 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaying Attention to Multiscale Feature Maps in Multimodal Image Matching
Paper and Code
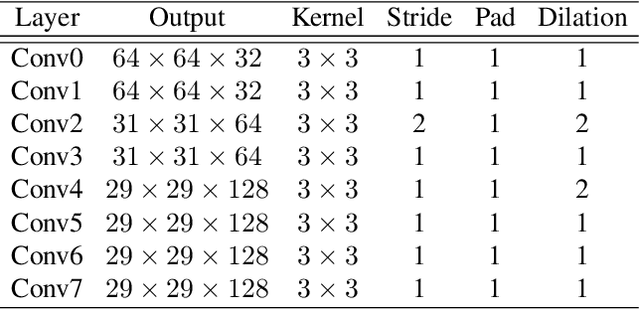



We propose an attention-based approach for multimodal image patch matching using a Transformer encoder attending to the feature maps of a multiscale Siamese CNN. Our encoder is shown to efficiently aggregate multiscale image embeddings while emphasizing task-specific appearance-invariant image cues. We also introduce an attention-residual architecture, using a residual connection bypassing the encoder. This additional learning signal facilitates end-to-end training from scratch. Our approach is experimentally shown to achieve new state-of-the-art accuracy on both multimodal and single modality benchmarks, illustrating its general applicability. To the best of our knowledge, this is the first successful implementation of the Transformer encoder architecture to the multimodal image patch matching task.