 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphEval2000: Benchmarking and Improving Large Language Models on Graph Datasets
Jun 23, 2024


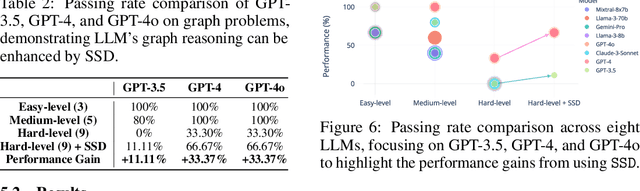
Large language models (LLMs) have achieved remarkable success in natural language processing (NLP), demonstrating significant capabilities in processing and understanding text data. However, recent studies have identified limitations in LLMs' ability to reason about graph-structured data. To address this gap, we introduce GraphEval2000, the first comprehensive graph dataset, comprising 40 graph data structure problems along with 2000 test cases. Additionally, we introduce an evaluation framework based on GraphEval2000, designed to assess the graph reasoning abilities of LLMs through coding challenges. Our dataset categorizes test cases into four primary and four sub-categories, ensuring a comprehensive evaluation. We evaluate eight popular LLMs on GraphEval2000, revealing that LLMs exhibit a better understanding of directed graphs compared to undirected ones. While private LLMs consistently outperform open-source models, the performance gap is narrowing. Furthermore, to improve the usability of our evaluation framework, we propose Structured Symbolic Decomposition (SSD), an instruction-based method designed to enhance LLM performance on GraphEval2000. Results show that SSD improves the performance of GPT-3.5, GPT-4, and GPT-4o on complex graph problems, with an increase of 11.11\%, 33.37\%, and 33.37\%, respectively.