 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Social Intelligence Risks in Generative Multi-Agent Systems
Mar 29, 2026Multi-agent systems composed of large generative models are rapidly moving from laboratory prototypes to real-world deployments, where they jointly plan, negotiate, and allocate shared resources to solve complex tasks. While such systems promise unprecedented scalability and autonomy, their collective interaction also gives rise to failure modes that cannot be reduced to individual agents. Understanding these emergent risks is therefore critical. Here, we present a pioneer study of such emergent multi-agent risk in workflows that involve competition over shared resources (e.g., computing resources or market share), sequential handoff collaboration (where downstream agents see only predecessor outputs), collective decision aggregation, and others. Across these settings, we observe that such group behaviors arise frequently across repeated trials and a wide range of interaction conditions, rather than as rare or pathological cases. In particular, phenomena such as collusion-like coordination and conformity emerge with non-trivial frequency under realistic resource constraints, communication protocols, and role assignments, mirroring well-known pathologies in human societies despite no explicit instruction. Moreover, these risks cannot be prevented by existing agent-level safeguards alone. These findings expose the dark side of intelligent multi-agent systems: a social intelligence risk where agent collectives, despite no instruction to do so, spontaneously reproduce familiar failure patterns from human societies.
Position: Standard Benchmarks Fail -- LLM Agents Present Overlooked Risks for Financial Applications
Feb 21, 2025Current financial LLM agent benchmarks are inadequate. They prioritize task performance while ignoring fundamental safety risks. Threats like hallucinations, temporal misalignment, and adversarial vulnerabilities pose systemic risks in high-stakes financial environments, yet existing evaluation frameworks fail to capture these risks. We take a firm position: traditional benchmarks are insufficient to ensure the reliability of LLM agents in finance. To address this, we analyze existing financial LLM agent benchmarks, finding safety gaps and introducing ten risk-aware evaluation metrics. Through an empirical evaluation of both API-based and open-weight LLM agents, we reveal hidden vulnerabilities that remain undetected by conventional assessments. To move the field forward, we propose the Safety-Aware Evaluation Agent (SAEA), grounded in a three-level evaluation framework that assesses agents at the model level (intrinsic capabilities), workflow level (multi-step process reliability), and system level (integration robustness). Our findings highlight the urgent need to redefine LLM agent evaluation standards by shifting the focus from raw performance to safety, robustness, and real world resilience.
Engaging with AI: How Interface Design Shapes Human-AI Collaboration in High-Stakes Decision-Making
Jan 28, 2025As reliance on AI systems for decision-making grows, it becomes critical to ensure that human users can appropriately balance trust in AI suggestions with their own judgment, especially in high-stakes domains like healthcare. However, human + AI teams have been shown to perform worse than AI alone, with evidence indicating automation bias as the reason for poorer performance, particularly because humans tend to follow AI's recommendations even when they are incorrect. In many existing human + AI systems, decision-making support is typically provided in the form of text explanations (XAI) to help users understand the AI's reasoning. Since human decision-making often relies on System 1 thinking, users may ignore or insufficiently engage with the explanations, leading to poor decision-making. Previous research suggests that there is a need for new approaches that encourage users to engage with the explanations and one proposed method is the use of cognitive forcing functions (CFFs). In this work, we examine how various decision-support mechanisms impact user engagement, trust, and human-AI collaborative task performance in a diabetes management decision-making scenario. In a controlled experiment with 108 participants, we evaluated the effects of six decision-support mechanisms split into two categories of explanations (text, visual) and four CFFs. Our findings reveal that mechanisms like AI confidence levels, text explanations, and performance visualizations enhanced human-AI collaborative task performance, and improved trust when AI reasoning clues were provided. Mechanisms like human feedback and AI-driven questions encouraged deeper reflection but often reduced task performance by increasing cognitive effort, which in turn affected trust. Simple mechanisms like visual explanations had little effect on trust, highlighting the importance of striking a balance in CFF and XAI design.
State Chrono Representation for Enhancing Generalization in Reinforcement Learning
Nov 09, 2024



In reinforcement learning with image-based inputs, it is crucial to establish a robust and generalizable state representation. Recent advancements in metric learning, such as deep bisimulation metric approaches, have shown promising results in learning structured low-dimensional representation space from pixel observations, where the distance between states is measured based on task-relevant features. However, these approaches face challenges in demanding generalization tasks and scenarios with non-informative rewards. This is because they fail to capture sufficient long-term information in the learned representations. To address these challenges, we propose a novel State Chrono Representation (SCR) approach. SCR augments state metric-based representations by incorporating extensive temporal information into the update step of bisimulation metric learning. It learns state distances within a temporal framework that considers both future dynamics and cumulative rewards over current and long-term future states. Our learning strategy effectively incorporates future behavioral information into the representation space without introducing a significant number of additional parameters for modeling dynamics. Extensive experiments conducted in DeepMind Control and Meta-World environments demonstrate that SCR achieves better performance comparing to other recent metric-based methods in demanding generalization tasks. The codes of SCR are available in https://github.com/jianda-chen/SCR.
GraphEval2000: Benchmarking and Improving Large Language Models on Graph Datasets
Jun 23, 2024


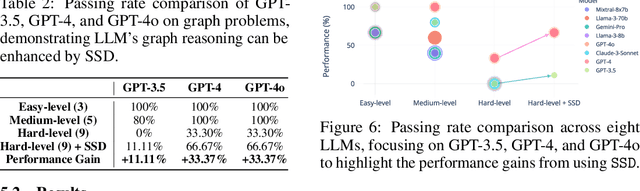
Large language models (LLMs) have achieved remarkable success in natural language processing (NLP), demonstrating significant capabilities in processing and understanding text data. However, recent studies have identified limitations in LLMs' ability to reason about graph-structured data. To address this gap, we introduce GraphEval2000, the first comprehensive graph dataset, comprising 40 graph data structure problems along with 2000 test cases. Additionally, we introduce an evaluation framework based on GraphEval2000, designed to assess the graph reasoning abilities of LLMs through coding challenges. Our dataset categorizes test cases into four primary and four sub-categories, ensuring a comprehensive evaluation. We evaluate eight popular LLMs on GraphEval2000, revealing that LLMs exhibit a better understanding of directed graphs compared to undirected ones. While private LLMs consistently outperform open-source models, the performance gap is narrowing. Furthermore, to improve the usability of our evaluation framework, we propose Structured Symbolic Decomposition (SSD), an instruction-based method designed to enhance LLM performance on GraphEval2000. Results show that SSD improves the performance of GPT-3.5, GPT-4, and GPT-4o on complex graph problems, with an increase of 11.11\%, 33.37\%, and 33.37\%, respectively.
XplainLLM: A QA Explanation Dataset for Understanding LLM Decision-Making
Nov 15, 2023Large Language Models (LLMs) have recently made impressive strides in natural language understanding tasks. Despite their remarkable performance, understanding their decision-making process remains a big challenge. In this paper, we look into bringing some transparency to this process by introducing a new explanation dataset for question answering (QA) tasks that integrates knowledge graphs (KGs) in a novel way. Our dataset includes 12,102 question-answer-explanation (QAE) triples. Each explanation in the dataset links the LLM's reasoning to entities and relations in the KGs. The explanation component includes a why-choose explanation, a why-not-choose explanation, and a set of reason-elements that underlie the LLM's decision. We leverage KGs and graph attention networks (GAT) to find the reason-elements and transform them into why-choose and why-not-choose explanations that are comprehensible to humans. Through quantitative and qualitative evaluations, we demonstrate the potential of our dataset to improve the in-context learning of LLMs, and enhance their interpretability and explainability. Our work contributes to the field of explainable AI by enabling a deeper understanding of the LLMs decision-making process to make them more transparent and thereby, potentially more reliable, to researchers and practitioners alike. Our dataset is available at: https://github.com/chen-zichen/XplainLLM_dataset.git
LMExplainer: a Knowledge-Enhanced Explainer for Language Models
Mar 29, 2023



Large language models (LMs) such as GPT-4 are very powerful and can process different kinds of natural language processing (NLP) tasks. However, it can be difficult to interpret the results due to the multi-layer nonlinear model structure and millions of parameters. Lack of understanding of how the model works can make the model unreliable and dangerous for everyday users in real-world scenarios. Most recent works exploit the weights of attention to provide explanations for model predictions. However, pure attention-based explanation is unable to support the growing complexity of the models, and cannot reason about their decision-making processes. Thus, we propose LMExplainer, a knowledge-enhanced interpretation module for language models that can provide human-understandable explanations. We use a knowledge graph (KG) and a graph attention neural network to extract the key decision signals of the LM. We further explore whether interpretation can also help AI understand the task better. Our experimental results show that LMExplainer outperforms existing LM+KG methods on CommonsenseQA and OpenBookQA. We also compare the explanation results with generated explanation methods and human-annotated results. The comparison shows our method can provide more comprehensive and clearer explanations. LMExplainer demonstrates the potential to enhance model performance and furnish explanations for the reasoning processes of models in natural language.
Efficient Training of Large-scale Industrial Fault Diagnostic Models through Federated Opportunistic Block Dropout
Feb 22, 2023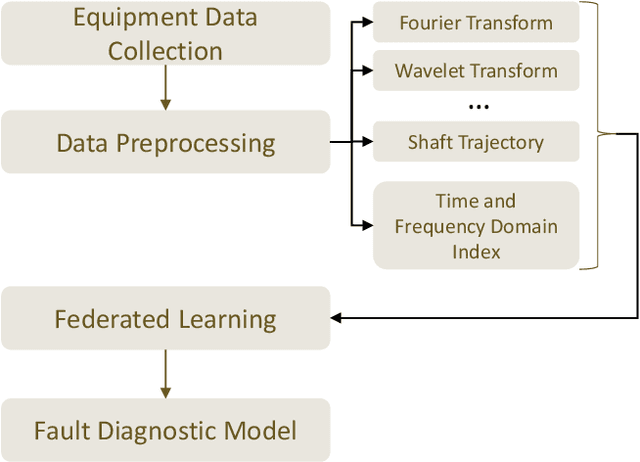
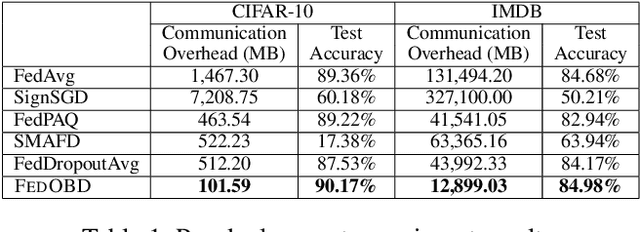


Artificial intelligence (AI)-empowered industrial fault diagnostics is important in ensuring the safe operation of industrial applications. Since complex industrial systems often involve multiple industrial plants (possibly belonging to different companies or subsidiaries) with sensitive data collected and stored in a distributed manner, collaborative fault diagnostic model training often needs to leverage federated learning (FL). As the scale of the industrial fault diagnostic models are often large and communication channels in such systems are often not exclusively used for FL model training, existing deployed FL model training frameworks cannot train such models efficiently across multiple institutions. In this paper, we report our experience developing and deploying the Federated Opportunistic Block Dropout (FEDOBD) approach for industrial fault diagnostic model training. By decomposing large-scale models into semantic blocks and enabling FL participants to opportunistically upload selected important blocks in a quantized manner, it significantly reduces the communication overhead while maintaining model performance. Since its deployment in ENN Group in February 2022, FEDOBD has served two coal chemical plants across two cities in China to build industrial fault prediction models. It helped the company reduce the training communication overhead by over 70% compared to its previous AI Engine, while maintaining model performance at over 85% test F1 score. To our knowledge, it is the first successfully deployed dropout-based FL approach.
FedOBD: Opportunistic Block Dropout for Efficiently Training Large-scale Neural Networks through Federated Learning
Aug 10, 2022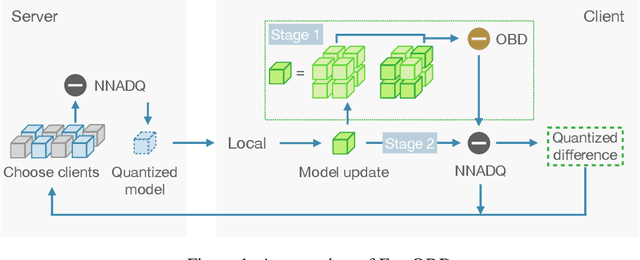
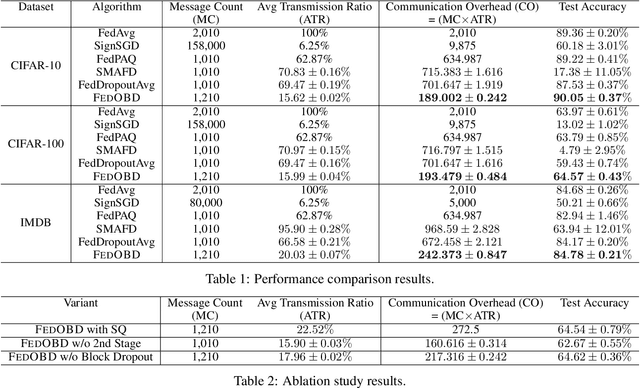
Large-scale neural networks possess considerable expressive power. They are well-suited for complex learning tasks in industrial applications. However, large-scale models pose significant challenges for training under the current Federated Learning (FL) paradigm. Existing approaches for efficient FL training often leverage model parameter dropout. However, manipulating individual model parameters is not only inefficient in meaningfully reducing the communication overhead when training large-scale FL models, but may also be detrimental to the scaling efforts and model performance as shown by recent research. To address these issues, we propose the Federated Opportunistic Block Dropout (FedOBD) approach. The key novelty is that it decomposes large-scale models into semantic blocks so that FL participants can opportunistically upload quantized blocks, which are deemed to be significant towards training the model, to the FL server for aggregation. Extensive experiments evaluating FedOBD against five state-of-the-art approaches based on multiple real-world datasets show that it reduces the overall communication overhead by more than 70% compared to the best performing baseline approach, while achieving the highest test accuracy. To the best of our knowledge, FedOBD is the first approach to perform dropout on FL models at the block level rather than at the individual parameter level.
Towards Toxic and Narcotic Medication Detection with Rotated Object Detector
Oct 19, 2021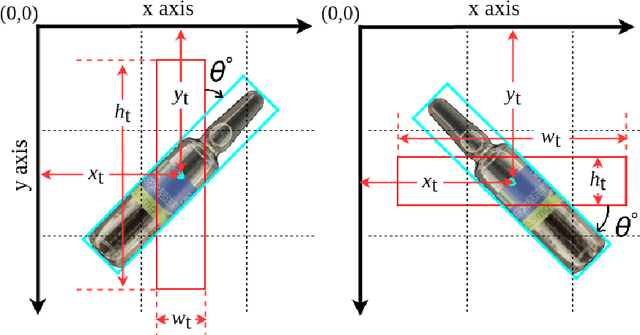

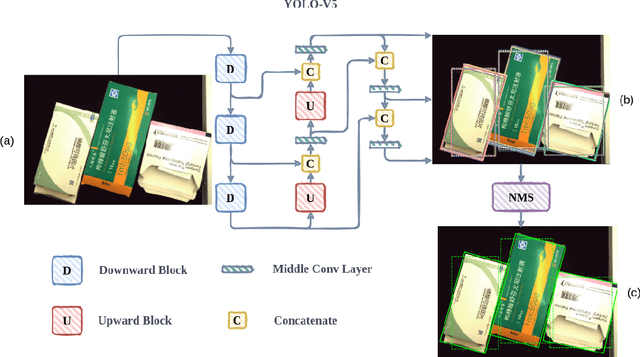
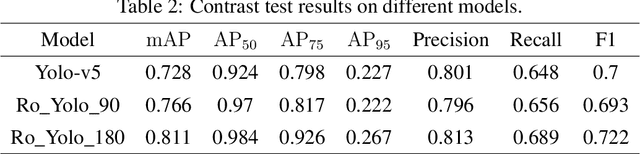
Recent years have witnessed the advancement of deep learning vision technologies and applications in the medical industry. Intelligent devices for special medication management are in great need of, which requires more precise detection algorithms to identify the specifications and locations. In this work, YOLO (You only look once) based object detectors are tailored for toxic and narcotic medications detection tasks. Specifically, a more flexible annotation with rotated degree ranging from $0^\circ$ to $90^\circ$ and a mask-mapping-based non-maximum suppression method are proposed to achieve a feasible and efficient medication detector aiming at arbitrarily oriented bounding boxes. Extensive experiments demonstrate that the rotated YOLO detectors are more suitable for identifying densely arranged drugs. The best shot mean average precision of the proposed network reaches 0.811 while the inference time is less than 300ms.