 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeGuE: Semantic Guided Exploration for Mobile Robots
Apr 04, 2025The rise of embodied AI applications has enabled robots to perform complex tasks which require a sophisticated understanding of their environment. To enable successful robot operation in such settings, maps must be constructed so that they include semantic information, in addition to geometric information. In this paper, we address the novel problem of semantic exploration, whereby a mobile robot must autonomously explore an environment to fully map both its structure and the semantic appearance of features. We develop a method based on next-best-view exploration, where potential poses are scored based on the semantic features visible from that pose. We explore two alternative methods for sampling potential views and demonstrate the effectiveness of our framework in both simulation and physical experiments. Automatic creation of high-quality semantic maps can enable robots to better understand and interact with their environments and enable future embodied AI applications to be more easily deployed.
Language-guided Robust Navigation for Mobile Robots in Dynamically-changing Environments
Sep 28, 2024



In this paper, we develop an embodied AI system for human-in-the-loop navigation with a wheeled mobile robot. We propose a direct yet effective method of monitoring the robot's current plan to detect changes in the environment that impact the intended trajectory of the robot significantly and then query a human for feedback. We also develop a means to parse human feedback expressed in natural language into local navigation waypoints and integrate it into a global planning system, by leveraging a map of semantic features and an aligned obstacle map. Extensive testing in simulation and physical hardware experiments with a resource-constrained wheeled robot tasked to navigate in a real-world environment validate the efficacy and robustness of our method. This work can support applications like precision agriculture and construction, where persistent monitoring of the environment provides a human with information about the environment state.
Vision-based Xylem Wetness Classification in Stem Water Potential Determination
Sep 24, 2024



Water is often overused in irrigation, making efficient management of it crucial. Precision Agriculture emphasizes tools like stem water potential (SWP) analysis for better plant status determination. However, such tools often require labor-intensive in-situ sampling. Automation and machine learning can streamline this process and enhance outcomes. This work focused on automating stem detection and xylem wetness classification using the Scholander Pressure Chamber, a widely used but demanding method for SWP measurement. The aim was to refine stem detection and develop computer-vision-based methods to better classify water emergence at the xylem. To this end, we collected and manually annotated video data, applying vision- and learning-based methods for detection and classification. Additionally, we explored data augmentation and fine-tuned parameters to identify the most effective models. The identified best-performing models for stem detection and xylem wetness classification were evaluated end-to-end over 20 SWP measurements. Learning-based stem detection via YOLOv8n combined with ResNet50-based classification achieved a Top-1 accuracy of 80.98%, making it the best-performing approach for xylem wetness classification.
SUMMIT: Source-Free Adaptation of Uni-Modal Models to Multi-Modal Targets
Aug 23, 2023



Scene understanding using multi-modal data is necessary in many applications, e.g., autonomous navigation. To achieve this in a variety of situations, existing models must be able to adapt to shifting data distributions without arduous data annotation. Current approaches assume that the source data is available during adaptation and that the source consists of paired multi-modal data. Both these assumptions may be problematic for many applications. Source data may not be available due to privacy, security, or economic concerns. Assuming the existence of paired multi-modal data for training also entails significant data collection costs and fails to take advantage of widely available freely distributed pre-trained uni-modal models. In this work, we relax both of these assumptions by addressing the problem of adapting a set of models trained independently on uni-modal data to a target domain consisting of unlabeled multi-modal data, without having access to the original source dataset. Our proposed approach solves this problem through a switching framework which automatically chooses between two complementary methods of cross-modal pseudo-label fusion -- agreement filtering and entropy weighting -- based on the estimated domain gap. We demonstrate our work on the semantic segmentation problem. Experiments across seven challenging adaptation scenarios verify the efficacy of our approach, achieving results comparable to, and in some cases outperforming, methods which assume access to source data. Our method achieves an improvement in mIoU of up to 12% over competing baselines. Our code is publicly available at https://github.com/csimo005/SUMMIT.
Hybrid LSTM and Encoder-Decoder Architecture for Detection of Image Forgeries
Mar 06, 2019
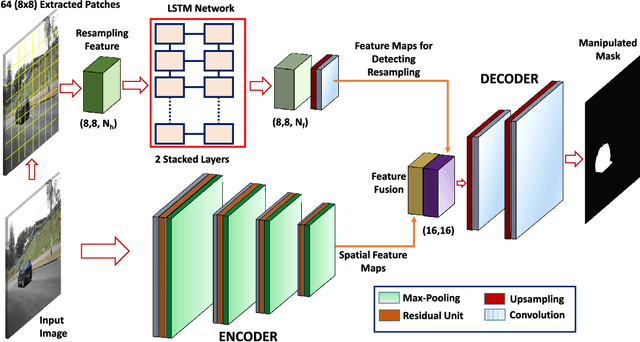

With advanced image journaling tools, one can easily alter the semantic meaning of an image by exploiting certain manipulation techniques such as copy-clone, object splicing, and removal, which mislead the viewers. In contrast, the identification of these manipulations becomes a very challenging task as manipulated regions are not visually apparent. This paper proposes a high-confidence manipulation localization architecture which utilizes resampling features, Long-Short Term Memory (LSTM) cells, and encoder-decoder network to segment out manipulated regions from non-manipulated ones. Resampling features are used to capture artifacts like JPEG quality loss, upsampling, downsampling, rotation, and shearing. The proposed network exploits larger receptive fields (spatial maps) and frequency domain correlation to analyze the discriminative characteristics between manipulated and non-manipulated regions by incorporating encoder and LSTM network. Finally, decoder network learns the mapping from low-resolution feature maps to pixel-wise predictions for image tamper localization. With predicted mask provided by final layer (softmax) of the proposed architecture, end-to-end training is performed to learn the network parameters through back-propagation using ground-truth masks. Furthermore, a large image splicing dataset is introduced to guide the training process. The proposed method is capable of localizing image manipulations at pixel level with high precision, which is demonstrated through rigorous experimentation on three diverse datasets.