 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Verification Dilemma: Experience-Driven Suppression of Overused Checking in LLM Reasoning
Feb 03, 2026Large Reasoning Models (LRMs) achieve strong performance by generating long reasoning traces with reflection. Through a large-scale empirical analysis, we find that a substantial fraction of reflective steps consist of self-verification (recheck) that repeatedly confirm intermediate results. These rechecks occur frequently across models and benchmarks, yet the vast majority are confirmatory rather than corrective, rarely identifying errors and altering reasoning outcomes. This reveals a mismatch between how often self-verification is activated and how often it is actually useful. Motivated by this, we propose a novel, experience-driven test-time framework that reduces the overused verification. Our method detects the activation of recheck behavior, consults an offline experience pool of past verification outcomes, and estimates whether a recheck is likely unnecessary via efficient retrieval. When historical experience suggests unnecessary, a suppression signal redirects the model to proceed. Across multiple model and benchmarks, our approach reduces token usage up to 20.3% while maintaining the accuracy, and in some datasets even yields accuracy improvements.
MermaidFlow: Redefining Agentic Workflow Generation via Safety-Constrained Evolutionary Programming
May 29, 2025Despite the promise of autonomous agentic reasoning, existing workflow generation methods frequently produce fragile, unexecutable plans due to unconstrained LLM-driven construction. We introduce MermaidFlow, a framework that redefines the agentic search space through safety-constrained graph evolution. At its core, MermaidFlow represent workflows as a verifiable intermediate representation using Mermaid, a structured and human-interpretable graph language. We formulate domain-aware evolutionary operators, i.e., crossover, mutation, insertion, and deletion, to preserve semantic correctness while promoting structural diversity, enabling efficient exploration of a high-quality, statically verifiable workflow space. Without modifying task settings or evaluation protocols, MermaidFlow achieves consistent improvements in success rates and faster convergence to executable plans on the agent reasoning benchmark. The experimental results demonstrate that safety-constrained graph evolution offers a scalable, modular foundation for robust and interpretable agentic reasoning systems.
Reinforcing Compositional Retrieval: Retrieving Step-by-Step for Composing Informative Contexts
Apr 15, 2025
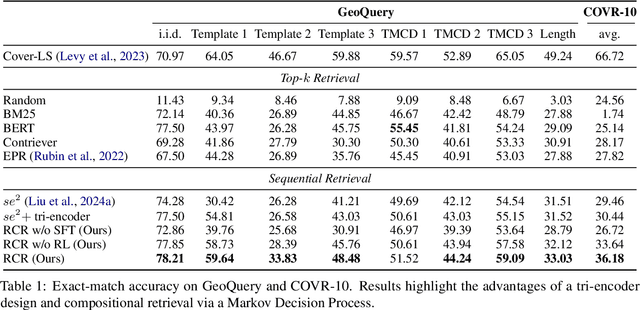
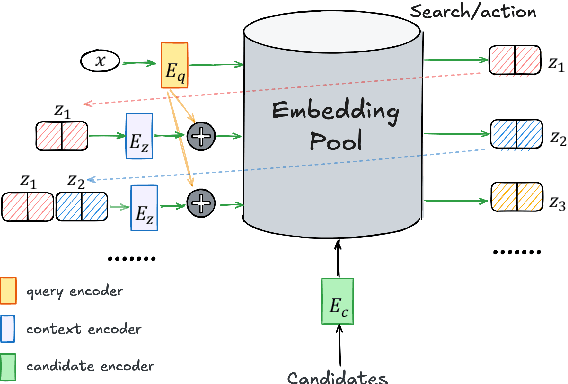
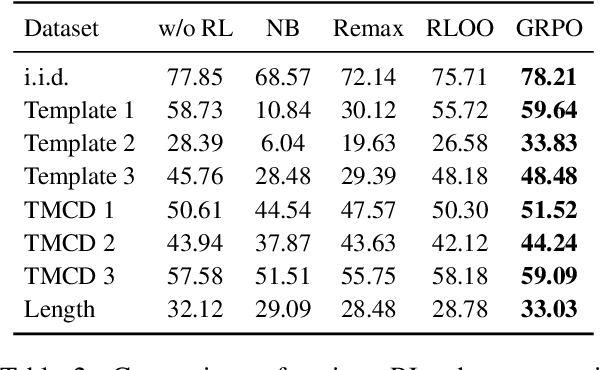
Large Language Models (LLMs) have demonstrated remarkable capabilities across numerous tasks, yet they often rely on external context to handle complex tasks. While retrieval-augmented frameworks traditionally focus on selecting top-ranked documents in a single pass, many real-world scenarios demand compositional retrieval, where multiple sources must be combined in a coordinated manner. In this work, we propose a tri-encoder sequential retriever that models this process as a Markov Decision Process (MDP), decomposing the probability of retrieving a set of elements into a sequence of conditional probabilities and allowing each retrieval step to be conditioned on previously selected examples. We train the retriever in two stages: first, we efficiently construct supervised sequential data for initial policy training; we then refine the policy to align with the LLM's preferences using a reward grounded in the structural correspondence of generated programs. Experimental results show that our method consistently and significantly outperforms baselines, underscoring the importance of explicitly modeling inter-example dependencies. These findings highlight the potential of compositional retrieval for tasks requiring multiple pieces of evidence or examples.
Mastering Continual Reinforcement Learning through Fine-Grained Sparse Network Allocation and Dormant Neuron Exploration
Mar 07, 2025



Continual Reinforcement Learning (CRL) is essential for developing agents that can learn, adapt, and accumulate knowledge over time. However, a fundamental challenge persists as agents must strike a delicate balance between plasticity, which enables rapid skill acquisition, and stability, which ensures long-term knowledge retention while preventing catastrophic forgetting. In this paper, we introduce SSDE, a novel structure-based approach that enhances plasticity through a fine-grained allocation strategy with Structured Sparsity and Dormant-guided Exploration. SSDE decomposes the parameter space into forward-transfer (frozen) parameters and task-specific (trainable) parameters. Crucially, these parameters are allocated by an efficient co-allocation scheme under sparse coding, ensuring sufficient trainable capacity for new tasks while promoting efficient forward transfer through frozen parameters. However, structure-based methods often suffer from rigidity due to the accumulation of non-trainable parameters, limiting exploration and adaptability. To address this, we further introduce a sensitivity-guided neuron reactivation mechanism that systematically identifies and resets dormant neurons, which exhibit minimal influence in the sparse policy network during inference. This approach effectively enhance exploration while preserving structural efficiency. Extensive experiments on the CW10-v1 Continual World benchmark demonstrate that SSDE achieves state-of-the-art performance, reaching a success rate of 95%, surpassing prior methods significantly in both plasticity and stability trade-offs (code is available at: https://github.com/chengqiArchy/SSDE).
Position: Standard Benchmarks Fail -- LLM Agents Present Overlooked Risks for Financial Applications
Feb 21, 2025Current financial LLM agent benchmarks are inadequate. They prioritize task performance while ignoring fundamental safety risks. Threats like hallucinations, temporal misalignment, and adversarial vulnerabilities pose systemic risks in high-stakes financial environments, yet existing evaluation frameworks fail to capture these risks. We take a firm position: traditional benchmarks are insufficient to ensure the reliability of LLM agents in finance. To address this, we analyze existing financial LLM agent benchmarks, finding safety gaps and introducing ten risk-aware evaluation metrics. Through an empirical evaluation of both API-based and open-weight LLM agents, we reveal hidden vulnerabilities that remain undetected by conventional assessments. To move the field forward, we propose the Safety-Aware Evaluation Agent (SAEA), grounded in a three-level evaluation framework that assesses agents at the model level (intrinsic capabilities), workflow level (multi-step process reliability), and system level (integration robustness). Our findings highlight the urgent need to redefine LLM agent evaluation standards by shifting the focus from raw performance to safety, robustness, and real world resilience.
State Chrono Representation for Enhancing Generalization in Reinforcement Learning
Nov 09, 2024



In reinforcement learning with image-based inputs, it is crucial to establish a robust and generalizable state representation. Recent advancements in metric learning, such as deep bisimulation metric approaches, have shown promising results in learning structured low-dimensional representation space from pixel observations, where the distance between states is measured based on task-relevant features. However, these approaches face challenges in demanding generalization tasks and scenarios with non-informative rewards. This is because they fail to capture sufficient long-term information in the learned representations. To address these challenges, we propose a novel State Chrono Representation (SCR) approach. SCR augments state metric-based representations by incorporating extensive temporal information into the update step of bisimulation metric learning. It learns state distances within a temporal framework that considers both future dynamics and cumulative rewards over current and long-term future states. Our learning strategy effectively incorporates future behavioral information into the representation space without introducing a significant number of additional parameters for modeling dynamics. Extensive experiments conducted in DeepMind Control and Meta-World environments demonstrate that SCR achieves better performance comparing to other recent metric-based methods in demanding generalization tasks. The codes of SCR are available in https://github.com/jianda-chen/SCR.
Improving the Generalization of Unseen Crowd Behaviors for Reinforcement Learning based Local Motion Planners
Oct 16, 2024



Deploying a safe mobile robot policy in scenarios with human pedestrians is challenging due to their unpredictable movements. Current Reinforcement Learning-based motion planners rely on a single policy to simulate pedestrian movements and could suffer from the over-fitting issue. Alternatively, framing the collision avoidance problem as a multi-agent framework, where agents generate dynamic movements while learning to reach their goals, can lead to conflicts with human pedestrians due to their homogeneity. To tackle this problem, we introduce an efficient method that enhances agent diversity within a single policy by maximizing an information-theoretic objective. This diversity enriches each agent's experiences, improving its adaptability to unseen crowd behaviors. In assessing an agent's robustness against unseen crowds, we propose diverse scenarios inspired by pedestrian crowd behaviors. Our behavior-conditioned policies outperform existing works in these challenging scenes, reducing potential collisions without additional time or travel.
Off-dynamics Conditional Diffusion Planners
Oct 16, 2024

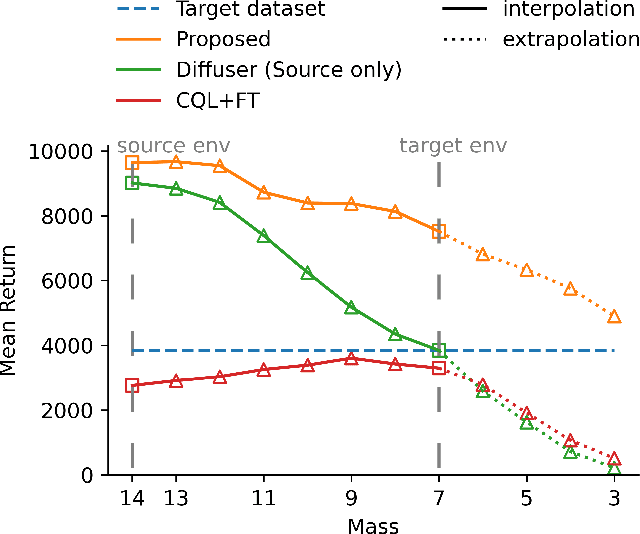
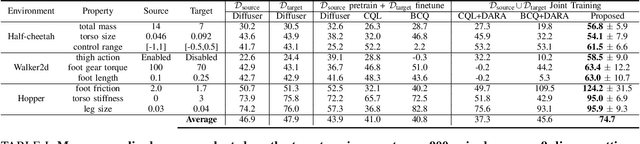
Offline Reinforcement Learning (RL) offers an attractive alternative to interactive data acquisition by leveraging pre-existing datasets. However, its effectiveness hinges on the quantity and quality of the data samples. This work explores the use of more readily available, albeit off-dynamics datasets, to address the challenge of data scarcity in Offline RL. We propose a novel approach using conditional Diffusion Probabilistic Models (DPMs) to learn the joint distribution of the large-scale off-dynamics dataset and the limited target dataset. To enable the model to capture the underlying dynamics structure, we introduce two contexts for the conditional model: (1) a continuous dynamics score allows for partial overlap between trajectories from both datasets, providing the model with richer information; (2) an inverse-dynamics context guides the model to generate trajectories that adhere to the target environment's dynamic constraints. Empirical results demonstrate that our method significantly outperforms several strong baselines. Ablation studies further reveal the critical role of each dynamics context. Additionally, our model demonstrates that by modifying the context, we can interpolate between source and target dynamics, making it more robust to subtle shifts in the environment.
Large Language Models Know What Makes Exemplary Contexts
Aug 14, 2024



In-context learning (ICL) has proven to be a significant capability with the advancement of Large Language models (LLMs). By instructing LLMs using few-shot demonstrative examples, ICL enables them to perform a wide range of tasks without needing to update millions of parameters. This paper presents a unified framework for LLMs that allows them to self-select influential in-context examples to compose their contexts; self-rank candidates with different demonstration compositions; self-optimize the demonstration selection and ordering through reinforcement learning. Specifically, our method designs a parameter-efficient retrieval head that generates the optimized demonstration after training with rewards from LLM's own preference. Experimental results validate the proposed method's effectiveness in enhancing ICL performance. Additionally, our approach effectively identifies and selects the most representative examples for the current task, and includes more diversity in retrieval.
XplainLLM: A QA Explanation Dataset for Understanding LLM Decision-Making
Nov 15, 2023Large Language Models (LLMs) have recently made impressive strides in natural language understanding tasks. Despite their remarkable performance, understanding their decision-making process remains a big challenge. In this paper, we look into bringing some transparency to this process by introducing a new explanation dataset for question answering (QA) tasks that integrates knowledge graphs (KGs) in a novel way. Our dataset includes 12,102 question-answer-explanation (QAE) triples. Each explanation in the dataset links the LLM's reasoning to entities and relations in the KGs. The explanation component includes a why-choose explanation, a why-not-choose explanation, and a set of reason-elements that underlie the LLM's decision. We leverage KGs and graph attention networks (GAT) to find the reason-elements and transform them into why-choose and why-not-choose explanations that are comprehensible to humans. Through quantitative and qualitative evaluations, we demonstrate the potential of our dataset to improve the in-context learning of LLMs, and enhance their interpretability and explainability. Our work contributes to the field of explainable AI by enabling a deeper understanding of the LLMs decision-making process to make them more transparent and thereby, potentially more reliable, to researchers and practitioners alike. Our dataset is available at: https://github.com/chen-zichen/XplainLLM_dataset.git