 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBright 4B: Scaling Hyperspherical Learning for Segmentation in 3D Brightfield Microscopy
Dec 27, 2025Label-free 3D brightfield microscopy offers a fast and noninvasive way to visualize cellular morphology, yet robust volumetric segmentation still typically depends on fluorescence or heavy post-processing. We address this gap by introducing Bright-4B, a 4 billion parameter foundation model that learns on the unit hypersphere to segment subcellular structures directly from 3D brightfield volumes. Bright-4B combines a hardware-aligned Native Sparse Attention mechanism (capturing local, coarse, and selected global context), depth-width residual HyperConnections that stabilize representation flow, and a soft Mixture-of-Experts for adaptive capacity. A plug-and-play anisotropic patch embed further respects confocal point-spread and axial thinning, enabling geometry-faithful 3D tokenization. The resulting model produces morphology-accurate segmentations of nuclei, mitochondria, and other organelles from brightfield stacks alone--without fluorescence, auxiliary channels, or handcrafted post-processing. Across multiple confocal datasets, Bright-4B preserves fine structural detail across depth and cell types, outperforming contemporary CNN and Transformer baselines. All code, pretrained weights, and models for downstream finetuning will be released to advance large-scale, label-free 3D cell mapping.
RareSpot: Spotting Small and Rare Wildlife in Aerial Imagery with Multi-Scale Consistency and Context-Aware Augmentation
Jun 23, 2025Automated detection of small and rare wildlife in aerial imagery is crucial for effective conservation, yet remains a significant technical challenge. Prairie dogs exemplify this issue: their ecological importance as keystone species contrasts sharply with their elusive presence--marked by small size, sparse distribution, and subtle visual features--which undermines existing detection approaches. To address these challenges, we propose RareSpot, a robust detection framework integrating multi-scale consistency learning and context-aware augmentation. Our multi-scale consistency approach leverages structured alignment across feature pyramids, enhancing fine-grained object representation and mitigating scale-related feature loss. Complementarily, context-aware augmentation strategically synthesizes challenging training instances by embedding difficult-to-detect samples into realistic environmental contexts, significantly boosting model precision and recall. Evaluated on an expert-annotated prairie dog drone imagery benchmark, our method achieves state-of-the-art performance, improving detection accuracy by over 35% compared to baseline methods. Importantly, it generalizes effectively across additional wildlife datasets, demonstrating broad applicability. The RareSpot benchmark and approach not only support critical ecological monitoring but also establish a new foundation for detecting small, rare species in complex aerial scenes.
ReeFRAME: Reeb Graph based Trajectory Analysis Framework to Capture Top-Down and Bottom-Up Patterns of Life
Oct 19, 2024In this paper, we present ReeFRAME, a scalable Reeb graph-based framework designed to analyze vast volumes of GPS-enabled human trajectory data generated at 1Hz frequency. ReeFRAME models Patterns-of-life (PoL) at both the population and individual levels, utilizing Multi-Agent Reeb Graphs (MARGs) for population-level patterns and Temporal Reeb Graphs (TERGs) for individual trajectories. The framework's linear algorithmic complexity relative to the number of time points ensures scalability for anomaly detection. We validate ReeFRAME on six large-scale anomaly detection datasets, simulating real-time patterns with up to 500,000 agents over two months.
CIMGEN: Controlled Image Manipulation by Finetuning Pretrained Generative Models on Limited Data
Jan 23, 2024Content creation and image editing can benefit from flexible user controls. A common intermediate representation for conditional image generation is a semantic map, that has information of objects present in the image. When compared to raw RGB pixels, the modification of semantic map is much easier. One can take a semantic map and easily modify the map to selectively insert, remove, or replace objects in the map. The method proposed in this paper takes in the modified semantic map and alter the original image in accordance to the modified map. The method leverages traditional pre-trained image-to-image translation GANs, such as CycleGAN or Pix2Pix GAN, that are fine-tuned on a limited dataset of reference images associated with the semantic maps. We discuss the qualitative and quantitative performance of our technique to illustrate its capacity and possible applications in the fields of image forgery and image editing. We also demonstrate the effectiveness of the proposed image forgery technique in thwarting the numerous deep learning-based image forensic techniques, highlighting the urgent need to develop robust and generalizable image forensic tools in the fight against the spread of fake media.
BLoad: Enhancing Neural Network Training with Efficient Sequential Data Handling
Oct 16, 2023



The increasing complexity of modern deep neural network models and the expanding sizes of datasets necessitate the development of optimized and scalable training methods. In this white paper, we addressed the challenge of efficiently training neural network models using sequences of varying sizes. To address this challenge, we propose a novel training scheme that enables efficient distributed data-parallel training on sequences of different sizes with minimal overhead. By using this scheme we were able to reduce the padding amount by more than 100$x$ while not deleting a single frame, resulting in an overall increased performance on both training time and Recall in our experiments.
Q-RBSA: High-Resolution 3D EBSD Map Generation Using An Efficient Quaternion Transformer Network
Mar 19, 2023Gathering 3D material microstructural information is time-consuming, expensive, and energy-intensive. Acquisition of 3D data has been accelerated by developments in serial sectioning instrument capabilities; however, for crystallographic information, the electron backscatter diffraction (EBSD) imaging modality remains rate limiting. We propose a physics-based efficient deep learning framework to reduce the time and cost of collecting 3D EBSD maps. Our framework uses a quaternion residual block self-attention network (QRBSA) to generate high-resolution 3D EBSD maps from sparsely sectioned EBSD maps. In QRBSA, quaternion-valued convolution effectively learns local relations in orientation space, while self-attention in the quaternion domain captures long-range correlations. We apply our framework to 3D data collected from commercially relevant titanium alloys, showing both qualitatively and quantitatively that our method can predict missing samples (EBSD information between sparsely sectioned mapping points) as compared to high-resolution ground truth 3D EBSD maps.
DDS: Decoupled Dynamic Scene-Graph Generation Network
Jan 18, 2023Scene-graph generation involves creating a structural representation of the relationships between objects in a scene by predicting subject-object-relation triplets from input data. However, existing methods show poor performance in detecting triplets outside of a predefined set, primarily due to their reliance on dependent feature learning. To address this issue we propose DDS -- a decoupled dynamic scene-graph generation network -- that consists of two independent branches that can disentangle extracted features. The key innovation of the current paper is the decoupling of the features representing the relationships from those of the objects, which enables the detection of novel object-relationship combinations. The DDS model is evaluated on three datasets and outperforms previous methods by a significant margin, especially in detecting previously unseen triplets.
3D Neuron Morphology Analysis
Dec 14, 2022


We consider the problem of finding an accurate representation of neuron shapes, extracting sub-cellular features, and classifying neurons based on neuron shapes. In neuroscience research, the skeleton representation is often used as a compact and abstract representation of neuron shapes. However, existing methods are limited to getting and analyzing "curve" skeletons which can only be applied for tubular shapes. This paper presents a 3D neuron morphology analysis method for more general and complex neuron shapes. First, we introduce the concept of skeleton mesh to represent general neuron shapes and propose a novel method for computing mesh representations from 3D surface point clouds. A skeleton graph is then obtained from skeleton mesh and is used to extract sub-cellular features. Finally, an unsupervised learning method is used to embed the skeleton graph for neuron classification. Extensive experiment results are provided and demonstrate the robustness of our method to analyze neuron morphology.
Generalizable Deepfake Detection with Phase-Based Motion Analysis
Nov 17, 2022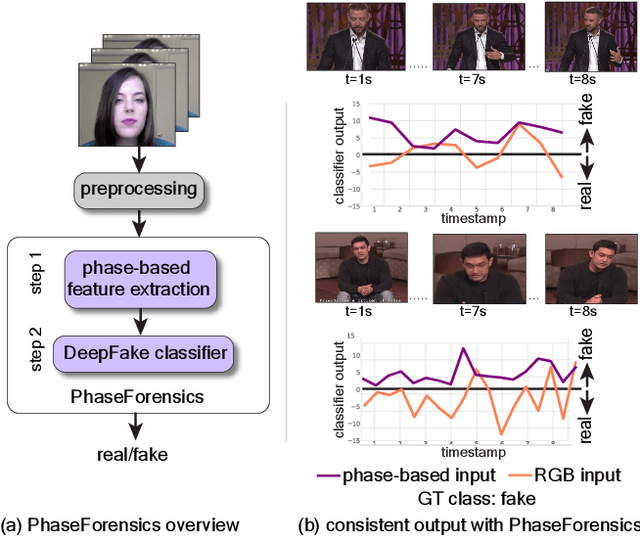
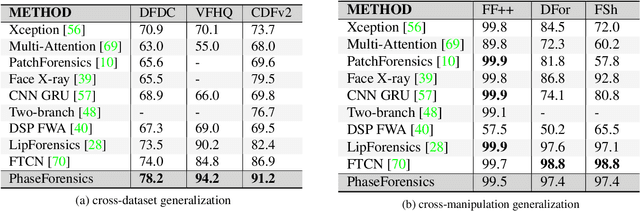

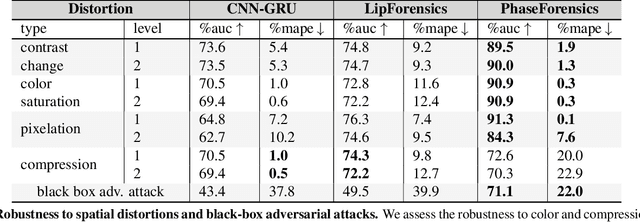
We propose PhaseForensics, a DeepFake (DF) video detection method that leverages a phase-based motion representation of facial temporal dynamics. Existing methods relying on temporal inconsistencies for DF detection present many advantages over the typical frame-based methods. However, they still show limited cross-dataset generalization and robustness to common distortions. These shortcomings are partially due to error-prone motion estimation and landmark tracking, or the susceptibility of the pixel intensity-based features to spatial distortions and the cross-dataset domain shifts. Our key insight to overcome these issues is to leverage the temporal phase variations in the band-pass components of the Complex Steerable Pyramid on face sub-regions. This not only enables a robust estimate of the temporal dynamics in these regions, but is also less prone to cross-dataset variations. Furthermore, the band-pass filters used to compute the local per-frame phase form an effective defense against the perturbations commonly seen in gradient-based adversarial attacks. Overall, with PhaseForensics, we show improved distortion and adversarial robustness, and state-of-the-art cross-dataset generalization, with 91.2% video-level AUC on the challenging CelebDFv2 (a recent state-of-the-art compares at 86.9%).
Context-Matched Collage Generation for Underwater Invertebrate Detection
Nov 15, 2022The quality and size of training sets often limit the performance of many state of the art object detectors. However, in many scenarios, it can be difficult to collect images for training, not to mention the costs associated with collecting annotations suitable for training these object detectors. For these reasons, on challenging video datasets such as the Dataset for Underwater Substrate and Invertebrate Analysis (DUSIA), budgets may only allow for collecting and providing partial annotations. To aid in the challenges associated with training with limited and partial annotations, we introduce Context Matched Collages, which leverage explicit context labels to combine unused background examples with existing annotated data to synthesize additional training samples that ultimately improve object detection performance. By combining a set of our generated collage images with the original training set, we see improved performance using three different object detectors on DUSIA, ultimately achieving state of the art object detection performance on the dataset.