especially for longer ranges is limited by heavy occlusion in dynamic environments. With these considerations in mind, our work focuses on leveraging lightweight and scalable priors-Standard Definition (SD) maps-in the development of online vectorized HD map representations. We first examine the integration of prototypical rasterized SD map representations into various online mapping architectures. Furthermore, to identify lightweight strategies, we extend the OpenLane-V2 dataset with OpenStreetMaps and evaluate the benefits of graphical SD map representations. A key finding from designing SD map integration components is that SD map encoders are model agnostic and can be quickly adapted to new architectures that utilize bird's eye view (BEV) encoders. Our results show that making use of SD maps as priors for the online mapping task can significantly speed up convergence and boost the performance of the online centerline perception task by 30% (mAP). Furthermore, we show that the introduction of the SD maps leads to a reduction of the number of parameters in the perception and reasoning task by leveraging SD map graphs while improving the overall performance. Project Page: https://henryzhangzhy.github.io/sdhdmap/.
Multiscale Representation Enhanced Temporal Flow Fusion Model for Long-Term Workload Forecasting
Jul 29, 2024



Accurate workload forecasting is critical for efficient resource management in cloud computing systems, enabling effective scheduling and autoscaling. Despite recent advances with transformer-based forecasting models, challenges remain due to the non-stationary, nonlinear characteristics of workload time series and the long-term dependencies. In particular, inconsistent performance between long-term history and near-term forecasts hinders long-range predictions. This paper proposes a novel framework leveraging self-supervised multiscale representation learning to capture both long-term and near-term workload patterns. The long-term history is encoded through multiscale representations while the near-term observations are modeled via temporal flow fusion. These representations of different scales are fused using an attention mechanism and characterized with normalizing flows to handle non-Gaussian/non-linear distributions of time series. Extensive experiments on 9 benchmarks demonstrate superiority over existing methods.