 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Move Like Professional Counter-Strike Players
Aug 25, 2024
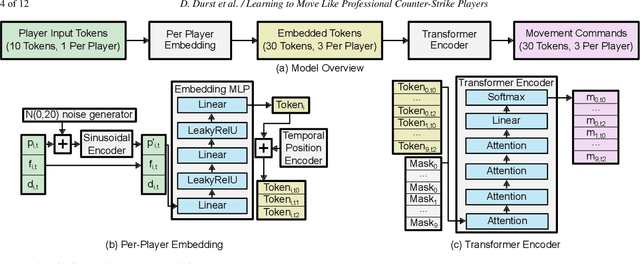
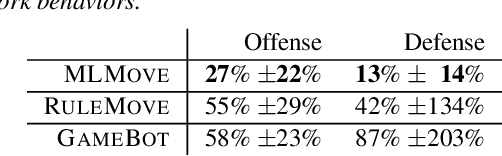
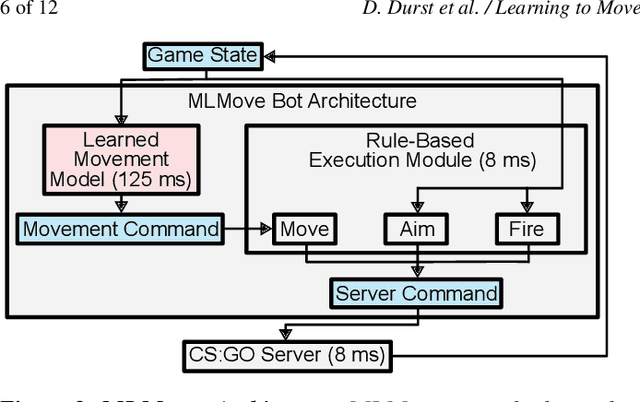
In multiplayer, first-person shooter games like Counter-Strike: Global Offensive (CS:GO), coordinated movement is a critical component of high-level strategic play. However, the complexity of team coordination and the variety of conditions present in popular game maps make it impractical to author hand-crafted movement policies for every scenario. We show that it is possible to take a data-driven approach to creating human-like movement controllers for CS:GO. We curate a team movement dataset comprising 123 hours of professional game play traces, and use this dataset to train a transformer-based movement model that generates human-like team movement for all players in a "Retakes" round of the game. Importantly, the movement prediction model is efficient. Performing inference for all players takes less than 0.5 ms per game step (amortized cost) on a single CPU core, making it plausible for use in commercial games today. Human evaluators assess that our model behaves more like humans than both commercially-available bots and procedural movement controllers scripted by experts (16% to 59% higher by TrueSkill rating of "human-like"). Using experiments involving in-game bot vs. bot self-play, we demonstrate that our model performs simple forms of teamwork, makes fewer common movement mistakes, and yields movement distributions, player lifetimes, and kill locations similar to those observed in professional CS:GO match play.
* The project website is at https://davidbdurst.com/mlmove/
Online Overexposed Pixels Hallucination in Videos with Adaptive Reference Frame Selection
Aug 29, 2023Low dynamic range (LDR) cameras cannot deal with wide dynamic range inputs, frequently leading to local overexposure issues. We present a learning-based system to reduce these artifacts without resorting to complex acquisition mechanisms like alternating exposures or costly processing that are typical of high dynamic range (HDR) imaging. We propose a transformer-based deep neural network (DNN) to infer the missing HDR details. In an ablation study, we show the importance of using a multiscale DNN and train it with the proper cost function to achieve state-of-the-art quality. To aid the reconstruction of the overexposed areas, our DNN takes a reference frame from the past as an additional input. This leverages the commonly occurring temporal instabilities of autoexposure to our advantage: since well-exposed details in the current frame may be overexposed in the future, we use reinforcement learning to train a reference frame selection DNN that decides whether to adopt the current frame as a future reference. Without resorting to alternating exposures, we obtain therefore a causal, HDR hallucination algorithm with potential application in common video acquisition settings. Our demo video can be found at https://drive.google.com/file/d/1-r12BKImLOYCLUoPzdebnMyNjJ4Rk360/view
The Best Defense is a Good Offense: Adversarial Augmentation against Adversarial Attacks
May 23, 2023



Many defenses against adversarial attacks (\eg robust classifiers, randomization, or image purification) use countermeasures put to work only after the attack has been crafted. We adopt a different perspective to introduce $A^5$ (Adversarial Augmentation Against Adversarial Attacks), a novel framework including the first certified preemptive defense against adversarial attacks. The main idea is to craft a defensive perturbation to guarantee that any attack (up to a given magnitude) towards the input in hand will fail. To this aim, we leverage existing automatic perturbation analysis tools for neural networks. We study the conditions to apply $A^5$ effectively, analyze the importance of the robustness of the to-be-defended classifier, and inspect the appearance of the robustified images. We show effective on-the-fly defensive augmentation with a robustifier network that ignores the ground truth label, and demonstrate the benefits of robustifier and classifier co-training. In our tests, $A^5$ consistently beats state of the art certified defenses on MNIST, CIFAR10, FashionMNIST and Tinyimagenet. We also show how to apply $A^5$ to create certifiably robust physical objects. Our code at https://github.com/NVlabs/A5 allows experimenting on a wide range of scenarios beyond the man-in-the-middle attack tested here, including the case of physical attacks.
Improve Agents without Retraining: Parallel Tree Search with Off-Policy Correction
Jul 04, 2021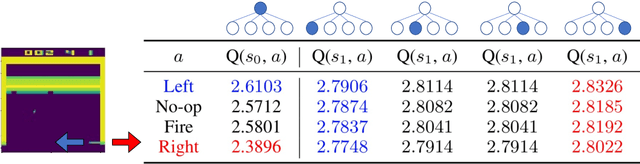
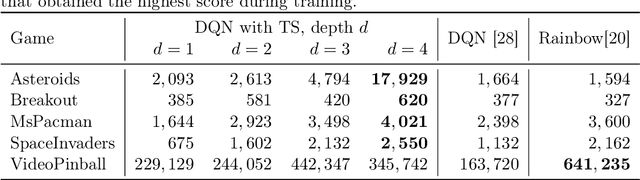
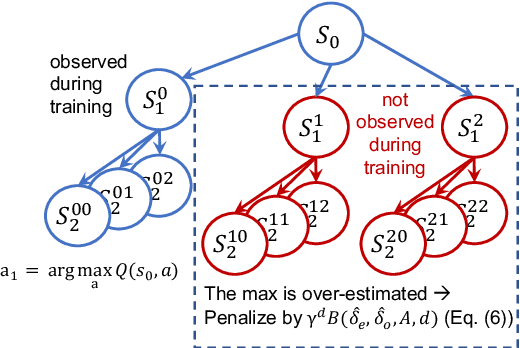
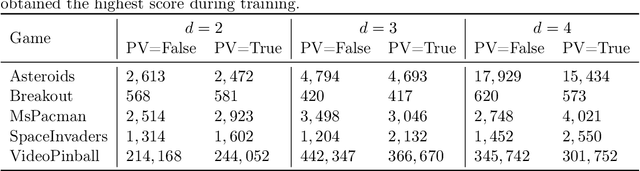
Tree Search (TS) is crucial to some of the most influential successes in reinforcement learning. Here, we tackle two major challenges with TS that limit its usability: \textit{distribution shift} and \textit{scalability}. We first discover and analyze a counter-intuitive phenomenon: action selection through TS and a pre-trained value function often leads to lower performance compared to the original pre-trained agent, even when having access to the exact state and reward in future steps. We show this is due to a distribution shift to areas where value estimates are highly inaccurate and analyze this effect using Extreme Value theory. To overcome this problem, we introduce a novel off-policy correction term that accounts for the mismatch between the pre-trained value and its corresponding TS policy by penalizing under-sampled trajectories. We prove that our correction eliminates the above mismatch and bound the probability of sub-optimal action selection. Our correction significantly improves pre-trained Rainbow agents without any further training, often more than doubling their scores on Atari games. Next, we address the scalability issue given by the computational complexity of exhaustive TS that scales exponentially with the tree depth. We introduce Batch-BFS: a GPU breadth-first search that advances all nodes in each depth of the tree simultaneously. Batch-BFS reduces runtime by two orders of magnitude and, beyond inference, enables also training with TS of depths that were not feasible before. We train DQN agents from scratch using TS and show improvement in several Atari games compared to both the original DQN and the more advanced Rainbow.
Noise-Aware Saliency Prediction for Videos with Incomplete Gaze Data
Apr 16, 2021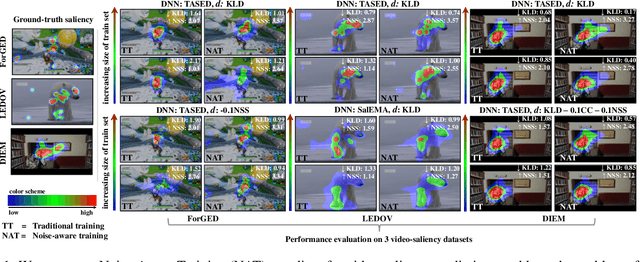

Deep-learning-based algorithms have led to impressive results in visual-saliency prediction, but the impact of noise in training gaze data has been largely overlooked. This issue is especially relevant for videos, where the gaze data tends to be incomplete, and thus noisier, compared to images. Therefore, we propose a noise-aware training (NAT) paradigm for visual-saliency prediction that quantifies the uncertainty arising from gaze data incompleteness and inaccuracy, and accounts for it in training. We demonstrate the advantage of NAT independently of the adopted model architecture, loss function, or training dataset. Given its robustness to the noise in incomplete training datasets, NAT ushers in the possibility of designing gaze datasets with fewer human subjects. We also introduce the first dataset that offers a video-game context for video-saliency research, with rich temporal semantics, and multiple gaze attractors per frame.
Robust Vision-Based Cheat Detection in Competitive Gaming
Mar 27, 2021



Game publishers and anti-cheat companies have been unsuccessful in blocking cheating in online gaming. We propose a novel, vision-based approach that captures the final state of the frame buffer and detects illicit overlays. To this aim, we train and evaluate a DNN detector on a new dataset, collected using two first-person shooter games and three cheating software. We study the advantages and disadvantages of different DNN architectures operating on a local or global scale. We use output confidence analysis to avoid unreliable detections and inform when network retraining is required. In an ablation study, we show how to use Interval Bound Propagation to build a detector that is also resistant to potential adversarial attacks and study its interaction with confidence analysis. Our results show that robust and effective anti-cheating through machine learning is practically feasible and can be used to guarantee fair play in online gaming.
Generating and Characterizing Scenarios for Safety Testing of Autonomous Vehicles
Mar 12, 2021
Extracting interesting scenarios from real-world data as well as generating failure cases is important for the development and testing of autonomous systems. We propose efficient mechanisms to both characterize and generate testing scenarios using a state-of-the-art driving simulator. For any scenario, our method generates a set of possible driving paths and identifies all the possible safe driving trajectories that can be taken starting at different times, to compute metrics that quantify the complexity of the scenario. We use our method to characterize real driving data from the Next Generation Simulation (NGSIM) project, as well as adversarial scenarios generated in simulation. We rank the scenarios by defining metrics based on the complexity of avoiding accidents and provide insights into how the AV could have minimized the probability of incurring an accident. We demonstrate a strong correlation between the proposed metrics and human intuition.
How to Close Sim-Real Gap? Transfer with Segmentation!
May 14, 2020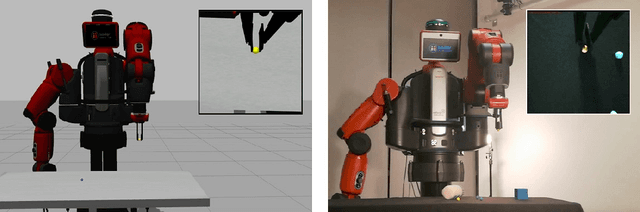
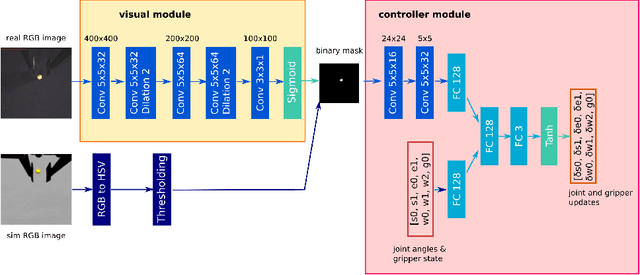
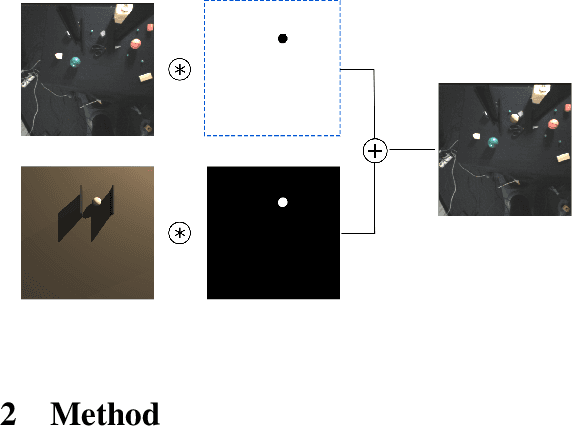
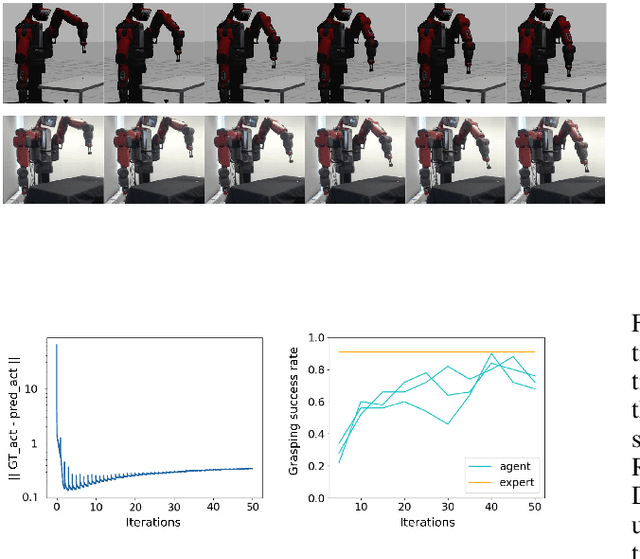
One fundamental difficulty in robotic learning is the sim-real gap problem. In this work, we propose to use segmentation as the interface between perception and control, as a domain-invariant state representation. We identify two sources of sim-real gap, one is dynamics sim-real gap, the other is visual sim-real gap. To close dynamics sim-real gap, we propose to use closed-loop control. For complex task with segmentation mask input, we further propose to learn a closed-loop model-free control policy with deep neural network using imitation learning. To close visual sim-real gap, we propose to learn a perception model in real environment using simulated target plus real background image, without using any real world supervision. We demonstrate this methodology in eye-in-hand grasping task. We train a closed-loop control policy model that taking the segmentation as input using simulation. We show that this control policy is able to transfer from simulation to real environment. The closed-loop control policy is not only robust with respect to discrepancies between the dynamic model of the simulated and real robot, but also is able to generalize to unseen scenarios where the target is moving and even learns to recover from failures. We train the perception segmentation model using training data generated by composing real background images with simulated images of the target. Combining the control policy learned from simulation with the perception model, we achieve an impressive $\bf{88\%}$ success rate in grasping a tiny sphere with a real robot.
GPU-Accelerated Atari Emulation for Reinforcement Learning
Jul 19, 2019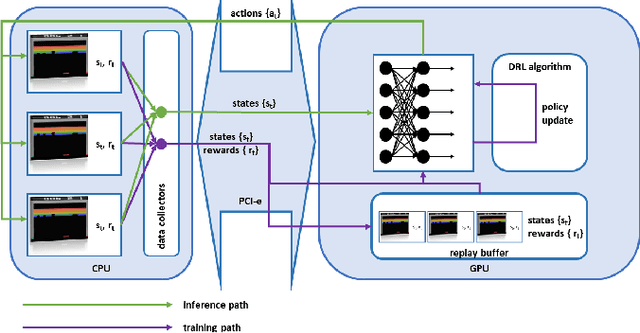
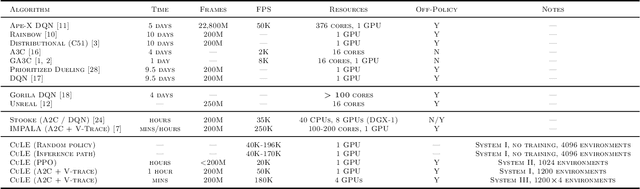

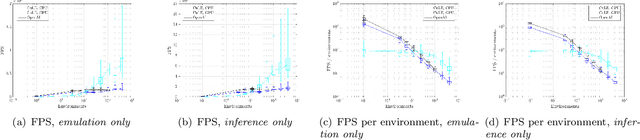
We designed and implemented a CUDA port of the Atari Learning Environment (ALE), a system for developing and evaluating deep reinforcement algorithms using Atari games. Our CUDA Learning Environment (CuLE) overcomes many limitations of existing CPU-based Atari emulators and scales naturally to multi-GPU systems. It leverages the parallelization capability of GPUs to run thousands of Atari games simultaneously; by rendering frames directly on the GPU, CuLE avoids the bottleneck arising from the limited CPU-GPU communication bandwidth. As a result, CuLE is able to generate between 40M and 190M frames per hour using a single GPU, a finding that could be previously achieved only through a cluster of CPUs. We demonstrate the advantages of CuLE by effectively training agents with traditional deep reinforcement learning algorithms and measuring the utilization and throughput of the GPU. Our analysis further highlights the differences in the data generation pattern for emulators running on CPUs or GPUs. CuLE is available at https://github.com/NVLabs/cule .
Importance Estimation for Neural Network Pruning
Jun 25, 2019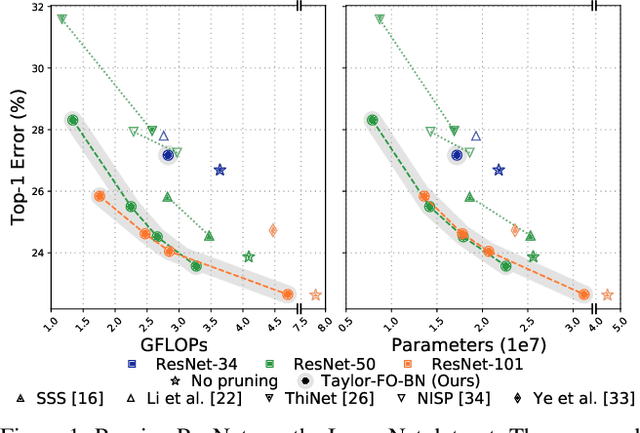
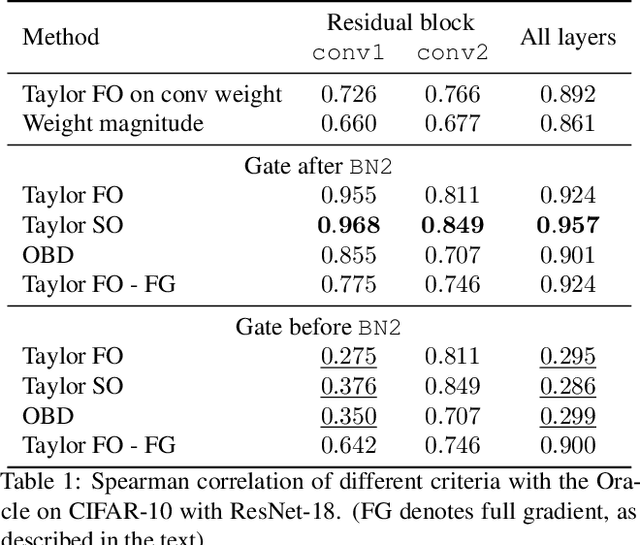
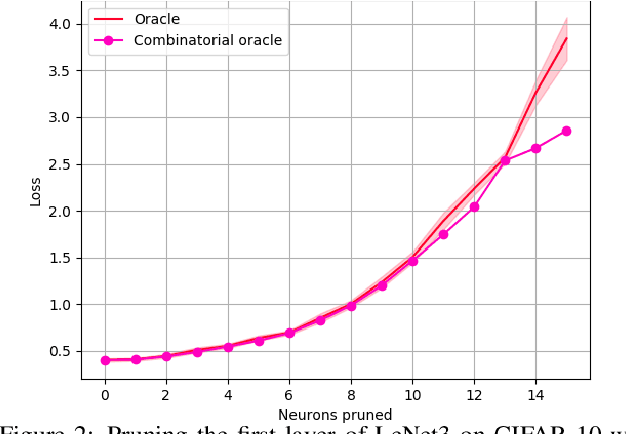
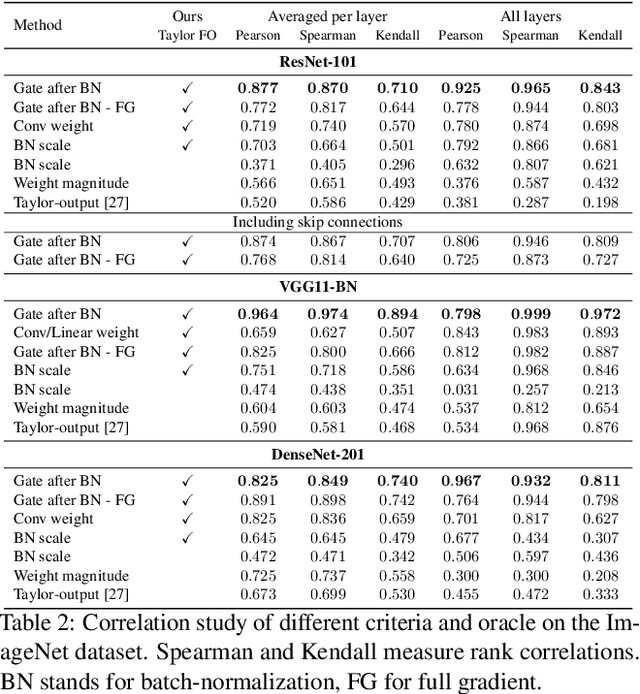
Structural pruning of neural network parameters reduces computation, energy, and memory transfer costs during inference. We propose a novel method that estimates the contribution of a neuron (filter) to the final loss and iteratively removes those with smaller scores. We describe two variations of our method using the first and second-order Taylor expansions to approximate a filter's contribution. Both methods scale consistently across any network layer without requiring per-layer sensitivity analysis and can be applied to any kind of layer, including skip connections. For modern networks trained on ImageNet, we measured experimentally a high (>93%) correlation between the contribution computed by our methods and a reliable estimate of the true importance. Pruning with the proposed methods leads to an improvement over state-of-the-art in terms of accuracy, FLOPs, and parameter reduction. On ResNet-101, we achieve a 40% FLOPS reduction by removing 30% of the parameters, with a loss of 0.02% in the top-1 accuracy on ImageNet. Code is available at https://github.com/NVlabs/Taylor_pruning.