 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoScape: Geometry-Consistent Long-Horizon Scene Generation
Oct 23, 2025This paper proposes AutoScape, a long-horizon driving scene generation framework. At its core is a novel RGB-D diffusion model that iteratively generates sparse, geometrically consistent keyframes, serving as reliable anchors for the scene's appearance and geometry. To maintain long-range geometric consistency, the model 1) jointly handles image and depth in a shared latent space, 2) explicitly conditions on the existing scene geometry (i.e., rendered point clouds) from previously generated keyframes, and 3) steers the sampling process with a warp-consistent guidance. Given high-quality RGB-D keyframes, a video diffusion model then interpolates between them to produce dense and coherent video frames. AutoScape generates realistic and geometrically consistent driving videos of over 20 seconds, improving the long-horizon FID and FVD scores over the prior state-of-the-art by 48.6\% and 43.0\%, respectively.
Depth Any Camera: Zero-Shot Metric Depth Estimation from Any Camera
Jan 05, 2025



While recent depth estimation methods exhibit strong zero-shot generalization, achieving accurate metric depth across diverse camera types-particularly those with large fields of view (FoV) such as fisheye and 360-degree cameras-remains a significant challenge. This paper presents Depth Any Camera (DAC), a powerful zero-shot metric depth estimation framework that extends a perspective-trained model to effectively handle cameras with varying FoVs. The framework is designed to ensure that all existing 3D data can be leveraged, regardless of the specific camera types used in new applications. Remarkably, DAC is trained exclusively on perspective images but generalizes seamlessly to fisheye and 360-degree cameras without the need for specialized training data. DAC employs Equi-Rectangular Projection (ERP) as a unified image representation, enabling consistent processing of images with diverse FoVs. Its key components include a pitch-aware Image-to-ERP conversion for efficient online augmentation in ERP space, a FoV alignment operation to support effective training across a wide range of FoVs, and multi-resolution data augmentation to address resolution disparities between training and testing. DAC achieves state-of-the-art zero-shot metric depth estimation, improving delta-1 ($\delta_1$) accuracy by up to 50% on multiple fisheye and 360-degree datasets compared to prior metric depth foundation models, demonstrating robust generalization across camera types.
SplatSim: Zero-Shot Sim2Real Transfer of RGB Manipulation Policies Using Gaussian Splatting
Sep 16, 2024



Sim2Real transfer, particularly for manipulation policies relying on RGB images, remains a critical challenge in robotics due to the significant domain shift between synthetic and real-world visual data. In this paper, we propose SplatSim, a novel framework that leverages Gaussian Splatting as the primary rendering primitive to reduce the Sim2Real gap for RGB-based manipulation policies. By replacing traditional mesh representations with Gaussian Splats in simulators, SplatSim produces highly photorealistic synthetic data while maintaining the scalability and cost-efficiency of simulation. We demonstrate the effectiveness of our framework by training manipulation policies within SplatSim}and deploying them in the real world in a zero-shot manner, achieving an average success rate of 86.25%, compared to 97.5% for policies trained on real-world data.
AIDE: An Automatic Data Engine for Object Detection in Autonomous Driving
Mar 26, 2024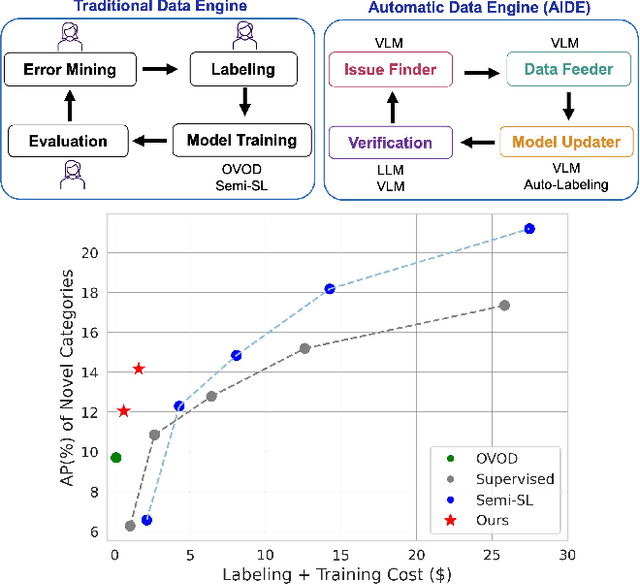
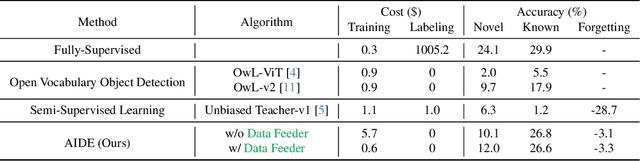
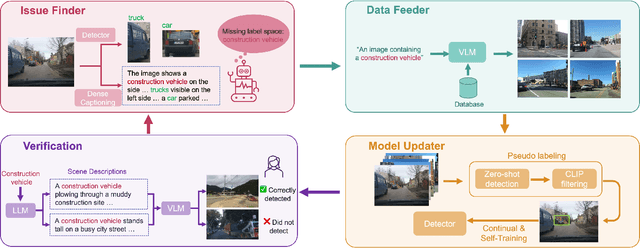
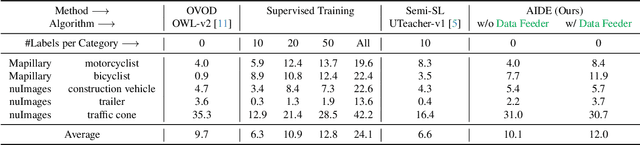
Autonomous vehicle (AV) systems rely on robust perception models as a cornerstone of safety assurance. However, objects encountered on the road exhibit a long-tailed distribution, with rare or unseen categories posing challenges to a deployed perception model. This necessitates an expensive process of continuously curating and annotating data with significant human effort. We propose to leverage recent advances in vision-language and large language models to design an Automatic Data Engine (AIDE) that automatically identifies issues, efficiently curates data, improves the model through auto-labeling, and verifies the model through generation of diverse scenarios. This process operates iteratively, allowing for continuous self-improvement of the model. We further establish a benchmark for open-world detection on AV datasets to comprehensively evaluate various learning paradigms, demonstrating our method's superior performance at a reduced cost.
MM-TTA: Multi-Modal Test-Time Adaptation for 3D Semantic Segmentation
Apr 27, 2022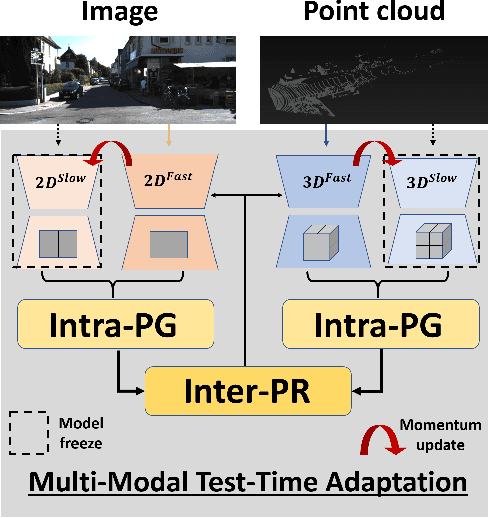
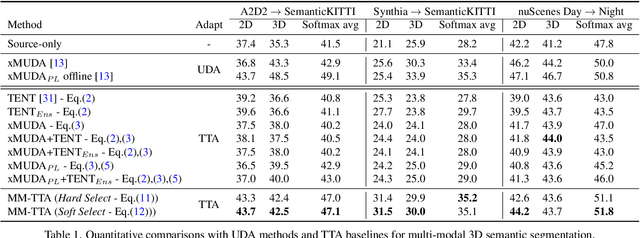
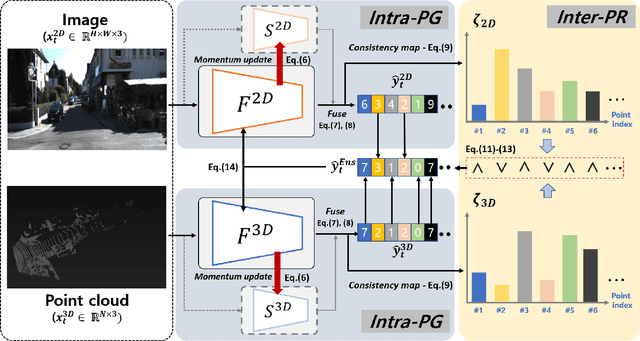
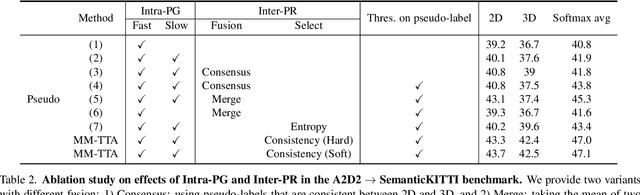
Test-time adaptation approaches have recently emerged as a practical solution for handling domain shift without access to the source domain data. In this paper, we propose and explore a new multi-modal extension of test-time adaptation for 3D semantic segmentation. We find that directly applying existing methods usually results in performance instability at test time because multi-modal input is not considered jointly. To design a framework that can take full advantage of multi-modality, where each modality provides regularized self-supervisory signals to other modalities, we propose two complementary modules within and across the modalities. First, Intra-modal Pseudolabel Generation (Intra-PG) is introduced to obtain reliable pseudo labels within each modality by aggregating information from two models that are both pre-trained on source data but updated with target data at different paces. Second, Inter-modal Pseudo-label Refinement (Inter-PR) adaptively selects more reliable pseudo labels from different modalities based on a proposed consistency scheme. Experiments demonstrate that our regularized pseudo labels produce stable self-learning signals in numerous multi-modal test-time adaptation scenarios for 3D semantic segmentation. Visit our project website at https://www.nec-labs.com/~mas/MM-TTA.
Learning Semantic Segmentation from Multiple Datasets with Label Shifts
Feb 28, 2022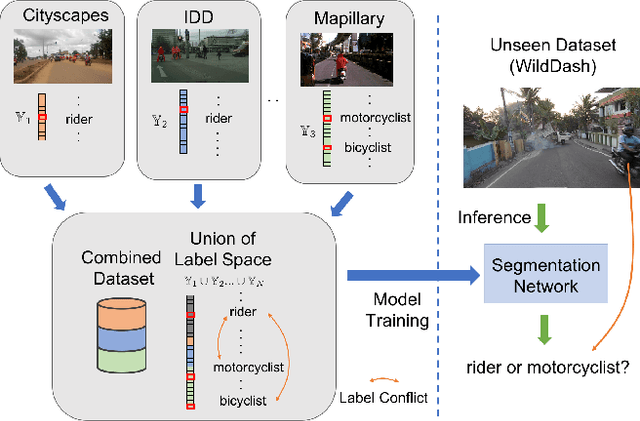
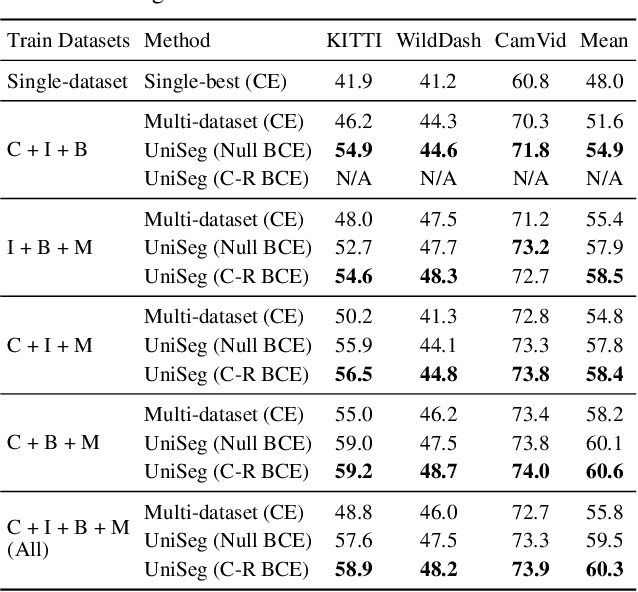
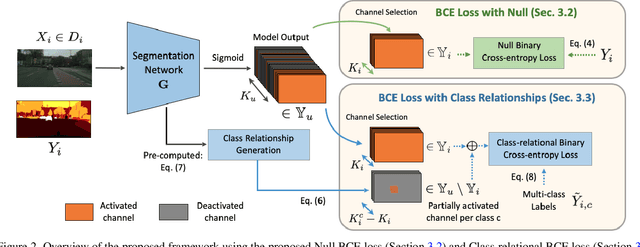
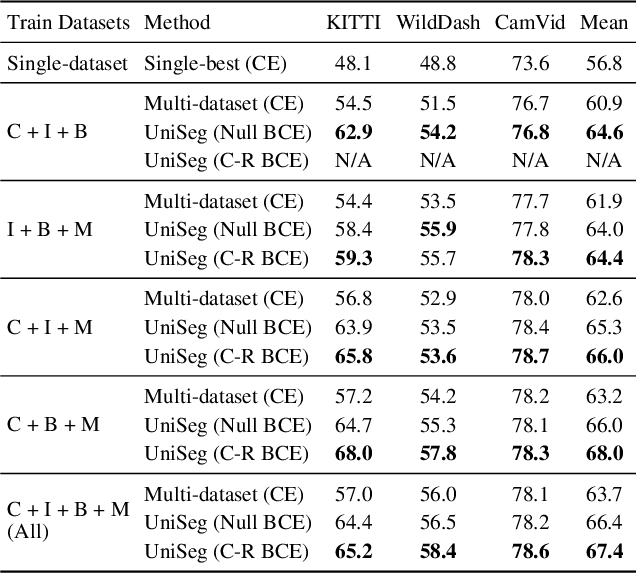
With increasing applications of semantic segmentation, numerous datasets have been proposed in the past few years. Yet labeling remains expensive, thus, it is desirable to jointly train models across aggregations of datasets to enhance data volume and diversity. However, label spaces differ across datasets and may even be in conflict with one another. This paper proposes UniSeg, an effective approach to automatically train models across multiple datasets with differing label spaces, without any manual relabeling efforts. Specifically, we propose two losses that account for conflicting and co-occurring labels to achieve better generalization performance in unseen domains. First, a gradient conflict in training due to mismatched label spaces is identified and a class-independent binary cross-entropy loss is proposed to alleviate such label conflicts. Second, a loss function that considers class-relationships across datasets is proposed for a better multi-dataset training scheme. Extensive quantitative and qualitative analyses on road-scene datasets show that UniSeg improves over multi-dataset baselines, especially on unseen datasets, e.g., achieving more than 8% gain in IoU on KITTI averaged over all the settings.