 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-VLM: Kinematic Instruction Tuning for Spatio-Temporal Reasoning in Vision-Language Models
Mar 26, 2025



Spatio-temporal reasoning is essential in understanding real-world environments in various fields, eg, autonomous driving and sports analytics. Recent advances have improved the spatial reasoning ability of Vision-Language Models (VLMs) by introducing large-scale data, but these models still struggle to analyze kinematic elements like traveled distance and speed of moving objects. To bridge this gap, we construct a spatio-temporal reasoning dataset and benchmark involving kinematic instruction tuning, referred to as STKit and STKit-Bench. They consist of real-world videos with 3D annotations, detailing object motion dynamics: traveled distance, speed, movement direction, inter-object distance comparisons, and relative movement direction. To further scale such data construction to videos without 3D labels, we propose an automatic pipeline to generate pseudo-labels using 4D reconstruction in real-world scale. With our kinematic instruction tuning data for spatio-temporal reasoning, we present ST-VLM, a VLM enhanced for spatio-temporal reasoning, which exhibits outstanding performance on STKit-Bench. Furthermore, we show that ST-VLM generalizes robustly across diverse domains and tasks, outperforming baselines on other spatio-temporal benchmarks (eg, ActivityNet, TVQA+). Finally, by integrating learned spatio-temporal reasoning with existing abilities, ST-VLM enables complex multi-step reasoning. Project page: https://ikodoh.github.io/ST-VLM.
Efficient Transformer Encoders for Mask2Former-style models
Apr 23, 2024



Vision transformer based models bring significant improvements for image segmentation tasks. Although these architectures offer powerful capabilities irrespective of specific segmentation tasks, their use of computational resources can be taxing on deployed devices. One way to overcome this challenge is by adapting the computation level to the specific needs of the input image rather than the current one-size-fits-all approach. To this end, we introduce ECO-M2F or EffiCient TransfOrmer Encoders for Mask2Former-style models. Noting that the encoder module of M2F-style models incur high resource-intensive computations, ECO-M2F provides a strategy to self-select the number of hidden layers in the encoder, conditioned on the input image. To enable this self-selection ability for providing a balance between performance and computational efficiency, we present a three step recipe. The first step is to train the parent architecture to enable early exiting from the encoder. The second step is to create an derived dataset of the ideal number of encoder layers required for each training example. The third step is to use the aforementioned derived dataset to train a gating network that predicts the number of encoder layers to be used, conditioned on the input image. Additionally, to change the computational-accuracy tradeoff, only steps two and three need to be repeated which significantly reduces retraining time. Experiments on the public datasets show that the proposed approach reduces expected encoder computational cost while maintaining performance, adapts to various user compute resources, is flexible in architecture configurations, and can be extended beyond the segmentation task to object detection.
Progressive Token Length Scaling in Transformer Encoders for Efficient Universal Segmentation
Apr 23, 2024



A powerful architecture for universal segmentation relies on transformers that encode multi-scale image features and decode object queries into mask predictions. With efficiency being a high priority for scaling such models, we observed that the state-of-the-art method Mask2Former uses ~50% of its compute only on the transformer encoder. This is due to the retention of a full-length token-level representation of all backbone feature scales at each encoder layer. With this observation, we propose a strategy termed PROgressive Token Length SCALing for Efficient transformer encoders (PRO-SCALE) that can be plugged-in to the Mask2Former-style segmentation architectures to significantly reduce the computational cost. The underlying principle of PRO-SCALE is: progressively scale the length of the tokens with the layers of the encoder. This allows PRO-SCALE to reduce computations by a large margin with minimal sacrifice in performance (~52% GFLOPs reduction with no drop in performance on COCO dataset). We validate our framework on multiple public benchmarks.
Generating Enhanced Negatives for Training Language-Based Object Detectors
Dec 29, 2023The recent progress in language-based open-vocabulary object detection can be largely attributed to finding better ways of leveraging large-scale data with free-form text annotations. Training such models with a discriminative objective function has proven successful, but requires good positive and negative samples. However, the free-form nature and the open vocabulary of object descriptions make the space of negatives extremely large. Prior works randomly sample negatives or use rule-based techniques to build them. In contrast, we propose to leverage the vast knowledge built into modern generative models to automatically build negatives that are more relevant to the original data. Specifically, we use large-language-models to generate negative text descriptions, and text-to-image diffusion models to also generate corresponding negative images. Our experimental analysis confirms the relevance of the generated negative data, and its use in language-based detectors improves performance on two complex benchmarks.
Efficient Controllable Multi-Task Architectures
Aug 22, 2023
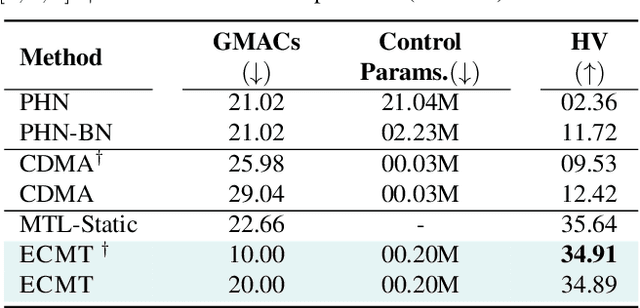
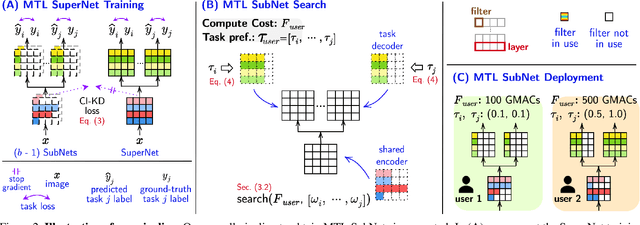
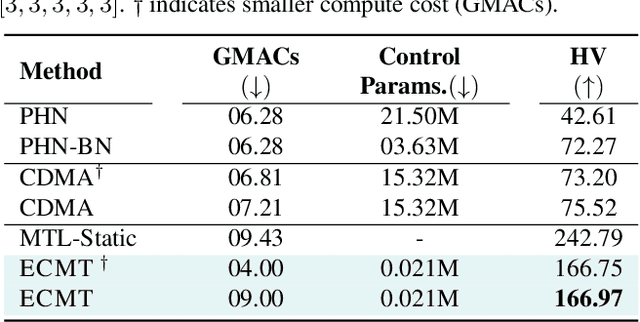
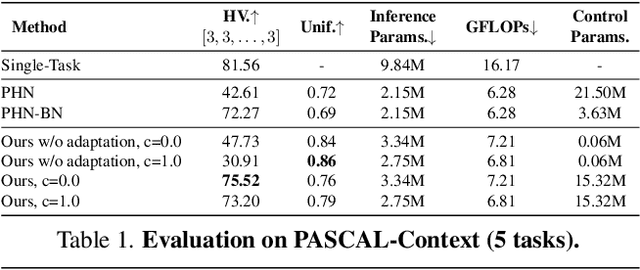
We aim to train a multi-task model such that users can adjust the desired compute budget and relative importance of task performances after deployment, without retraining. This enables optimizing performance for dynamically varying user needs, without heavy computational overhead to train and save models for various scenarios. To this end, we propose a multi-task model consisting of a shared encoder and task-specific decoders where both encoder and decoder channel widths are slimmable. Our key idea is to control the task importance by varying the capacities of task-specific decoders, while controlling the total computational cost by jointly adjusting the encoder capacity. This improves overall accuracy by allowing a stronger encoder for a given budget, increases control over computational cost, and delivers high-quality slimmed sub-architectures based on user's constraints. Our training strategy involves a novel 'Configuration-Invariant Knowledge Distillation' loss that enforces backbone representations to be invariant under different runtime width configurations to enhance accuracy. Further, we present a simple but effective search algorithm that translates user constraints to runtime width configurations of both the shared encoder and task decoders, for sampling the sub-architectures. The key rule for the search algorithm is to provide a larger computational budget to the higher preferred task decoder, while searching a shared encoder configuration that enhances the overall MTL performance. Various experiments on three multi-task benchmarks (PASCALContext, NYUDv2, and CIFAR100-MTL) with diverse backbone architectures demonstrate the advantage of our approach. For example, our method shows a higher controllability by ~33.5% in the NYUD-v2 dataset over prior methods, while incurring much less compute cost.
Improving Pseudo Labels for Open-Vocabulary Object Detection
Aug 11, 2023Recent studies show promising performance in open-vocabulary object detection (OVD) using pseudo labels (PLs) from pretrained vision and language models (VLMs). However, PLs generated by VLMs are extremely noisy due to the gap between the pretraining objective of VLMs and OVD, which blocks further advances on PLs. In this paper, we aim to reduce the noise in PLs and propose a method called online Self-training And a Split-and-fusion head for OVD (SAS-Det). First, the self-training finetunes VLMs to generate high quality PLs while prevents forgetting the knowledge learned in the pretraining. Second, a split-and-fusion (SAF) head is designed to remove the noise in localization of PLs, which is usually ignored in existing methods. It also fuses complementary knowledge learned from both precise ground truth and noisy pseudo labels to boost the performance. Extensive experiments demonstrate SAS-Det is both efficient and effective. Our pseudo labeling is 3 times faster than prior methods. SAS-Det outperforms prior state-of-the-art models of the same scale by a clear margin and achieves 37.4 AP$_{50}$ and 27.3 AP$_r$ on novel categories of the COCO and LVIS benchmarks, respectively.
OmniLabel: A Challenging Benchmark for Language-Based Object Detection
Apr 22, 2023



Language-based object detection is a promising direction towards building a natural interface to describe objects in images that goes far beyond plain category names. While recent methods show great progress in that direction, proper evaluation is lacking. With OmniLabel, we propose a novel task definition, dataset, and evaluation metric. The task subsumes standard- and open-vocabulary detection as well as referring expressions. With more than 28K unique object descriptions on over 25K images, OmniLabel provides a challenging benchmark with diverse and complex object descriptions in a naturally open-vocabulary setting. Moreover, a key differentiation to existing benchmarks is that our object descriptions can refer to one, multiple or even no object, hence, providing negative examples in free-form text. The proposed evaluation handles the large label space and judges performance via a modified average precision metric, which we validate by evaluating strong language-based baselines. OmniLabel indeed provides a challenging test bed for future research on language-based detection.
Confidence and Dispersity Speak: Characterising Prediction Matrix for Unsupervised Accuracy Estimation
Feb 02, 2023



This work aims to assess how well a model performs under distribution shifts without using labels. While recent methods study prediction confidence, this work reports prediction dispersity is another informative cue. Confidence reflects whether the individual prediction is certain; dispersity indicates how the overall predictions are distributed across all categories. Our key insight is that a well-performing model should give predictions with high confidence and high dispersity. That is, we need to consider both properties so as to make more accurate estimates. To this end, we use the nuclear norm that has been shown to be effective in characterizing both properties. Extensive experiments validate the effectiveness of nuclear norm for various models (e.g., ViT and ConvNeXt), different datasets (e.g., ImageNet and CUB-200), and diverse types of distribution shifts (e.g., style shift and reproduction shift). We show that the nuclear norm is more accurate and robust in accuracy estimation than existing methods. Furthermore, we validate the feasibility of other measurements (e.g., mutual information maximization) for characterizing dispersity and confidence. Lastly, we investigate the limitation of the nuclear norm, study its improved variant under severe class imbalance, and discuss potential directions.
PU GNN: Chargeback Fraud Detection in P2E MMORPGs via Graph Attention Networks with Imbalanced PU Labels
Nov 16, 2022The recent advent of play-to-earn (P2E) systems in massively multiplayer online role-playing games (MMORPGs) has made in-game goods interchangeable with real-world values more than ever before. The goods in the P2E MMORPGs can be directly exchanged with cryptocurrencies such as Bitcoin, Ethereum, or Klaytn via blockchain networks. Unlike traditional in-game goods, once they had been written to the blockchains, P2E goods cannot be restored by the game operation teams even with chargeback fraud such as payment fraud, cancellation, or refund. To tackle the problem, we propose a novel chargeback fraud prediction method, PU GNN, which leverages graph attention networks with PU loss to capture both the players' in-game behavior with P2E token transaction patterns. With the adoption of modified GraphSMOTE, the proposed model handles the imbalanced distribution of labels in chargeback fraud datasets. The conducted experiments on two real-world P2E MMORPG datasets demonstrate that PU GNN achieves superior performances over previously suggested methods.
Controllable Dynamic Multi-Task Architectures
Mar 28, 2022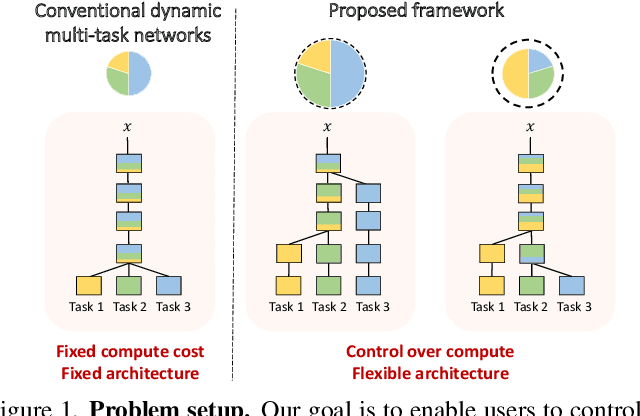
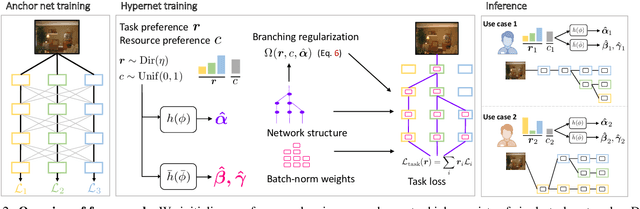

Multi-task learning commonly encounters competition for resources among tasks, specifically when model capacity is limited. This challenge motivates models which allow control over the relative importance of tasks and total compute cost during inference time. In this work, we propose such a controllable multi-task network that dynamically adjusts its architecture and weights to match the desired task preference as well as the resource constraints. In contrast to the existing dynamic multi-task approaches that adjust only the weights within a fixed architecture, our approach affords the flexibility to dynamically control the total computational cost and match the user-preferred task importance better. We propose a disentangled training of two hypernetworks, by exploiting task affinity and a novel branching regularized loss, to take input preferences and accordingly predict tree-structured models with adapted weights. Experiments on three multi-task benchmarks, namely PASCAL-Context, NYU-v2, and CIFAR-100, show the efficacy of our approach. Project page is available at https://www.nec-labs.com/~mas/DYMU.