 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvatar Fingerprinting for Authorized Use of Synthetic Talking-Head Videos
May 05, 2023



Modern generators render talking-head videos with impressive levels of photorealism, ushering in new user experiences such as videoconferencing under constrained bandwidth budgets. Their safe adoption, however, requires a mechanism to verify if the rendered video is trustworthy. For instance, for videoconferencing we must identify cases in which a synthetic video portrait uses the appearance of an individual without their consent. We term this task avatar fingerprinting. We propose to tackle it by leveraging facial motion signatures unique to each person. Specifically, we learn an embedding in which the motion signatures of one identity are grouped together, and pushed away from those of other identities, regardless of the appearance in the synthetic video. Avatar fingerprinting algorithms will be critical as talking head generators become more ubiquitous, and yet no large scale datasets exist for this new task. Therefore, we contribute a large dataset of people delivering scripted and improvised short monologues, accompanied by synthetic videos in which we render videos of one person using the facial appearance of another. Project page: https://research.nvidia.com/labs/nxp/avatar-fingerprinting/.
Generalizable Deepfake Detection with Phase-Based Motion Analysis
Nov 17, 2022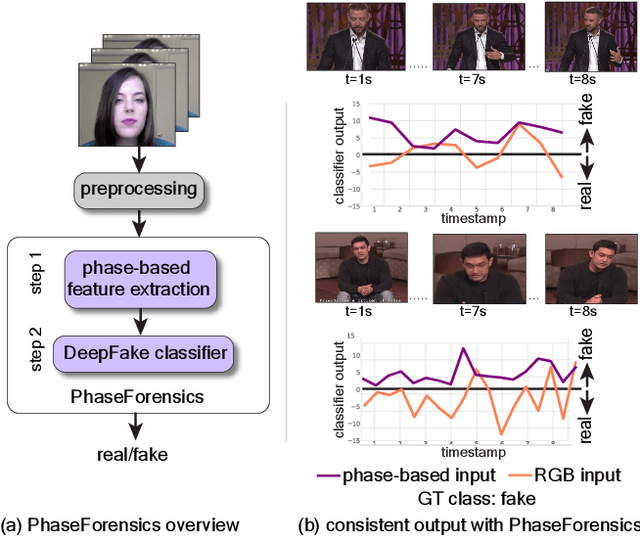
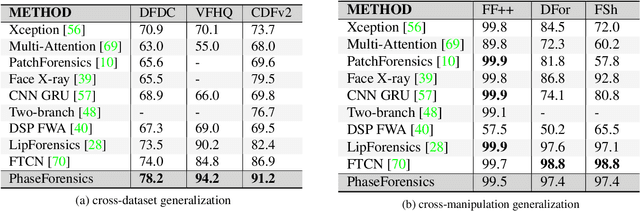

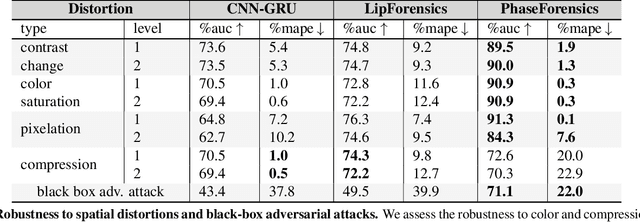
We propose PhaseForensics, a DeepFake (DF) video detection method that leverages a phase-based motion representation of facial temporal dynamics. Existing methods relying on temporal inconsistencies for DF detection present many advantages over the typical frame-based methods. However, they still show limited cross-dataset generalization and robustness to common distortions. These shortcomings are partially due to error-prone motion estimation and landmark tracking, or the susceptibility of the pixel intensity-based features to spatial distortions and the cross-dataset domain shifts. Our key insight to overcome these issues is to leverage the temporal phase variations in the band-pass components of the Complex Steerable Pyramid on face sub-regions. This not only enables a robust estimate of the temporal dynamics in these regions, but is also less prone to cross-dataset variations. Furthermore, the band-pass filters used to compute the local per-frame phase form an effective defense against the perturbations commonly seen in gradient-based adversarial attacks. Overall, with PhaseForensics, we show improved distortion and adversarial robustness, and state-of-the-art cross-dataset generalization, with 91.2% video-level AUC on the challenging CelebDFv2 (a recent state-of-the-art compares at 86.9%).
LOCL: Learning Object-Attribute Composition using Localization
Oct 07, 2022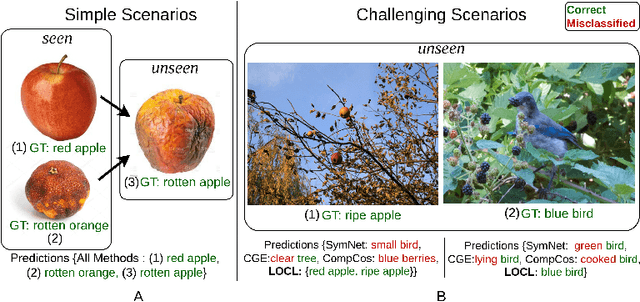
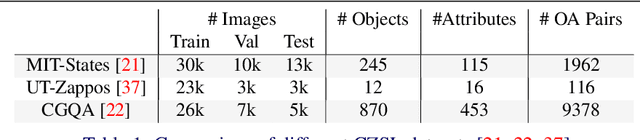
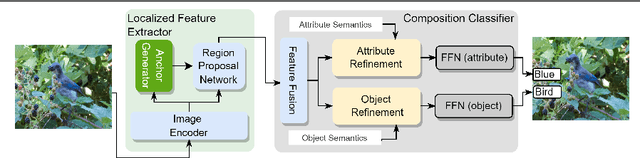
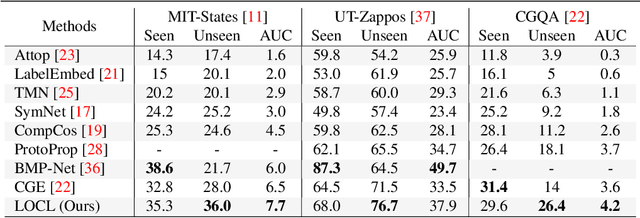
This paper describes LOCL (Learning Object Attribute Composition using Localization) that generalizes composition zero shot learning to objects in cluttered and more realistic settings. The problem of unseen Object Attribute (OA) associations has been well studied in the field, however, the performance of existing methods is limited in challenging scenes. In this context, our key contribution is a modular approach to localizing objects and attributes of interest in a weakly supervised context that generalizes robustly to unseen configurations. Localization coupled with a composition classifier significantly outperforms state of the art (SOTA) methods, with an improvement of about 12% on currently available challenging datasets. Further, the modularity enables the use of localized feature extractor to be used with existing OA compositional learning methods to improve their overall performance.
Noise-Aware Saliency Prediction for Videos with Incomplete Gaze Data
Apr 16, 2021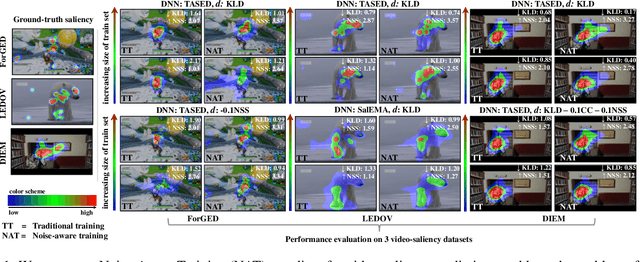
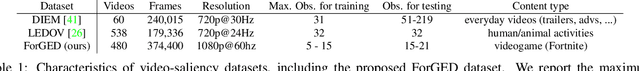
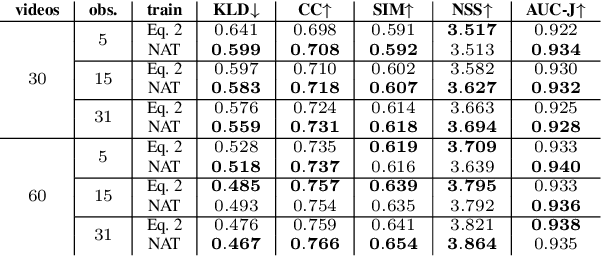

Deep-learning-based algorithms have led to impressive results in visual-saliency prediction, but the impact of noise in training gaze data has been largely overlooked. This issue is especially relevant for videos, where the gaze data tends to be incomplete, and thus noisier, compared to images. Therefore, we propose a noise-aware training (NAT) paradigm for visual-saliency prediction that quantifies the uncertainty arising from gaze data incompleteness and inaccuracy, and accounts for it in training. We demonstrate the advantage of NAT independently of the adopted model architecture, loss function, or training dataset. Given its robustness to the noise in incomplete training datasets, NAT ushers in the possibility of designing gaze datasets with fewer human subjects. We also introduce the first dataset that offers a video-game context for video-saliency research, with rich temporal semantics, and multiple gaze attractors per frame.
PieAPP: Perceptual Image-Error Assessment through Pairwise Preference
Jun 06, 2018
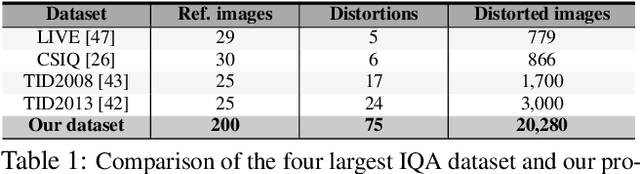
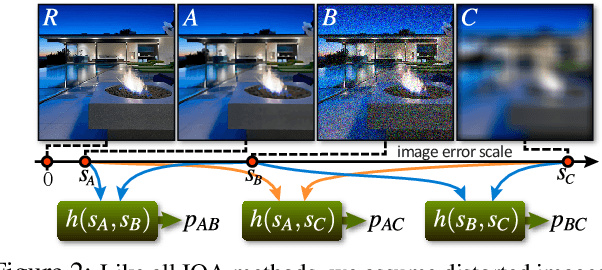
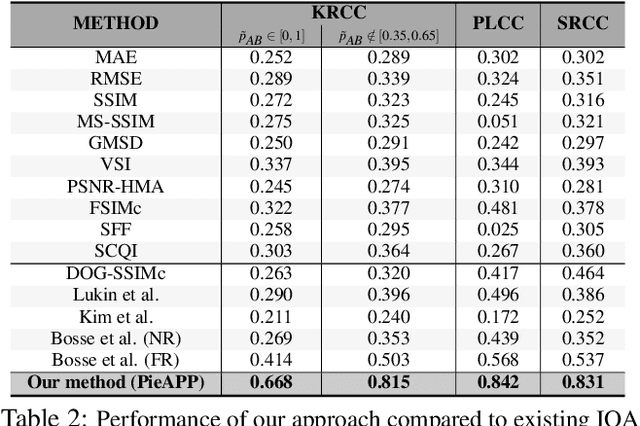
The ability to estimate the perceptual error between images is an important problem in computer vision with many applications. Although it has been studied extensively, however, no method currently exists that can robustly predict visual differences like humans. Some previous approaches used hand-coded models, but they fail to model the complexity of the human visual system. Others used machine learning to train models on human-labeled datasets, but creating large, high-quality datasets is difficult because people are unable to assign consistent error labels to distorted images. In this paper, we present a new learning-based method that is the first to predict perceptual image error like human observers. Since it is much easier for people to compare two given images and identify the one more similar to a reference than to assign quality scores to each, we propose a new, large-scale dataset labeled with the probability that humans will prefer one image over another. We then train a deep-learning model using a novel, pairwise-learning framework to predict the preference of one distorted image over the other. Our key observation is that our trained network can then be used separately with only one distorted image and a reference to predict its perceptual error, without ever being trained on explicit human perceptual-error labels. The perceptual error estimated by our new metric, PieAPP, is well-correlated with human opinion. Furthermore, it significantly outperforms existing algorithms, beating the state-of-the-art by almost 3x on our test set in terms of binary error rate, while also generalizing to new kinds of distortions, unlike previous learning-based methods.
* 8 pages; 5 figures; proceedings of CVPR 2018