 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAID-AppEAL: Automatic Image Dataset and Algorithm for Content Appeal Enhancement and Assessment Labeling
Jul 08, 2024



We propose Image Content Appeal Assessment (ICAA), a novel metric that quantifies the level of positive interest an image's content generates for viewers, such as the appeal of food in a photograph. This is fundamentally different from traditional Image-Aesthetics Assessment (IAA), which judges an image's artistic quality. While previous studies often confuse the concepts of ``aesthetics'' and ``appeal,'' our work addresses this by being the first to study ICAA explicitly. To do this, we propose a novel system that automates dataset creation and implements algorithms to estimate and boost content appeal. We use our pipeline to generate two large-scale datasets (70K+ images each) in diverse domains (food and room interior design) to train our models, which revealed little correlation between content appeal and aesthetics. Our user study, with more than 76% of participants preferring the appeal-enhanced images, confirms that our appeal ratings accurately reflect user preferences, establishing ICAA as a unique evaluative criterion. Our code and datasets are available at https://github.com/SherryXTChen/AID-Appeal.
TiNO-Edit: Timestep and Noise Optimization for Robust Diffusion-Based Image Editing
Apr 17, 2024Despite many attempts to leverage pre-trained text-to-image models (T2I) like Stable Diffusion (SD) for controllable image editing, producing good predictable results remains a challenge. Previous approaches have focused on either fine-tuning pre-trained T2I models on specific datasets to generate certain kinds of images (e.g., with a specific object or person), or on optimizing the weights, text prompts, and/or learning features for each input image in an attempt to coax the image generator to produce the desired result. However, these approaches all have shortcomings and fail to produce good results in a predictable and controllable manner. To address this problem, we present TiNO-Edit, an SD-based method that focuses on optimizing the noise patterns and diffusion timesteps during editing, something previously unexplored in the literature. With this simple change, we are able to generate results that both better align with the original images and reflect the desired result. Furthermore, we propose a set of new loss functions that operate in the latent domain of SD, greatly speeding up the optimization when compared to prior approaches, which operate in the pixel domain. Our method can be easily applied to variations of SD including Textual Inversion and DreamBooth that encode new concepts and incorporate them into the edited results. We present a host of image-editing capabilities enabled by our approach. Our code is publicly available at https://github.com/SherryXTChen/TiNO-Edit.
Paying Attention to Multiscale Feature Maps in Multimodal Image Matching
Mar 20, 2021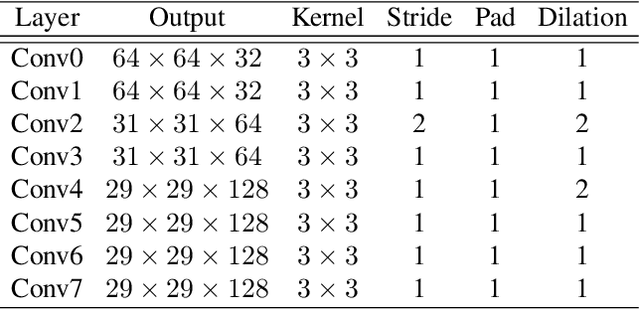



We propose an attention-based approach for multimodal image patch matching using a Transformer encoder attending to the feature maps of a multiscale Siamese CNN. Our encoder is shown to efficiently aggregate multiscale image embeddings while emphasizing task-specific appearance-invariant image cues. We also introduce an attention-residual architecture, using a residual connection bypassing the encoder. This additional learning signal facilitates end-to-end training from scratch. Our approach is experimentally shown to achieve new state-of-the-art accuracy on both multimodal and single modality benchmarks, illustrating its general applicability. To the best of our knowledge, this is the first successful implementation of the Transformer encoder architecture to the multimodal image patch matching task.