 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrism: Semi-Supervised Multi-View Stereo with Monocular Structure Priors
Dec 08, 2024



The promise of unsupervised multi-view-stereo (MVS) is to leverage large unlabeled datasets, yet current methods underperform when training on difficult data, such as handheld smartphone videos of indoor scenes. Meanwhile, high-quality synthetic datasets are available but MVS networks trained on these datasets fail to generalize to real-world examples. To bridge this gap, we propose a semi-supervised learning framework that allows us to train on real and rendered images jointly, capturing structural priors from synthetic data while ensuring parity with the real-world domain. Central to our framework is a novel set of losses that leverages powerful existing monocular relative-depth estimators trained on the synthetic dataset, transferring the rich structure of this relative depth to the MVS predictions on unlabeled data. Inspired by perceptual image metrics, we compare the MVS and monocular predictions via a deep feature loss and a multi-scale statistical loss. Our full framework, which we call Prism, achieves large quantitative and qualitative improvements over current unsupervised and synthetic-supervised MVS networks. This is a best-case-scenario result, opening the door to using both unlabeled smartphone videos and photorealistic synthetic datasets for training MVS networks.
SiCo: A Size-Controllable Virtual Try-On Approach for Informed Decision-Making
Aug 05, 2024



Virtual try-on (VTO) applications aim to improve the online shopping experience by allowing users to preview garments, before making purchase decisions. However, many VTO tools fail to consider the crucial relationship between a garment's size and the user's body size, often employing a one-size-fits-all approach when visualizing a clothing item. This results in poor size recommendations and purchase decisions leading to increased return rates. To address this limitation, we introduce SiCo, an online VTO system, where users can upload images of themselves and visualize how different sizes of clothing would look on their body to help make better-informed purchase decisions. Our user study shows SiCo's superiority over baseline VTO. The results indicate that our approach significantly enhances user ability to gauge the appearance of outfits on their bodies and boosts their confidence in selecting clothing sizes that match desired goals. Based on our evaluation, we believe our VTO design has the potential to reduce return rates and enhance the online clothes shopping experience. Our code is available at https://github.com/SherryXTChen/SiCo.
AID-AppEAL: Automatic Image Dataset and Algorithm for Content Appeal Enhancement and Assessment Labeling
Jul 08, 2024



We propose Image Content Appeal Assessment (ICAA), a novel metric that quantifies the level of positive interest an image's content generates for viewers, such as the appeal of food in a photograph. This is fundamentally different from traditional Image-Aesthetics Assessment (IAA), which judges an image's artistic quality. While previous studies often confuse the concepts of ``aesthetics'' and ``appeal,'' our work addresses this by being the first to study ICAA explicitly. To do this, we propose a novel system that automates dataset creation and implements algorithms to estimate and boost content appeal. We use our pipeline to generate two large-scale datasets (70K+ images each) in diverse domains (food and room interior design) to train our models, which revealed little correlation between content appeal and aesthetics. Our user study, with more than 76% of participants preferring the appeal-enhanced images, confirms that our appeal ratings accurately reflect user preferences, establishing ICAA as a unique evaluative criterion. Our code and datasets are available at https://github.com/SherryXTChen/AID-Appeal.
TiNO-Edit: Timestep and Noise Optimization for Robust Diffusion-Based Image Editing
Apr 17, 2024Despite many attempts to leverage pre-trained text-to-image models (T2I) like Stable Diffusion (SD) for controllable image editing, producing good predictable results remains a challenge. Previous approaches have focused on either fine-tuning pre-trained T2I models on specific datasets to generate certain kinds of images (e.g., with a specific object or person), or on optimizing the weights, text prompts, and/or learning features for each input image in an attempt to coax the image generator to produce the desired result. However, these approaches all have shortcomings and fail to produce good results in a predictable and controllable manner. To address this problem, we present TiNO-Edit, an SD-based method that focuses on optimizing the noise patterns and diffusion timesteps during editing, something previously unexplored in the literature. With this simple change, we are able to generate results that both better align with the original images and reflect the desired result. Furthermore, we propose a set of new loss functions that operate in the latent domain of SD, greatly speeding up the optimization when compared to prior approaches, which operate in the pixel domain. Our method can be easily applied to variations of SD including Textual Inversion and DreamBooth that encode new concepts and incorporate them into the edited results. We present a host of image-editing capabilities enabled by our approach. Our code is publicly available at https://github.com/SherryXTChen/TiNO-Edit.
Deep Appearance Prefiltering
Nov 08, 2022



Physically based rendering of complex scenes can be prohibitively costly with a potentially unbounded and uneven distribution of complexity across the rendered image. The goal of an ideal level of detail (LoD) method is to make rendering costs independent of the 3D scene complexity, while preserving the appearance of the scene. However, current prefiltering LoD methods are limited in the appearances they can support due to their reliance of approximate models and other heuristics. We propose the first comprehensive multi-scale LoD framework for prefiltering 3D environments with complex geometry and materials (e.g., the Disney BRDF), while maintaining the appearance with respect to the ray-traced reference. Using a multi-scale hierarchy of the scene, we perform a data-driven prefiltering step to obtain an appearance phase function and directional coverage mask at each scale. At the heart of our approach is a novel neural representation that encodes this information into a compact latent form that is easy to decode inside a physically based renderer. Once a scene is baked out, our method requires no original geometry, materials, or textures at render time. We demonstrate that our approach compares favorably to state-of-the-art prefiltering methods and achieves considerable savings in memory for complex scenes.
Interactive Segmentation and Visualization for Tiny Objects in Multi-megapixel Images
Apr 21, 2022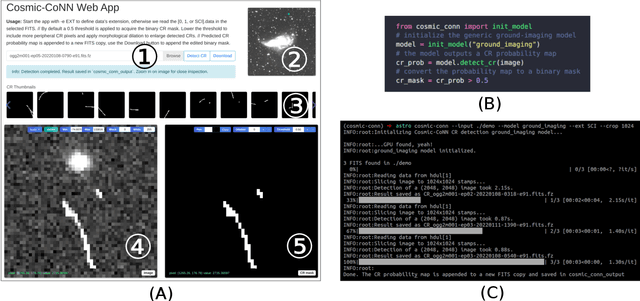
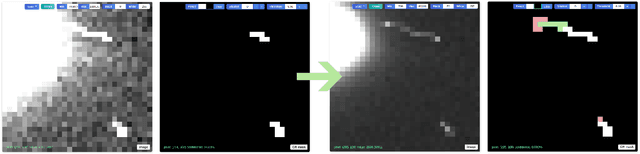
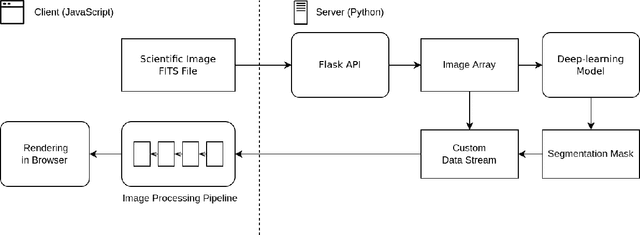
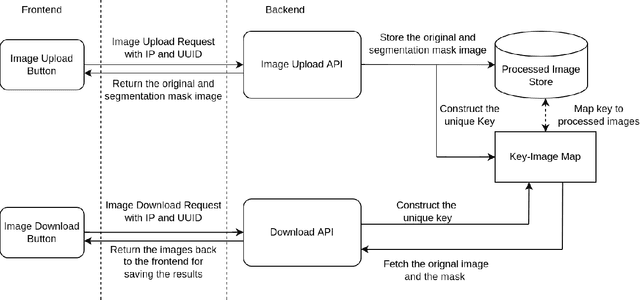
We introduce an interactive image segmentation and visualization framework for identifying, inspecting, and editing tiny objects (just a few pixels wide) in large multi-megapixel high-dynamic-range (HDR) images. Detecting cosmic rays (CRs) in astronomical observations is a cumbersome workflow that requires multiple tools, so we developed an interactive toolkit that unifies model inference, HDR image visualization, segmentation mask inspection and editing into a single graphical user interface. The feature set, initially designed for astronomical data, makes this work a useful research-supporting tool for human-in-the-loop tiny-object segmentation in scientific areas like biomedicine, materials science, remote sensing, etc., as well as computer vision. Our interface features mouse-controlled, synchronized, dual-window visualization of the image and the segmentation mask, a critical feature for locating tiny objects in multi-megapixel images. The browser-based tool can be readily hosted on the web to provide multi-user access and GPU acceleration for any device. The toolkit can also be used as a high-precision annotation tool, or adapted as the frontend for an interactive machine learning framework. Our open-source dataset, CR detection model, and visualization toolkit are available at https://github.com/cy-xu/cosmic-conn.
VoRTX: Volumetric 3D Reconstruction With Transformers for Voxelwise View Selection and Fusion
Dec 01, 2021

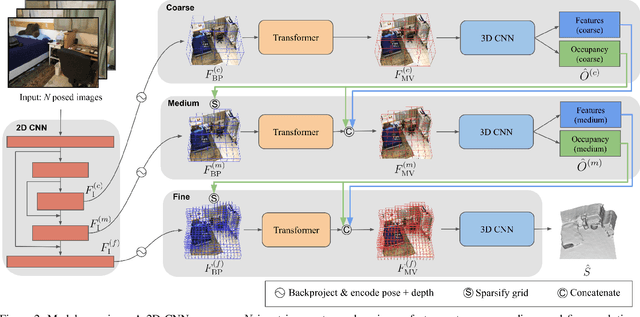

Recent volumetric 3D reconstruction methods can produce very accurate results, with plausible geometry even for unobserved surfaces. However, they face an undesirable trade-off when it comes to multi-view fusion. They can fuse all available view information by global averaging, thus losing fine detail, or they can heuristically cluster views for local fusion, thus restricting their ability to consider all views jointly. Our key insight is that greater detail can be retained without restricting view diversity by learning a view-fusion function conditioned on camera pose and image content. We propose to learn this multi-view fusion using a transformer. To this end, we introduce VoRTX, an end-to-end volumetric 3D reconstruction network using transformers for wide-baseline, multi-view feature fusion. Our model is occlusion-aware, leveraging the transformer architecture to predict an initial, projective scene geometry estimate. This estimate is used to avoid backprojecting image features through surfaces into occluded regions. We train our model on ScanNet and show that it produces better reconstructions than state-of-the-art methods. We also demonstrate generalization without any fine-tuning, outperforming the same state-of-the-art methods on two other datasets, TUM-RGBD and ICL-NUIM.
3DVNet: Multi-View Depth Prediction and Volumetric Refinement
Dec 01, 2021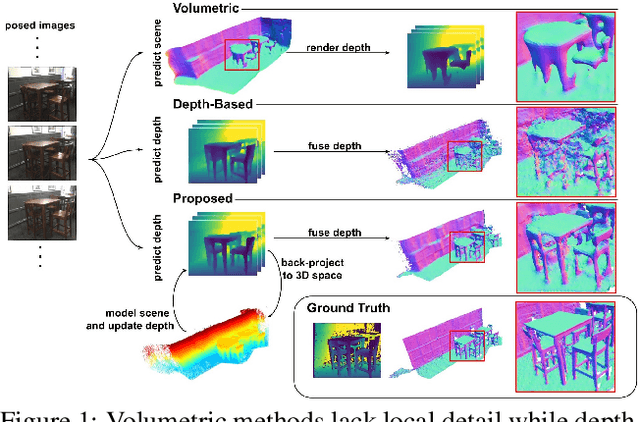

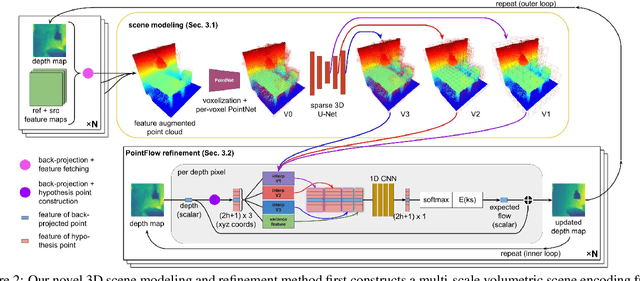

We present 3DVNet, a novel multi-view stereo (MVS) depth-prediction method that combines the advantages of previous depth-based and volumetric MVS approaches. Our key idea is the use of a 3D scene-modeling network that iteratively updates a set of coarse depth predictions, resulting in highly accurate predictions which agree on the underlying scene geometry. Unlike existing depth-prediction techniques, our method uses a volumetric 3D convolutional neural network (CNN) that operates in world space on all depth maps jointly. The network can therefore learn meaningful scene-level priors. Furthermore, unlike existing volumetric MVS techniques, our 3D CNN operates on a feature-augmented point cloud, allowing for effective aggregation of multi-view information and flexible iterative refinement of depth maps. Experimental results show our method exceeds state-of-the-art accuracy in both depth prediction and 3D reconstruction metrics on the ScanNet dataset, as well as a selection of scenes from the TUM-RGBD and ICL-NUIM datasets. This shows that our method is both effective and generalizes to new settings.
Sparse Fusion for Multimodal Transformers
Nov 24, 2021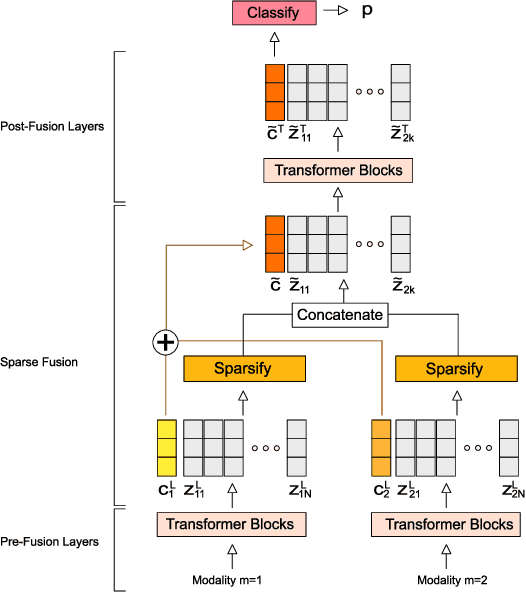
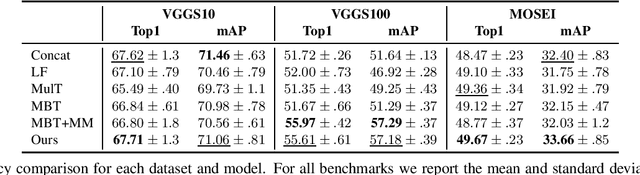
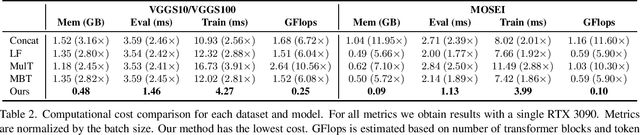
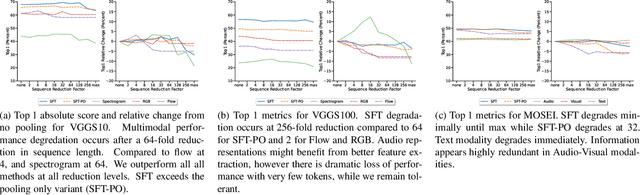
Multimodal classification is a core task in human-centric machine learning. We observe that information is highly complementary across modalities, thus unimodal information can be drastically sparsified prior to multimodal fusion without loss of accuracy. To this end, we present Sparse Fusion Transformers (SFT), a novel multimodal fusion method for transformers that performs comparably to existing state-of-the-art methods while having greatly reduced memory footprint and computation cost. Key to our idea is a sparse-pooling block that reduces unimodal token sets prior to cross-modality modeling. Evaluations are conducted on multiple multimodal benchmark datasets for a wide range of classification tasks. State-of-the-art performance is obtained on multiple benchmarks under similar experiment conditions, while reporting up to six-fold reduction in computational cost and memory requirements. Extensive ablation studies showcase our benefits of combining sparsification and multimodal learning over naive approaches. This paves the way for enabling multimodal learning on low-resource devices.
Cosmic-CoNN: A Cosmic Ray Detection Deep-Learning Framework, Dataset, and Toolkit
Jun 28, 2021
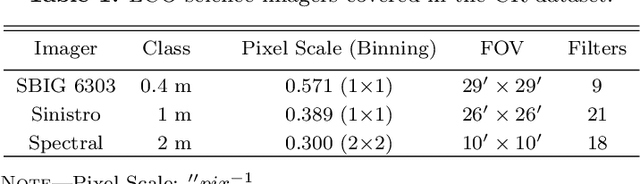
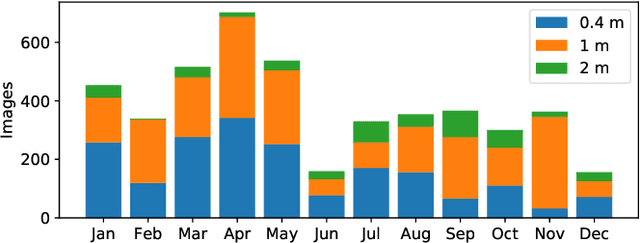
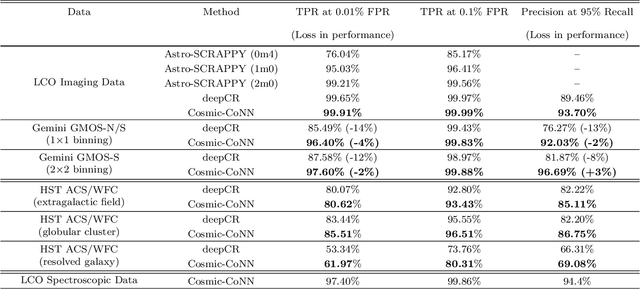
Rejecting cosmic rays (CRs) is essential for scientific interpretation of CCD-captured data, but detecting CRs in single-exposure images has remained challenging. Conventional CR-detection algorithms require tuning multiple parameters experimentally making it hard to automate across different instruments or observation requests. Recent work using deep learning to train CR-detection models has demonstrated promising results. However, instrument-specific models suffer from performance loss on images from ground-based facilities not included in the training data. In this work, we present Cosmic-CoNN, a deep-learning framework designed to produce generic CR-detection models. We build a large, diverse ground-based CR dataset leveraging thousands of images from the Las Cumbres Observatory global telescope network to produce a generic CR-detection model which achieves a 99.91% true-positive detection rate and maintains over 96.40% true-positive rates on unseen data from Gemini GMOS-N/S, with a false-positive rate of 0.01%. Apart from the open-source framework and dataset, we also build a suite of tools including console commands, a web-based application, and Python APIs to make automatic, robust CR detection widely accessible by the community of astronomers.