 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriving Video Retrieval for Complex Queries with Structured Grounding
Jun 08, 2026Video retrieval at scale is central to data curation and safety validation in autonomous driving, where users want to find not only scenes but also dynamic events such as cut-ins and hard braking. Existing vision-language and keyword-based retrieval methods often miss these events because the relevant motion may not be explicitly described in text or captured by lexical overlap. Rule-based retrieval can encode such events more directly, but it is brittle: generated or hand-written rules often fail when their assumptions do not match real driving data. We propose STRIVE-D, a data-calibrated retrieval framework for driving videos. It uses weakly labeled in-domain videos to estimate when a query rule is reliable, adapt rules that mismatch observed data, and fuse calibrated rule scores with vision-language and keyword-based retrieval signals. Across three driving benchmarks, including newly released human-annotated event data on DrivingDojo, STRIVE-D delivers up to 84% relative improvement in top-1 accuracy over state-of-the-art methods.
Reducing Oracle Feedback with Vision-Language Embeddings for Preference-Based RL
Mar 30, 2026Preference-based reinforcement learning can learn effective reward functions from comparisons, but its scalability is constrained by the high cost of oracle feedback. Lightweight vision-language embedding (VLE) models provide a cheaper alternative, but their noisy outputs limit their effectiveness as standalone reward generators. To address this challenge, we propose ROVED, a hybrid framework that combines VLE-based supervision with targeted oracle feedback. Our method uses the VLE to generate segment-level preferences and defers to an oracle only for samples with high uncertainty, identified through a filtering mechanism. In addition, we introduce a parameter-efficient fine-tuning method that adapts the VLE with the obtained oracle feedback in order to improve the model over time in a synergistic fashion. This ensures the retention of the scalability of embeddings and the accuracy of oracles, while avoiding their inefficiencies. Across multiple robotic manipulation tasks, ROVED matches or surpasses prior preference-based methods while reducing oracle queries by up to 80%. Remarkably, the adapted VLE generalizes across tasks, yielding cumulative annotation savings of up to 90%, highlighting the practicality of combining scalable embeddings with precise oracle supervision for preference-based RL.
COOPERTRIM: Adaptive Data Selection for Uncertainty-Aware Cooperative Perception
Feb 07, 2026Cooperative perception enables autonomous agents to share encoded representations over wireless communication to enhance each other's live situational awareness. However, the tension between the limited communication bandwidth and the rich sensor information hinders its practical deployment. Recent studies have explored selection strategies that share only a subset of features per frame while striving to keep the performance on par. Nevertheless, the bandwidth requirement still stresses current wireless technologies. To fundamentally ease the tension, we take a proactive approach, exploiting the temporal continuity to identify features that capture environment dynamics, while avoiding repetitive and redundant transmission of static information. By incorporating temporal awareness, agents are empowered to dynamically adapt the sharing quantity according to environment complexity. We instantiate this intuition into an adaptive selection framework, COOPERTRIM, which introduces a novel conformal temporal uncertainty metric to gauge feature relevance, and a data-driven mechanism to dynamically determine the sharing quantity. To evaluate COOPERTRIM, we take semantic segmentation and 3D detection as example tasks. Across multiple open-source cooperative segmentation and detection models, COOPERTRIM achieves up to 80.28% and 72.52% bandwidth reduction respectively while maintaining a comparable accuracy. Relative to other selection strategies, COOPERTRIM also improves IoU by as much as 45.54% with up to 72% less bandwidth. Combined with compression strategies, COOPERTRIM can further reduce bandwidth usage to as low as 1.46% without compromising IoU performance. Qualitative results show COOPERTRIM gracefully adapts to environmental dynamics, localization error, and communication latency, demonstrating flexibility and paving the way for real-world deployment.
When and How Unlabeled Data Provably Improve In-Context Learning
Jun 18, 2025Recent research shows that in-context learning (ICL) can be effective even when demonstrations have missing or incorrect labels. To shed light on this capability, we examine a canonical setting where the demonstrations are drawn according to a binary Gaussian mixture model (GMM) and a certain fraction of the demonstrations have missing labels. We provide a comprehensive theoretical study to show that: (1) The loss landscape of one-layer linear attention models recover the optimal fully-supervised estimator but completely fail to exploit unlabeled data; (2) In contrast, multilayer or looped transformers can effectively leverage unlabeled data by implicitly constructing estimators of the form $\sum_{i\ge 0} a_i (X^\top X)^iX^\top y$ with $X$ and $y$ denoting features and partially-observed labels (with missing entries set to zero). We characterize the class of polynomials that can be expressed as a function of depth and draw connections to Expectation Maximization, an iterative pseudo-labeling algorithm commonly used in semi-supervised learning. Importantly, the leading polynomial power is exponential in depth, so mild amount of depth/looping suffices. As an application of theory, we propose looping off-the-shelf tabular foundation models to enhance their semi-supervision capabilities. Extensive evaluations on real-world datasets show that our method significantly improves the semisupervised tabular learning performance over the standard single pass inference.
A Certified Unlearning Approach without Access to Source Data
Jun 06, 2025
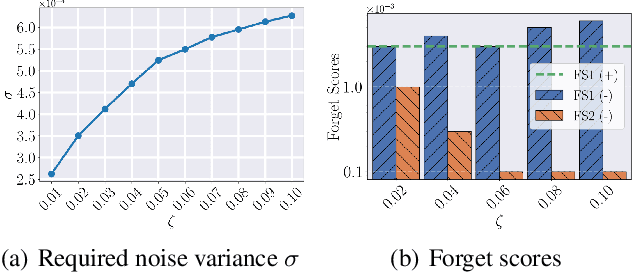
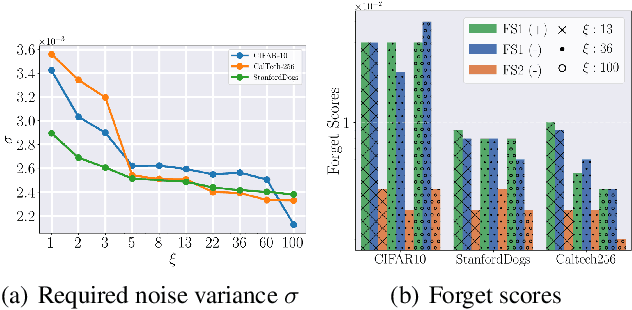
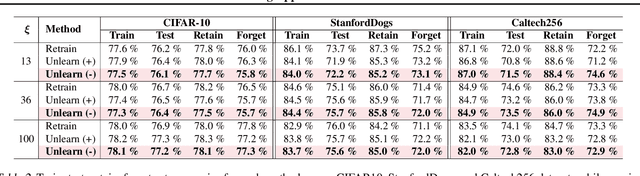
With the growing adoption of data privacy regulations, the ability to erase private or copyrighted information from trained models has become a crucial requirement. Traditional unlearning methods often assume access to the complete training dataset, which is unrealistic in scenarios where the source data is no longer available. To address this challenge, we propose a certified unlearning framework that enables effective data removal \final{without access to the original training data samples}. Our approach utilizes a surrogate dataset that approximates the statistical properties of the source data, allowing for controlled noise scaling based on the statistical distance between the two. \updated{While our theoretical guarantees assume knowledge of the exact statistical distance, practical implementations typically approximate this distance, resulting in potentially weaker but still meaningful privacy guarantees.} This ensures strong guarantees on the model's behavior post-unlearning while maintaining its overall utility. We establish theoretical bounds, introduce practical noise calibration techniques, and validate our method through extensive experiments on both synthetic and real-world datasets. The results demonstrate the effectiveness and reliability of our approach in privacy-sensitive settings.
Preference VLM: Leveraging VLMs for Scalable Preference-Based Reinforcement Learning
Feb 03, 2025



Preference-based reinforcement learning (RL) offers a promising approach for aligning policies with human intent but is often constrained by the high cost of human feedback. In this work, we introduce PrefVLM, a framework that integrates Vision-Language Models (VLMs) with selective human feedback to significantly reduce annotation requirements while maintaining performance. Our method leverages VLMs to generate initial preference labels, which are then filtered to identify uncertain cases for targeted human annotation. Additionally, we adapt VLMs using a self-supervised inverse dynamics loss to improve alignment with evolving policies. Experiments on Meta-World manipulation tasks demonstrate that PrefVLM achieves comparable or superior success rates to state-of-the-art methods while using up to 2 x fewer human annotations. Furthermore, we show that adapted VLMs enable efficient knowledge transfer across tasks, further minimizing feedback needs. Our results highlight the potential of combining VLMs with selective human supervision to make preference-based RL more scalable and practical.
Selective Attention: Enhancing Transformer through Principled Context Control
Nov 19, 2024



The attention mechanism within the transformer architecture enables the model to weigh and combine tokens based on their relevance to the query. While self-attention has enjoyed major success, it notably treats all queries $q$ in the same way by applying the mapping $V^\top\text{softmax}(Kq)$, where $V,K$ are the value and key embeddings respectively. In this work, we argue that this uniform treatment hinders the ability to control contextual sparsity and relevance. As a solution, we introduce the $\textit{Selective Self-Attention}$ (SSA) layer that augments the softmax nonlinearity with a principled temperature scaling strategy. By controlling temperature, SSA adapts the contextual sparsity of the attention map to the query embedding and its position in the context window. Through theory and experiments, we demonstrate that this alleviates attention dilution, aids the optimization process, and enhances the model's ability to control softmax spikiness of individual queries. We also incorporate temperature scaling for value embeddings and show that it boosts the model's ability to suppress irrelevant/noisy tokens. Notably, SSA is a lightweight method which introduces less than 0.5% new parameters through a weight-sharing strategy and can be fine-tuned on existing LLMs. Extensive empirical evaluations demonstrate that SSA-equipped models achieve a noticeable and consistent accuracy improvement on language modeling benchmarks.
Multi-modal Pose Diffuser: A Multimodal Generative Conditional Pose Prior
Oct 18, 2024The Skinned Multi-Person Linear (SMPL) model plays a crucial role in 3D human pose estimation, providing a streamlined yet effective representation of the human body. However, ensuring the validity of SMPL configurations during tasks such as human mesh regression remains a significant challenge , highlighting the necessity for a robust human pose prior capable of discerning realistic human poses. To address this, we introduce MOPED: \underline{M}ulti-m\underline{O}dal \underline{P}os\underline{E} \underline{D}iffuser. MOPED is the first method to leverage a novel multi-modal conditional diffusion model as a prior for SMPL pose parameters. Our method offers powerful unconditional pose generation with the ability to condition on multi-modal inputs such as images and text. This capability enhances the applicability of our approach by incorporating additional context often overlooked in traditional pose priors. Extensive experiments across three distinct tasks-pose estimation, pose denoising, and pose completion-demonstrate that our multi-modal diffusion model-based prior significantly outperforms existing methods. These results indicate that our model captures a broader spectrum of plausible human poses.
Vision-based Xylem Wetness Classification in Stem Water Potential Determination
Sep 24, 2024



Water is often overused in irrigation, making efficient management of it crucial. Precision Agriculture emphasizes tools like stem water potential (SWP) analysis for better plant status determination. However, such tools often require labor-intensive in-situ sampling. Automation and machine learning can streamline this process and enhance outcomes. This work focused on automating stem detection and xylem wetness classification using the Scholander Pressure Chamber, a widely used but demanding method for SWP measurement. The aim was to refine stem detection and develop computer-vision-based methods to better classify water emergence at the xylem. To this end, we collected and manually annotated video data, applying vision- and learning-based methods for detection and classification. Additionally, we explored data augmentation and fine-tuned parameters to identify the most effective models. The identified best-performing models for stem detection and xylem wetness classification were evaluated end-to-end over 20 SWP measurements. Learning-based stem detection via YOLOv8n combined with ResNet50-based classification achieved a Top-1 accuracy of 80.98%, making it the best-performing approach for xylem wetness classification.
Efficient Transformer Encoders for Mask2Former-style models
Apr 23, 2024



Vision transformer based models bring significant improvements for image segmentation tasks. Although these architectures offer powerful capabilities irrespective of specific segmentation tasks, their use of computational resources can be taxing on deployed devices. One way to overcome this challenge is by adapting the computation level to the specific needs of the input image rather than the current one-size-fits-all approach. To this end, we introduce ECO-M2F or EffiCient TransfOrmer Encoders for Mask2Former-style models. Noting that the encoder module of M2F-style models incur high resource-intensive computations, ECO-M2F provides a strategy to self-select the number of hidden layers in the encoder, conditioned on the input image. To enable this self-selection ability for providing a balance between performance and computational efficiency, we present a three step recipe. The first step is to train the parent architecture to enable early exiting from the encoder. The second step is to create an derived dataset of the ideal number of encoder layers required for each training example. The third step is to use the aforementioned derived dataset to train a gating network that predicts the number of encoder layers to be used, conditioned on the input image. Additionally, to change the computational-accuracy tradeoff, only steps two and three need to be repeated which significantly reduces retraining time. Experiments on the public datasets show that the proposed approach reduces expected encoder computational cost while maintaining performance, adapts to various user compute resources, is flexible in architecture configurations, and can be extended beyond the segmentation task to object detection.