 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
Jun 03, 2026Scientific and engineering progress is fundamentally a long-horizon iterative process: proposing changes, running experiments, measuring outcomes, and continuously refining artifacts. Yet existing benchmarks for frontier models primarily evaluate either single-turn responses or short-horizon agent trajectories, failing to capture the challenges of sustained iterative improvement over extended time horizons. To address this gap, we introduce AutoLab, a new benchmark for ultra long-horizon closed-loop optimization. AutoLab consists of 36 realistic, expert-curated tasks spanning four diverse domains: system optimization, puzzle & challenge, model development, and CUDA kernel optimization. Each task begins with a correct but deliberately suboptimal baseline and challenges agents to improve it within a strict wall-clock budget. Evaluating 17 state-of-the-art models reveals the dominant predictor of success is not the quality of an agent's initial attempt, but its persistence in repeatedly benchmarking, editing, and incorporating empirical feedback. While claude-opus-4.6 exhibits strong long-horizon optimization capabilities, most frontier models, including several proprietary ones, either terminate prematurely or exhaust their budgets with minimal progress. These results underscore the importance of time awareness and persistent iteration in autonomous agents. We open-source the full benchmark, evaluation harness, and task artifacts, to accelerate research toward truly capable long-horizon agents.
Visual Aesthetic Benchmark: Can Frontier Models Judge Beauty?
May 12, 2026Multimodal large language models (MLLMs) are now routinely deployed for visual understanding, generation, and curation. A substantial fraction of these applications require an explicit aesthetic judgment. Most existing solutions reduce this judgment to predicting a scalar score for a single image. We first ask whether such scores faithfully capture comparative preference: in a controlled study with eight expert annotators, score-derived rankings align poorly with the same annotators' direct comparisons, while direct ranking yields substantially higher inter-annotator agreement on best- and worst-image labels. Motivated by this finding, we introduce the Visual Aesthetic Benchmark (VAB), which casts aesthetic evaluation as comparative selection over candidate sets with matched subject matter. VAB contains 400 tasks and 1,195 images across fine art, photography, and illustration, with labels derived from the consensus of 10 independent expert judges per task. Evaluating 20 frontier MLLMs and six dedicated visual-quality reward models, we find that the strongest system identifies both the best and the worst image correctly across three random permutations of the candidate order in only 26.5% of tasks, far below the 68.9% achieved by human experts. Fine-tuning a 35B-parameter model on 2,000 expert examples brings its accuracy close to that of a 397B-parameter open-weight model, suggesting that the comparative signal in VAB is transferable. Together, these results expose a clear and measurable gap between current multimodal models and expert aesthetic judgment, and VAB provides the first set-based, expert-grounded testbed on which that gap can be tracked and closed.
Position: Standard Benchmarks Fail -- LLM Agents Present Overlooked Risks for Financial Applications
Feb 21, 2025Current financial LLM agent benchmarks are inadequate. They prioritize task performance while ignoring fundamental safety risks. Threats like hallucinations, temporal misalignment, and adversarial vulnerabilities pose systemic risks in high-stakes financial environments, yet existing evaluation frameworks fail to capture these risks. We take a firm position: traditional benchmarks are insufficient to ensure the reliability of LLM agents in finance. To address this, we analyze existing financial LLM agent benchmarks, finding safety gaps and introducing ten risk-aware evaluation metrics. Through an empirical evaluation of both API-based and open-weight LLM agents, we reveal hidden vulnerabilities that remain undetected by conventional assessments. To move the field forward, we propose the Safety-Aware Evaluation Agent (SAEA), grounded in a three-level evaluation framework that assesses agents at the model level (intrinsic capabilities), workflow level (multi-step process reliability), and system level (integration robustness). Our findings highlight the urgent need to redefine LLM agent evaluation standards by shifting the focus from raw performance to safety, robustness, and real world resilience.
Engaging with AI: How Interface Design Shapes Human-AI Collaboration in High-Stakes Decision-Making
Jan 28, 2025As reliance on AI systems for decision-making grows, it becomes critical to ensure that human users can appropriately balance trust in AI suggestions with their own judgment, especially in high-stakes domains like healthcare. However, human + AI teams have been shown to perform worse than AI alone, with evidence indicating automation bias as the reason for poorer performance, particularly because humans tend to follow AI's recommendations even when they are incorrect. In many existing human + AI systems, decision-making support is typically provided in the form of text explanations (XAI) to help users understand the AI's reasoning. Since human decision-making often relies on System 1 thinking, users may ignore or insufficiently engage with the explanations, leading to poor decision-making. Previous research suggests that there is a need for new approaches that encourage users to engage with the explanations and one proposed method is the use of cognitive forcing functions (CFFs). In this work, we examine how various decision-support mechanisms impact user engagement, trust, and human-AI collaborative task performance in a diabetes management decision-making scenario. In a controlled experiment with 108 participants, we evaluated the effects of six decision-support mechanisms split into two categories of explanations (text, visual) and four CFFs. Our findings reveal that mechanisms like AI confidence levels, text explanations, and performance visualizations enhanced human-AI collaborative task performance, and improved trust when AI reasoning clues were provided. Mechanisms like human feedback and AI-driven questions encouraged deeper reflection but often reduced task performance by increasing cognitive effort, which in turn affected trust. Simple mechanisms like visual explanations had little effect on trust, highlighting the importance of striking a balance in CFF and XAI design.
Everyday AR through AI-in-the-Loop
Dec 17, 2024
This workshop brings together experts and practitioners from augmented reality (AR) and artificial intelligence (AI) to shape the future of AI-in-the-loop everyday AR experiences. With recent advancements in both AR hardware and AI capabilities, we envision that everyday AR -- always-available and seamlessly integrated into users' daily environments -- is becoming increasingly feasible. This workshop will explore how AI can drive such everyday AR experiences. We discuss a range of topics, including adaptive and context-aware AR, generative AR content creation, always-on AI assistants, AI-driven accessible design, and real-world-oriented AI agents. Our goal is to identify the opportunities and challenges in AI-enabled AR, focusing on creating novel AR experiences that seamlessly blend the digital and physical worlds. Through the workshop, we aim to foster collaboration, inspire future research, and build a community to advance the research field of AI-enhanced AR.
LocoVR: Multiuser Indoor Locomotion Dataset in Virtual Reality
Oct 09, 2024Understanding human locomotion is crucial for AI agents such as robots, particularly in complex indoor home environments. Modeling human trajectories in these spaces requires insight into how individuals maneuver around physical obstacles and manage social navigation dynamics. These dynamics include subtle behaviors influenced by proxemics - the social use of space, such as stepping aside to allow others to pass or choosing longer routes to avoid collisions. Previous research has developed datasets of human motion in indoor scenes, but these are often limited in scale and lack the nuanced social navigation dynamics common in home environments. To address this, we present LocoVR, a dataset of 7000+ two-person trajectories captured in virtual reality from over 130 different indoor home environments. LocoVR provides full body pose data and precise spatial information, along with rich examples of socially-motivated movement behaviors. For example, the dataset captures instances of individuals navigating around each other in narrow spaces, adjusting paths to respect personal boundaries in living areas, and coordinating movements in high-traffic zones like entryways and kitchens. Our evaluation shows that LocoVR significantly enhances model performance in three practical indoor tasks utilizing human trajectories, and demonstrates predicting socially-aware navigation patterns in home environments.
SiCo: A Size-Controllable Virtual Try-On Approach for Informed Decision-Making
Aug 05, 2024



Virtual try-on (VTO) applications aim to improve the online shopping experience by allowing users to preview garments, before making purchase decisions. However, many VTO tools fail to consider the crucial relationship between a garment's size and the user's body size, often employing a one-size-fits-all approach when visualizing a clothing item. This results in poor size recommendations and purchase decisions leading to increased return rates. To address this limitation, we introduce SiCo, an online VTO system, where users can upload images of themselves and visualize how different sizes of clothing would look on their body to help make better-informed purchase decisions. Our user study shows SiCo's superiority over baseline VTO. The results indicate that our approach significantly enhances user ability to gauge the appearance of outfits on their bodies and boosts their confidence in selecting clothing sizes that match desired goals. Based on our evaluation, we believe our VTO design has the potential to reduce return rates and enhance the online clothes shopping experience. Our code is available at https://github.com/SherryXTChen/SiCo.
AID-AppEAL: Automatic Image Dataset and Algorithm for Content Appeal Enhancement and Assessment Labeling
Jul 08, 2024



We propose Image Content Appeal Assessment (ICAA), a novel metric that quantifies the level of positive interest an image's content generates for viewers, such as the appeal of food in a photograph. This is fundamentally different from traditional Image-Aesthetics Assessment (IAA), which judges an image's artistic quality. While previous studies often confuse the concepts of ``aesthetics'' and ``appeal,'' our work addresses this by being the first to study ICAA explicitly. To do this, we propose a novel system that automates dataset creation and implements algorithms to estimate and boost content appeal. We use our pipeline to generate two large-scale datasets (70K+ images each) in diverse domains (food and room interior design) to train our models, which revealed little correlation between content appeal and aesthetics. Our user study, with more than 76% of participants preferring the appeal-enhanced images, confirms that our appeal ratings accurately reflect user preferences, establishing ICAA as a unique evaluative criterion. Our code and datasets are available at https://github.com/SherryXTChen/AID-Appeal.
GraphEval2000: Benchmarking and Improving Large Language Models on Graph Datasets
Jun 23, 2024


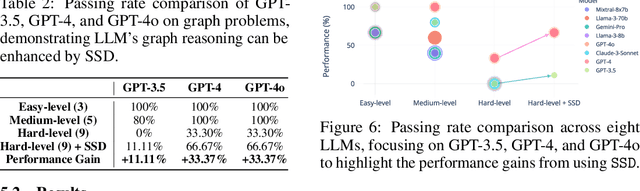
Large language models (LLMs) have achieved remarkable success in natural language processing (NLP), demonstrating significant capabilities in processing and understanding text data. However, recent studies have identified limitations in LLMs' ability to reason about graph-structured data. To address this gap, we introduce GraphEval2000, the first comprehensive graph dataset, comprising 40 graph data structure problems along with 2000 test cases. Additionally, we introduce an evaluation framework based on GraphEval2000, designed to assess the graph reasoning abilities of LLMs through coding challenges. Our dataset categorizes test cases into four primary and four sub-categories, ensuring a comprehensive evaluation. We evaluate eight popular LLMs on GraphEval2000, revealing that LLMs exhibit a better understanding of directed graphs compared to undirected ones. While private LLMs consistently outperform open-source models, the performance gap is narrowing. Furthermore, to improve the usability of our evaluation framework, we propose Structured Symbolic Decomposition (SSD), an instruction-based method designed to enhance LLM performance on GraphEval2000. Results show that SSD improves the performance of GPT-3.5, GPT-4, and GPT-4o on complex graph problems, with an increase of 11.11\%, 33.37\%, and 33.37\%, respectively.
Artificial Leviathan: Exploring Social Evolution of LLM Agents Through the Lens of Hobbesian Social Contract Theory
Jun 20, 2024



The emergence of Large Language Models (LLMs) and advancements in Artificial Intelligence (AI) offer an opportunity for computational social science research at scale. Building upon prior explorations of LLM agent design, our work introduces a simulated agent society where complex social relationships dynamically form and evolve over time. Agents are imbued with psychological drives and placed in a sandbox survival environment. We conduct an evaluation of the agent society through the lens of Thomas Hobbes's seminal Social Contract Theory (SCT). We analyze whether, as the theory postulates, agents seek to escape a brutish "state of nature" by surrendering rights to an absolute sovereign in exchange for order and security. Our experiments unveil an alignment: Initially, agents engage in unrestrained conflict, mirroring Hobbes's depiction of the state of nature. However, as the simulation progresses, social contracts emerge, leading to the authorization of an absolute sovereign and the establishment of a peaceful commonwealth founded on mutual cooperation. This congruence between our LLM agent society's evolutionary trajectory and Hobbes's theoretical account indicates LLMs' capability to model intricate social dynamics and potentially replicate forces that shape human societies. By enabling such insights into group behavior and emergent societal phenomena, LLM-driven multi-agent simulations, while unable to simulate all the nuances of human behavior, may hold potential for advancing our understanding of social structures, group dynamics, and complex human systems.